


-
Book Overview & Buying

-
Table Of Contents

Distributed Machine Learning with Python
By :
Distributed Machine Learning with Python
By:
Overview of this book
Reducing time cost in machine learning leads to a shorter waiting time for model training and a faster model updating cycle. Distributed machine learning enables machine learning practitioners to shorten model training and inference time by orders of magnitude. With the help of this practical guide, you'll be able to put your Python development knowledge to work to get up and running with the implementation of distributed machine learning, including multi-node machine learning systems, in no time. You'll begin by exploring how distributed systems work in the machine learning area and how distributed machine learning is applied to state-of-the-art deep learning models. As you advance, you'll see how to use distributed systems to enhance machine learning model training and serving speed. You'll also get to grips with applying data parallel and model parallel approaches before optimizing the in-parallel model training and serving pipeline in local clusters or cloud environments. By the end of this book, you'll have gained the knowledge and skills needed to build and deploy an efficient data processing pipeline for machine learning model training and inference in a distributed manner.
Table of Contents (17 chapters)
Preface

Section 1 – Data Parallelism
 Free Chapter
Free Chapter
Chapter 1: Splitting Input Data
Chapter 2: Parameter Server and All-Reduce
Chapter 3: Building a Data Parallel Training and Serving Pipeline
Chapter 4: Bottlenecks and Solutions
Section 2 – Model Parallelism
Chapter 5: Splitting the Model
Chapter 6: Pipeline Input and Layer Split
Chapter 7: Implementing Model Parallel Training and Serving Workflows
Chapter 8: Achieving Higher Throughput and Lower Latency
Section 3 – Advanced Parallelism Paradigms
Chapter 9: A Hybrid of Data and Model Parallelism
Chapter 10: Federated Learning and Edge Devices
Chapter 11: Elastic Model Training and Serving
Chapter 12: Advanced Techniques for Further Speed-Ups
Other Books You May Enjoy
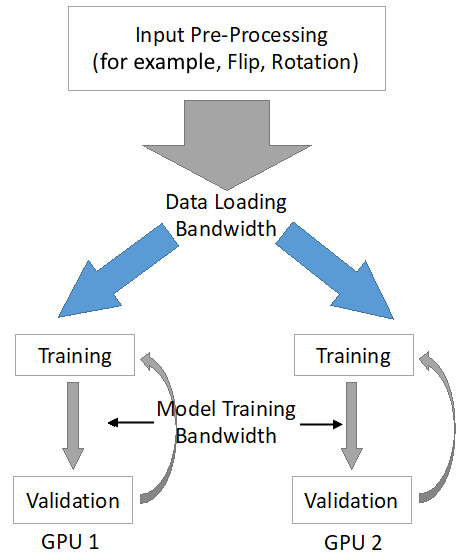
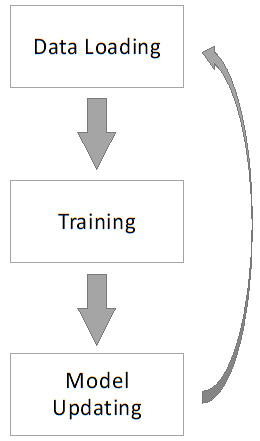
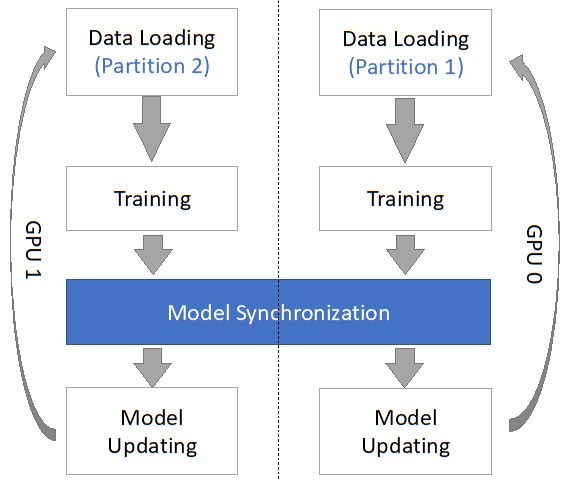
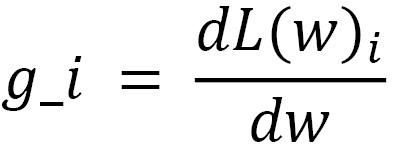
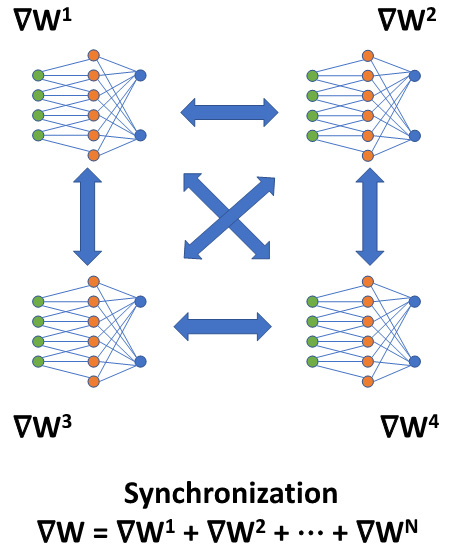
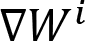 , where i refers to the i-th GPU. Given that they are training on different local training inputs, all the gradients from different GPUs may be different. To guarantee that all four GPUs have the same model updates, we need to conduct model synchronization before the model parameter updates:
, where i refers to the i-th GPU. Given that they are training on different local training inputs, all the gradients from different GPUs may be different. To guarantee that all four GPUs have the same model updates, we need to conduct model synchronization before the model parameter updates: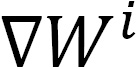
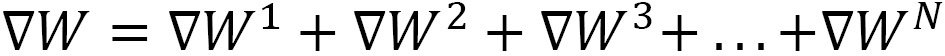
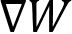 , locally on each GPU. Then, we can use these aggregated gradients,
, locally on each GPU. Then, we can use these aggregated gradients, 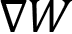 , for the model updates, which guarantees that the updated model parameters remain the same after this first data parallel training iteration.
, for the model updates, which guarantees that the updated model parameters remain the same after this first data parallel training iteration. 






