

The kernel locking API and shared objects
A resource is said to be shared when it can be accessed by several contenders, regardless of their exclusively. When they are exclusive, access must be synchronized so that only the allowed contender(s) may own the resource. Such resources might be memory locations or peripheral devices, while the contenders might be processors, processes, or threads. Operating systems perform mutual exclusion by atomically (that is, by means of an operation that can be interrupted) modifying a variable that holds the current state of the resource, making this visible to all contenders that might access the variable at the same time. This atomicity guarantees that the modification will either be successful, or not successful at all. Nowadays, modern operating systems rely on the hardware (which should allow atomic operations) used for implementing synchronization, though a simple system may ensure atomicity by disabling interrupts (and avoiding scheduling) around the critical code section.
In this section, we’ll describe the following two synchronization mechanisms:
- Locks: Used for mutual exclusion. When one contender holds the lock, no other contender can hold it (others are excluded). The most well-known locking primitives in the kernel are spinlocks and mutexes.
- Conditional variables: Mostly used to sense or wait for a state change. These are implemented differently in the kernel, as we will see later, mainly in the Waiting, sensing, and blocking in the Linux kernel section.
When it comes to locking, it is up to the hardware to allow such synchronizations by means of atomic operations. The kernel then uses these to implement locking facilities. Synchronization primitives are data structures that are used for coordinating access to shared resources. Because only one contender can hold the lock (and thus access the shared resource), it might perform an arbitrary operation on the resource associated with the lock that would appear to be atomic to others.
Apart from dealing with the exclusive ownership of a given shared resource, there are situations where it is better to wait for the state of the resource to change; for example, waiting for a list to contain at least one object (its state then passes from empty to not empty) or for a task to complete (a DMA transaction, for example). The Linux kernel does not implement conditional variables. From our user space, we could think of using a conditional variable for both situations, but to achieve the same or even better, the kernel provides the following mechanisms:
- Wait queue: Mainly used to wait for a state change. It’s designed to work in concert with locks.
- Completion queue: Used to wait for a given computation to complete.
Both mechanisms are supported by the Linux kernel and are exposed to drivers thanks to a reduced set of APIs (which significantly ease their use when used by a developer). We will discuss these in the upcoming sections.
Spinlocks
A spinlock is a hardware-based locking primitive. It depends on the capabilities of the hardware at hand to provide atomic operations (such as test_and_set, which, in a non-atomic implementation, would result in read, modify, and write operations). Spinlocks are essentially used in an atomic context where sleeping is not allowed or simply not needed (in interrupts, for example, or when you want to disable preemption), but also as an inter-CPU locking primitive.
It is the simplest locking primitive and also the base one. It works as follows:
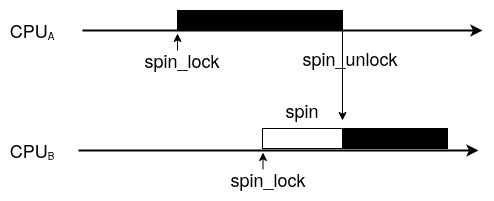
Figure 1.1 – Spinlock contention flow
Let’s explore the diagram by looking at the following scenario:When CPUB, which is running task B, wants to acquire the spinlock thanks to the spinlock’s locking function and this spinlock is already held by another CPU (let’s say CPUA, running task A, which has already called this spinlock’s locking function), then CPUB will simply spin around a while loop, thus blocking task B until the other CPU releases the lock (task A calls the spinlock’s release function). This spinning will only happen on multi-core machines, which is why the use case described previously, which involves more than one CPU since it’s on a single core machine, cannot happen: the task either holds a spinlock and proceeds or doesn’t run until the lock is released. I used to say that a spinlock is a lock held by a CPU, which is the opposite of a mutex (we will discuss this in the next section), which is a lock held by a task. A spinlock operates by disabling the scheduler on the local CPU (that is, the CPU running the task that called the spinlock’s locking API). This also means that the task currently running on that CPU cannot be preempted by another task, except for IRQs if they are not disabled (more on this later). In other words, spinlocks protect resources that only one CPU can take/access at a time. This makes spinlocks suitable for SMP safety and for executing atomic tasks.
