-
Book Overview & Buying

-
Table Of Contents

Alteryx Designer Cookbook
By :
Alteryx Designer Cookbook
By:
Overview of this book
Alteryx allows you to create data manipulation and analytic workflows with a simple, easy-to-use, code-free UI, and perform fast-executing workflows, offering multiple ways to achieve the same results. The Alteryx Designer Cookbook is a comprehensive guide to maximizing your Alteryx skills and determining the best ways to perform data operations
This book's recipes will guide you through an analyst's complete journey, covering all aspects of the data life cycle. The first set of chapters will teach you how to read data from various sources to obtain reports and pass it through the required adjustment operations for analysis. After an explanation of the Alteryx platform components with a particular focus on Alteryx Designer, you’ll be taken on a tour of what and how you can accomplish by using this tool. Along the way, you’ll learn best practices and design patterns. The book also covers real-world examples to help you apply your understanding of the features in Alteryx to practical scenarios
By the end of this book, you’ll have enhanced your proficiency with Alteryx Designer and an improved ability to execute tasks within the tool efficiently
Table of Contents (17 chapters)
Preface

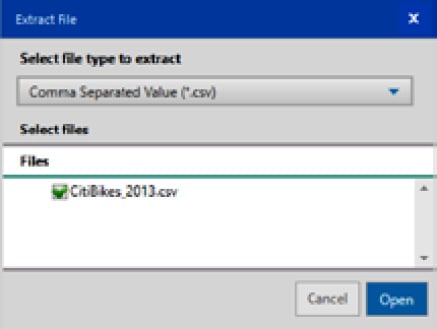
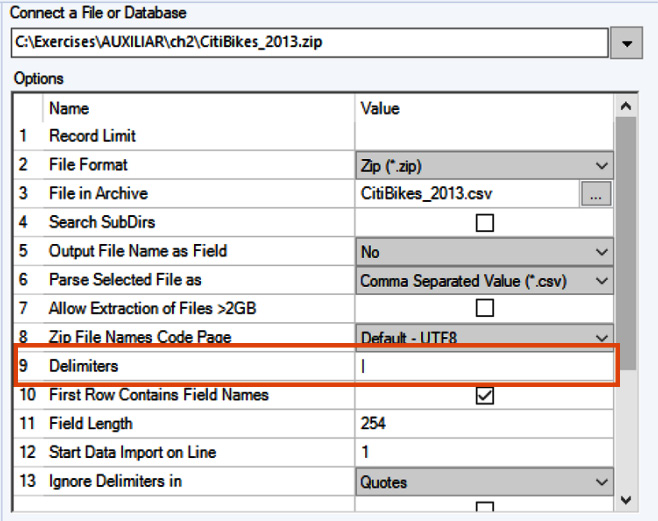
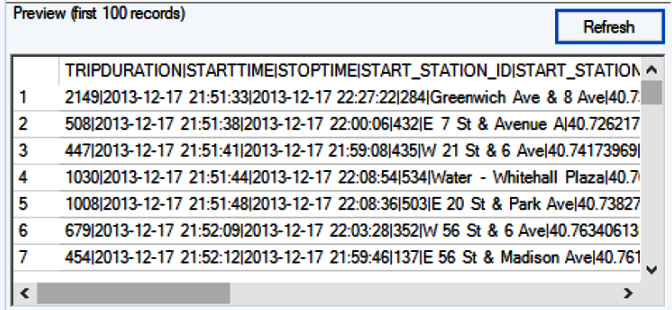
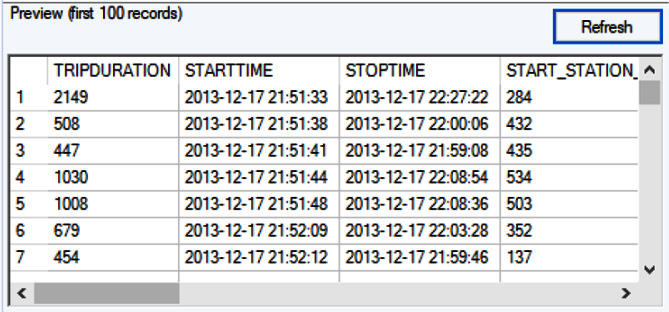
Chapter 1: Inputting Data from Files
 Free Chapter
Free Chapter
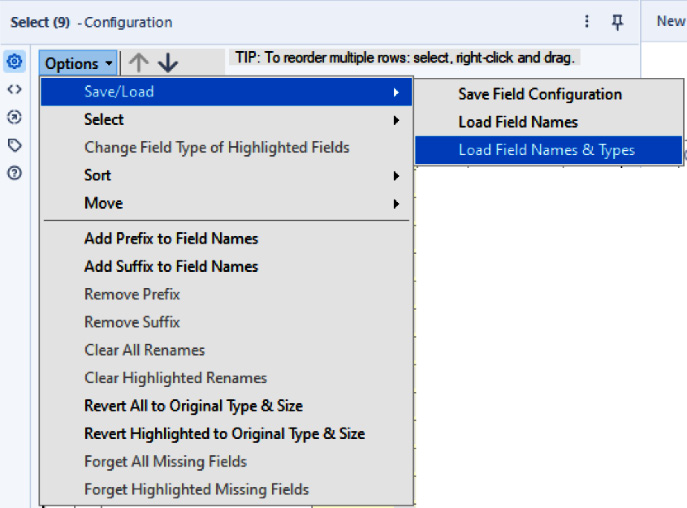
