

Lists, Sets, Strings, Tuples, and Dictionaries
Now that we have touched upon a few advantages of using Python, we will start by exploring various basic data structures in Python. We will also learn about a few techniques we can use to handle these data structures. This is invaluable for a data practitioner.
Lists
Lists are fundamental Python data structures that have continuous memory locations and can host different data types (such as strings, numbers, floats, and doubles) and can be accessed by the index.
We will start with a list and list comprehension. A list comprehension is a syntactic sugar (or shorthand) for a for loop, which iterates over a list. We will generate a list of numbers, and then examine which ones among them are even. We will sort, reverse, and check for duplicates. We will also see the different ways we can access the list elements, iterating over them and checking the membership of an element.
The following is an example of a simple list:
list_example = [51, 27, 34, 46, 90, 45, -19]
The following is also an example of a list:
list_example2 = [15, "Yellow car", True, 9.456, [12, "Hello"]]
As you can see, a list can contain any number of the allowed data types, such as int, float, string, and boolean, and a list can also be a mix of different data types (including nested lists).
If you are coming from a strongly typed language, such as C, C++, or Java, then this will probably be strange as you are not allowed to mix different kinds of data types in a single array in those languages. Lists in Python are loosely typed, that is, they are not restricted to a single type. Lists are somewhat like arrays in the sense that they are both based on continuous memory locations and can be accessed using indexes. But the power of Python lists comes from the fact that they can host different data types and you are allowed to manipulate the data.
In Python, there is a concept of creating a slice of a list. Here is the syntax:
my_list [ inclusive start index : exclusive end index ]
Known as list slicing, this returns a smaller list from the original list by extracting only a part of it. To slice a list, we need two integers. The first integer will denote the start of the slice and the second integer will denote the end. Notice that slicing does not include the third index or the end element. A slice is a chunk of the list tuple or string. The range is from 0 to 1 minus the total length. The first number given represents the first position to include in the slice. The second number is used to indicate which place you want to stop at, but not include. A slice can have an index of –1 to indicate the last element.
The indices will be automatically assigned, as follows:
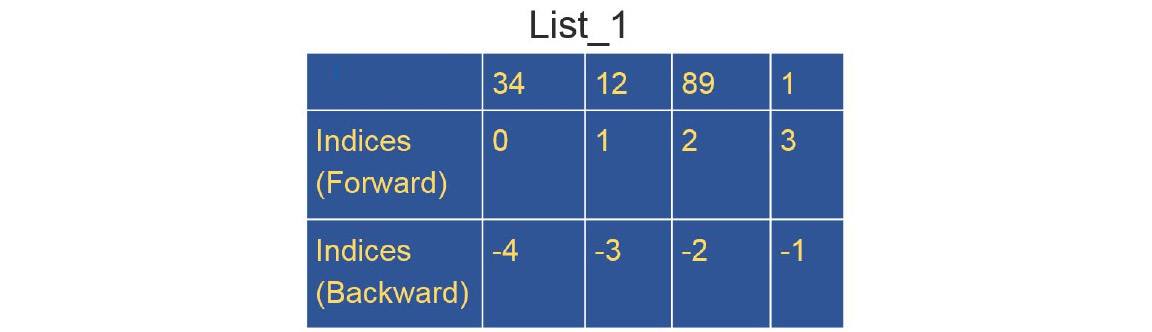
Figure 1.3: List showing the forward and backward indices
Note
Be careful, though, as the very power of lists, and the fact that you can mix different data types in a single list, can actually create subtle bugs that can be very difficult to track.