Important note
Spinlocks are not the only implementation that take advantage of hardware’s atomic functions. In the Linux kernel, for example, the preemption status depends on a per-CPU variable that, if equal to 0, means preemption is enabled. However, if it’s greater than 0, this means preemption is disabled (schedule() becomes inoperative). Thus, disabling preemption (preempt_disable()) consists of adding 1 to the current per-CPU variable (preempt_count actually), while preempt_enable() subtracts 1 (one) from the variable, checks whether the new value is 0, and calls schedule(). These addition/subtraction operations should then be atomic, and thus rely on the CPU being able to provide atomic addition/subtraction functions.
There are two ways to create and initialize a spinlock: either statically using the DEFINE_SPINLOCK macro, which will declare and initialize the spinlock, or dynamically by calling spin_lock_init() on an uninitialized spinlock.
First, we’ll introduce how to use the DEFINE_SPINLOCK macro. To understand how this works, we must look at the definition of this macro in include/linux/spinlock_types.h, which is as follows:
#define DEFINE_SPINLOCK(x) spinlock_t x = __SPIN_LOCK_UNLOCKED(x)
This can be used as follows:
static DEFINE_SPINLOCK(foo_lock)
After this, the spinlock will be accessible through its name, foo_lock. Note that its address would be &foo_lock. However, for dynamic (runtime) allocation, you need to embed the spinlock into a bigger structure, allocate memory for this structure, and then call spin_lock_init() on the spinlock element:
struct bigger_struct { spinlock_t lock; unsigned int foo; [...]};
static struct bigger_struct *fake_alloc_init_function(){ struct bigger_struct *bs; bs = kmalloc(sizeof(struct bigger_struct), GFP_KERNEL); if (!bs) return -ENOMEM; spin_lock_init(&bs->lock); return bs;}
It is better to use DEFINE_SPINLOCK whenever possible. It offers compile-time initialization and requires less lines of code with no real drawback. At this stage, we can lock/unlock the spinlock using the spin_lock() and spin_unlock() inline functions, both of which are defined in include/linux/spinlock.h:
void spin_unlock(spinlock_t *lock) void spin_lock(spinlock_t *lock)
That being said, there are some limitations to using spinlocks this way. Though a spinlock prevents preemption on the local CPU, it does not prevent this CPU from being hogged by an interrupt (thus, executing this interrupt’s handler). Imagine a situation where the CPU holds a “spinlock” in order to protect a given resource and an interrupt occurs. The CPU will stop its current task and branch out to this interrupt handler. So far, so good. Now, imagine that this IRQ handler needs to acquire this same spinlock (you’ve probably already guessed that the resource is shared with the interrupt handler). It will infinitely spin in place, trying to acquire a lock that’s already been locked by a task that it has preempted. This situation is known as a deadlock.
To address this issue, the Linux kernel provides _irq variant functions for spinlocks, which, in addition to disabling/enabling the preemption, also disable/enable interrupts on the local CPU. These functions are spin_lock_irq() and spin_unlock_irq(), and they are defined as follows:
void spin_unlock_irq(spinlock_t *lock); void spin_lock_irq(spinlock_t *lock);
You might think that this solution is sufficient, but it is not. The _irq variant partially solves this problem. Imagine that interrupts are already disabled on the processor before your code starts locking. So, when you call spin_unlock_irq(), you will not just release the lock, but also enable interrupts. However, this will probably happen in an erroneous manner since there is no way for spin_unlock_irq() to know which interrupts were enabled before locking and which weren’t.
The following is a short example of this:
- Let’s say interrupts x and y were disabled before a spinlock was acquired, while z was not.
spin_lock_irq()will disable the interrupts (x, y, and z are now disabled) and take the lock.spin_unlock_irq()will enable the interrupts. x, y, and z will all be enabled, which was not the case before the lock was acquired. This is where the problem arises.
This makes spin_lock_irq() unsafe when it’s called from IRQs that are off-context as its counterpart, spin_unlock_irq(), will naively enable IRQs with the risk of enabling those that were not enabled while spin_lock_irq() was invoked. It only makes sense to use spin_lock_irq()when you know that interrupts are enabled; that is, you are sure nothing else might have disabled interrupts on the local CPU.