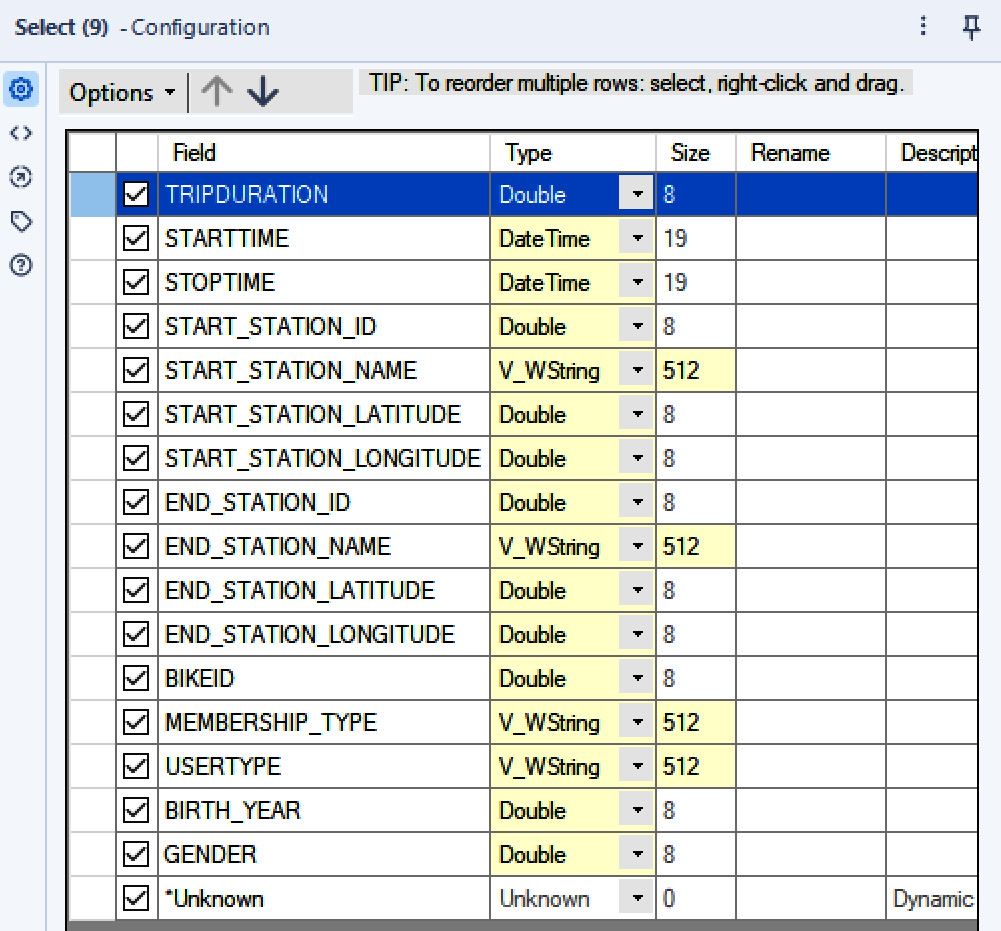
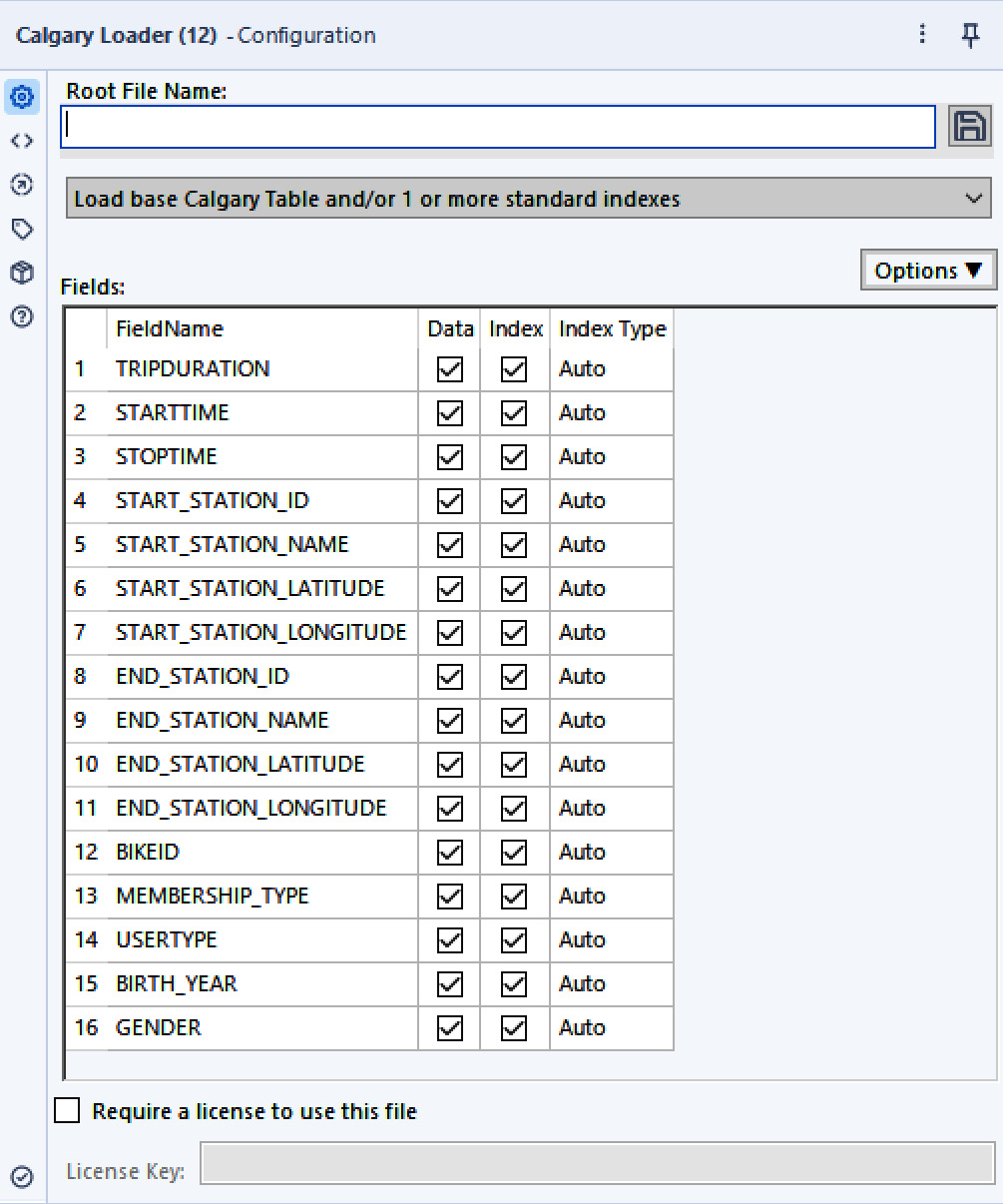
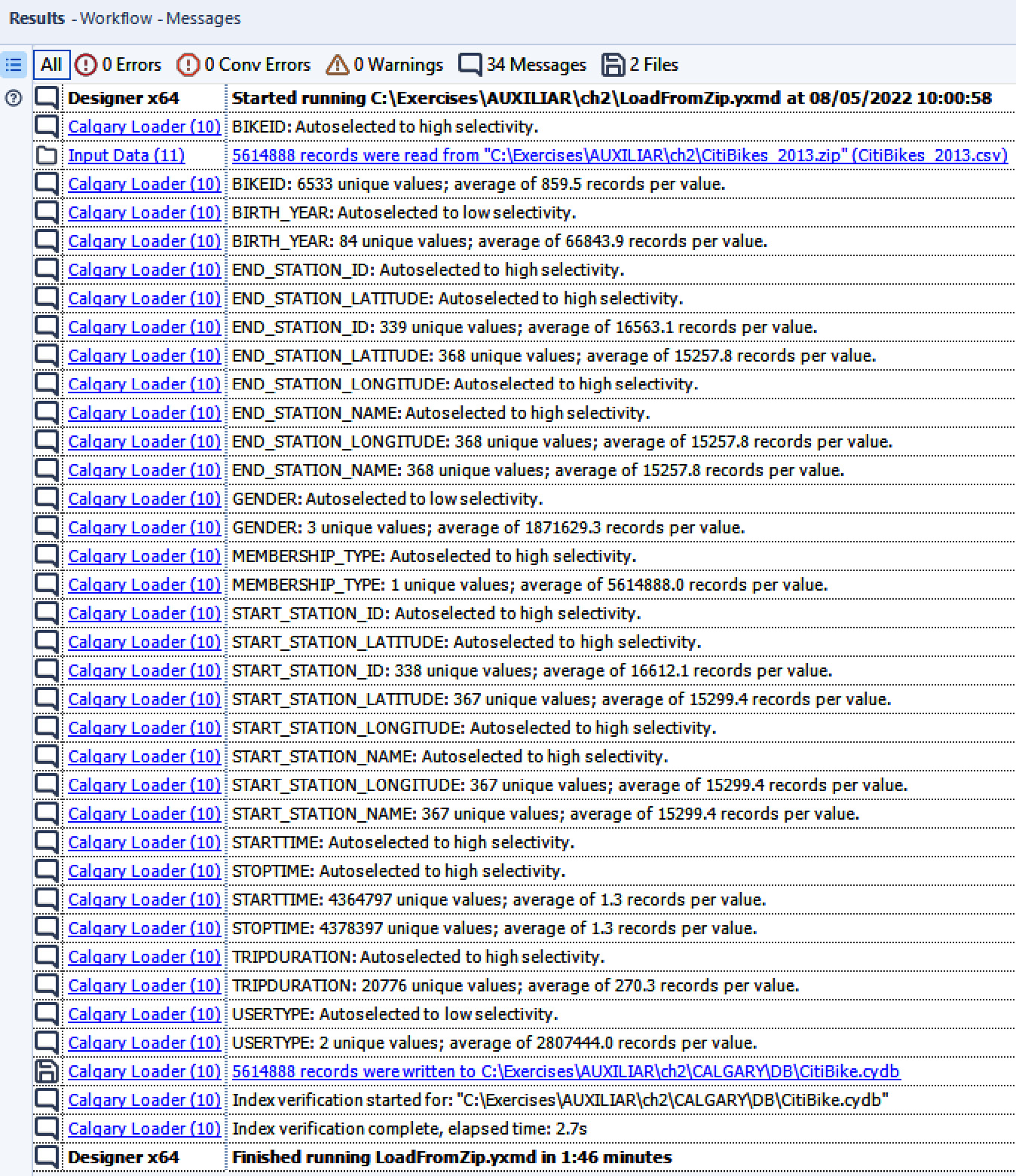
Chapter 2: Working with Databases
Chapter 3: Preparing Data
Chapter 4: Transforming Data
Chapter 5: Data Parsing
Chapter 6: Grouping Data
Chapter 7: Blending and Merging Datasets
Chapter 8: Aggregating Data
Chapter 9: Dynamic Operations
Chapter 10: Macros and Apps
Chapter 11: Downloads, APIs, and Web Services
Chapter 12: Developer Tools
Chapter 13: Reporting with Alteryx
Chapter 14: Outputting Data
Index