Now, imagine that you save the status of your interrupts in a variable before acquiring the lock and restoring them to how they were while they were releasing. In this situation, there would be no more issues. To achieve this, the kernel provides _irqsave variant functions. These behave just like the _irq ones, while also saving and restoring the interrupts status feature. These functions are spin_lock_irqsave() and spin_lock_irqrestore(), and they are defined as follows:
spin_lock_irqsave(spinlock_t *lock, unsigned long flags) spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags)
Important note
spin_lock() and all its variants automatically call preempt_disable(), which disables preemption on the local CPU. On the other hand, spin_unlock() and its variants call preempt_enable(), which try to enable (yes, try! – it depends on whether other spinlocks are locked, which would affect the value of the preemption counter) preemption, and which internally call schedule() if enabled (depending on the current value of the counter, which should be 0). spin_unlock() is then a preemption point and might reenable preemption.
Disabling interrupts versus only disabling preemption
Though disabling interrupts may prevent kernel preemption (a scheduler’s timer interrupts would be disabled), nothing prevents the protected section from invoking the scheduler (the schedule() function). Lots of kernel functions indirectly invoke the scheduler, such as those that deal with spinlocks. As a result, even a simple printk() function may invoke the scheduler since it deals with the spinlock that protects the kernel message buffer. The kernel disables or enables the scheduler (performs preemption) by increasing or decreasing a kernel-global and per-CPU variable (that defaults to 0, meaning “enabled”) called preempt_count. When this variable is greater than 0 (which is checked by the schedule() function), the scheduler simply returns and does nothing. Every time a spin_lock*-related helper gets invoked, this variable is increased by 1. On the other hand, releasing a spinlock (any spin_unlock* family function) decreases it by 1, and whenever it reaches 0, the scheduler is invoked, meaning that your critical section would not be very atomic.
Thus, if your code does not trigger preemption itself, it can only be protected from preemption by disabling interrupts. That being said, code that’s locked a spinlock may not sleep as there would be no way to wake it up (remember, timer interrupts and schedulers are disabled on the local CPU).
Now that we are familiar with the spinlock and its subtilities, let’s look at the mutex, which is our second locking primitive.
Mutexes
The mutex is the other locking primitive we will discuss in this chapter. It behaves just like the spinlock, with the only difference being that your code can sleep. If you try to lock a mutex that is already held by another task, your task will find itself suspended, and it will only be woken when the mutex is released. There’s no spinning this time, which means that the CPU can process something else while your task is waiting. As I mentioned previously, a spinlock is a lock held by a CPU, while a mutex is a lock held by a task.
A mutex is a simple data structure that embeds a wait queue (to put contenders to sleep), while a spinlock protects access to this wait queue. The following is what struct mutex looks like:
struct mutex {
atomic_long_t owner;
spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
struct list_head wait_list;
[...]
};
In the preceding code, the elements that are only used in debugging mode have been removed for the sake of readability. However, as you can see, mutexes are built on top of spinlocks. owner represents the process that actually owns (hold) the lock. wait_list is the list in which the mutex’s contenders are put to sleep. wait_lock is the spinlock that protects wait_list while contenders are inserted and are put to sleep. This helps keep wait_list coherent on SMP systems.
The mutex APIs can be found in the include/linux/mutex.h header file. Prior to acquiring and releasing a mutex, it must be initialized. As for other kernel core data structures, there may be a static initialization, as follows:
static DEFINE_MUTEX(my_mutex);
The following is the definition of the DEFINE_MUTEX() macro:
#define DEFINE_MUTEX(mutexname) \ struct mutex mutexname = __MUTEX_INITIALIZER(mutexname)
The second approach the kernel offers is dynamic initialization. This can be done by making a call to the low-level __mutex_init() function, which is actually wrapped by a much more user-friendly macro known as mutex_init():
struct fake_data {
struct i2c_client *client;
u16 reg_conf;
struct mutex mutex;
};
static int fake_probe(struct i2c_client *client, const struct i2c_device_id *id)
{
[...]
mutex_init(&data->mutex);
[...]
}
Acquiring (also known as locking) a mutex is as simple calling one of the following three functions:
void mutex_lock(struct mutex *lock); int mutex_lock_interruptible(struct mutex *lock); int mutex_lock_killable(struct mutex *lock);
If the mutex is free (unlocked), your task will immediately acquire it without going to sleep. Otherwise, your task will be put to sleep in a manner that depends on the locking function you use. With mutex_lock(), your task will be put in an uninterruptible sleep (TASK_UNINTERRUPTIBLE) while you wait for the mutex to be released (in case it is held by another task). mutex_lock_interruptible() will put your task in an interruptible sleep, in which the sleep can be interrupted by any signal. mutex_lock_killable() will allow your task’s sleep to be interrupted, but only by signals that actually kill the task. Both functions return zero if the lock has been acquired successfully. Moreover, interruptible variants return -EINTR when the locking attempt is interrupted by a signal.
Whatever locking function is used, the mutex owner (and only the owner) should release the mutex using mutex_unlock(), which is defined as follows:
void mutex_unlock(struct mutex *lock);
If you wish to check the status of your mutex, you can use mutex_is_locked():
static bool mutex_is_locked(struct mutex *lock)
This function simply checks whether the mutex owner is NULL and returns true if it is, or false otherwise.
Important note
It is only recommended to use mutex_lock()when you can guarantee that the mutex will not be held for a long time. Typically, you should use the interruptible variant instead.
There are specific rules when using mutexes. The most important are enumerated in the kernel’s mutex API header file, include/linux/mutex.h. The following is an excerpt from it:
* - only one task can hold the mutex at a time * - only the owner can unlock the mutex * - multiple unlocks are not permitted * - recursive locking is not permitted * - a mutex object must be initialized via the API * - a mutex object must not be initialized via memset or copying * - task may not exit with mutex held * - memory areas where held locks reside must not be freed * - held mutexes must not be reinitialized * - mutexes may not be used in hardware or software interrupt * contexts such as tasklets and timers
The full version can be found in the same file.
Now, let’s look at some cases where we can avoid putting the mutex to sleep while it is being held. This is known as the try-lock method.
The try-lock method
There are cases where we may need to acquire the lock if it is not already held by another elsewhere. Such methods try to acquire the lock and immediately (without spinning if we are using a spinlock, nor sleeping if we are using a mutex) return a status value. This tells us whether the lock has been successfully locked. They can be used if we do not need to access the data that’s being protected by the lock when some other thread is holding the lock.
Both the spinlock and mutex APIs provide a try-lock method. They are called spin_trylock() and mutex_trylock(), respectively. Both methods return 0 on a failure (the lock is already locked) or 1 on a success (lock acquired). Thus, it makes sense to use these functions along with an statement:
int mutex_trylock(struct mutex *lock)
spin_trylock() actually targets spinlocks. It will lock the spinlock if it is not already locked in the same way that the spin_lock() method is. However, it immediately returns 0 without spinning if the spinlock is already locked:
static DEFINE_SPINLOCK(foo_lock);[...]static void foo(void){[...]if (!spin_trylock(&foo_lock)) { /* Failure! the spinlock is already locked */ [...] return; }/* * reaching this part of the code means that the * spinlock has been successfully locked */[...]spin_unlock(&foo_lock);[...]}
On the other hand, mutex_trylock() targets mutexes. It will lock the mutex if it is not already locked in the same way that the mutex_lock() method is. However, it immediately returns 0 without sleeping if the mutex is already locked. The following is an example of this:
static DEFINE_MUTEX(bar_mutex);[...]
static void bar (void){
[...] if (!mutex_trylock(&bar_mutex)) /* Failure! the mutex is already locked */ [...] return; }
/* * reaching this part of the code means that the mutex has * been successfully locked */
[...] mutex_unlock(&bar_mutex);[...]
}
In the preceding code, the try-lock is being used along with the if statement so that the driver can adapt its behavior.
Waiting, sensing, and blocking in the Linux kernel
This section could have been named kernel sleeping mechanism as the mechanisms we will deal with involve putting the processes involved to sleep. A device driver, during its life cycle, can initiate completely separate tasks, some of which depend on the completion of others. The Linux kernel addresses such dependencies with struct completion items. On the other hand, it may be necessary to wait for a particular condition to become true or the state of an object to change. This time, the kernel provides work queues to address this situation.
Waiting for completion or a state change
You may not necessarily be waiting exclusively for a resource, but for the state of a given object (shared or not) to change or for a task to complete. In kernel programming practices, it is common to initiate an activity outside the current thread, and then wait for that activity to complete. Completion is a good alternative to sleep() when you’re waiting for a buffer to be used, for example. It is suitable for sensing data, as is the case with DMA transfers. Working with completions requires including the <linux/completion.h> header. Its structure looks as follows:
struct completion {unsigned int done;wait_queue_head_t wait;};
You can create instances of the struct completion structure either statically using the static DECLARE_COMPLETION(my_comp) function or dynamically by wrapping the completion structure into a dynamic (allocated on the heap, which will be alive for the lifetime of the function/driver) data structure and invoking init_completion(&dynamic_object->my_comp). When the device driver performs some work (a DMA transaction, for example) and others (threads, for example) need to be notified of their completion, the waiter has to call wait_for_completion() on the previously initialized struct completion object in order to be notified of this:
void wait_for_completion(struct completion *comp);
When the other part of the code has decided that the work has been completed (the transaction has been completed, in the case of DMA), it can wake up anyone (the code that needs to access the DMA buffer) who is waiting by either calling complete(), which will only wake one waiting process, or complete_all(), which will wake everyone waiting for this to complete:
void complete(struct completion *comp); void complete_all(struct completion *comp);
A typical usage scenario is as follows (this excerpt has been taken from the kernel documentation):
CPU#1 CPU#2 struct completion setup_done; init_completion(&setup_done); initialize_work(...,&setup_done,...); /* run non-dependent code */ /* do some setup */ [...] [...] wait_for_completion(&setup_done); complete(setup_done);
The order in which wait_for_completion() and complete() are called does not matter. As semaphores, the completions API is designed so that they will work properly, even if complete() is called before wait_for_completion(). In such a case, the waiter will simply continue immediately once all the dependencies have been satisfied.
Note that wait_for_completion() will invoke spin_lock_irq() and spin_unlock_irq(), which, according to the Spinlocks section, are not recommended to be used from within an interrupt handler or with disabled IRQs. This is because it would result in spurious interrupts being enabled, which are hard to detect. Additionally, by default, wait_for_completion() marks the task as uninterruptible (TASK_UNINTERRUPTIBLE), making it unresponsive to any external signal (even kill). This may block for a long time, depending on the nature of the activity it’s waiting for.
You may need the wait not to be done in an uninterruptible state, or at least you may need the wait being able to be interrupted either by any signal or only by signals that kill the process. The kernel provides the following APIs:
wait_for_completion_interruptible()wait_for_completion_interruptible_timeout()wait_for_completion_killable()wait_for_completion_killable_timeout()
_killable variants will mark the task as TASK_KILLABLE, thus only making it responsive to signals that actually kill it, while _interruptible variants mark the task as TASK_INTERRUPTIBLE, allowing it to be interrupted by any signal. _timeout variants will, at most, wait for the specified timeout:
int wait_for_completion_interruptible(struct completion *done) long wait_for_completion_interruptible_timeout( struct completion *done, unsigned long timeout) long wait_for_completion_killable(struct completion *done) long wait_for_completion_killable_timeout( struct completion *done, unsigned long timeout)
Since wait_for_completion*() may sleep, it can only be used in this process context. Because the interruptible, killable, or timeout variant may return before the underlying job has run until completion, their return values should be checked carefully so that you can adopt the right behavior. The killable and interruptible variants return -ERESTARTSYS if they’re interrupted and 0 if they’ve been completed. On the other hand, the timeout variants will return -ERESTARTSYS if they’re interrupted, 0 if they’ve timed out, and the number of jiffies (at least 1) left until timeout if they’ve completed before timeout. Please refer to kernel/sched/completion.c in the kernel source for more on this, as well as more functions that will not be covered in this book.
On the other hand, complete() and complete_all() never sleep and internally call spin_lock_irqsave()/spin_unlock_irqrestore(), making completion signaling, from an IRQ context, completely safe.
Linux kernel wait queues
Wait queues are high-level mechanisms that are used to process block I/O, wait for particular conditions to be true, wait for a given event to occur, or to sense data or resource availability. To understand how they work, let’s have a look at the structure in include/linux/wait.h:
struct wait_queue_head {
spinlock_t lock;
struct list_head head;
};
A wait queue is nothing but a list (in which processes are put to sleep so that they can be awaken if some conditions are met) where there’s a spinlock to protect access to this list. You can use a wait queue when more than one process wants to sleep and you’re waiting for one or more events to occur so that it can be woke up. The head member is the list of processes waiting for the event(s). Each process that wants to sleep while waiting for the event to occur puts itself in this list before going to sleep. When a process is in the list, it is called a wait queue entry. When the event occurs, one or more processes on the list are woken up and moved off the list. We can declare and initialize a wait queue in two ways. First, we can declare and initialize it statically using DECLARE_WAIT_QUEUE_HEAD, as follows:
DECLARE_WAIT_QUEUE_HEAD(my_event);
We can also do this dynamically using init_waitqueue_head():
wait_queue_head_t my_event; init_waitqueue_head(&my_event);
Any process that wants to sleep while waiting for my_event to occur can invoke either wait_event_interruptible() or wait_event(). Most of the time, the event is just the fact that a resource has become available. Thus, it only makes sense for a process to go to sleep after the availability of that resource has been checked. To make things easy for you, these functions both take an expression in place of the second argument so that the process is only put to sleep if the expression evaluates to false:
wait_event(&my_event, (event_occurred == 1) ); /* or */ wait_event_interruptible(&my_event, (event_occurred == 1) );
wait_event() and wait_event_interruptible() simply evaluate the condition when it’s called. If the condition is false, the process is put into either a TASK_UNINTERRUPTIBLE or a TASK_INTERRUPTIBLE (for the _interruptible variant) state and removed from the running queue.
There may be cases where you need the condition to not only be true, but to time out after waiting a certain amount of time. You can address such cases using wait_event_timeout(), whose prototype is as follows:
wait_event_timeout(wq_head, condition, timeout)
This function has two behaviors, depending on the timeout having elapsed or not:
timeouthas elapsed: The function returns 0 if the condition is evaluated to false or 1 if it is evaluated to true.timeouthas not elapsed yet: The function returns the remaining time (in jiffies – must at least be 1) if the condition is evaluated to true.
The time unit for the timeout is jiffies. So that you don’t have to bother with seconds to jiffies conversion, you should use the msecs_to_jiffies() and usecs_to_jiffies() helpers, which convert milliseconds or microseconds into jiffies, respectively:
unsigned long msecs_to_jiffies(const unsigned int m) unsigned long usecs_to_jiffies(const unsigned int u)
After a change has been made to any variable that could mangle the result of the wait condition, you must call the appropriate wake_up* family function. That being said, in order to wake up a process sleeping on a wait queue, you should call either wake_up(), wake_up_all(), wake_up_interruptible(), or wake_up_interruptible_all(). Whenever you call any of these functions, the condition is reevaluated. If the condition is true at this time, then a process (or all the processes for the _all() variant) in wait queue will be awakened, and its (their) state will be set to TASK_RUNNING; otherwise (the condition is false), nothing will happen:
/* wakes up only one process from the wait queue. */ wake_up(&my_event); /* wakes up all the processes on the wait queue. */ wake_up_all(&my_event);: /* wakes up only one process from the wait queue that is in * interruptible sleep. */ wake_up_interruptible(&my_event) /* wakes up all the processes from the wait queue that * are in interruptible sleep. */ wake_up_interruptible_all(&my_event);
Since they can be interrupted by signals, you should check the return values of _interruptible variants. A non-zero value means your sleep has been interrupted by some sort of signal, so the driver should return ERESTARTSYS:
#include <linux/module.h>#include <linux/init.h>#include <linux/sched.h>#include <linux/time.h>#include <linux/delay.h>#include<linux/workqueue.h>
static DECLARE_WAIT_QUEUE_HEAD(my_wq);static int condition = 0;
/* declare a work queue*/static struct work_struct wrk;
static void work_handler(struct work_struct *work)
{
pr_info(“Waitqueue module handler %s\n”, __FUNCTION__);
msleep(5000);
pr_info(“Wake up the sleeping module\n”);
condition = 1;
wake_up_interruptible(&my_wq);
}
static int __init my_init(void)
{
pr_info(“Wait queue example\n”);
INIT_WORK(&wrk, work_handler);
schedule_work(&wrk);
pr_info(“Going to sleep %s\n”, __FUNCTION__);
wait_event_interruptible(my_wq, condition != 0);
pr_info(“woken up by the work job\n”);
return 0;}
void my_exit(void)
{
pr_info(“waitqueue example cleanup\n”);
}
module_init(my_init);module_exit(my_exit);MODULE_AUTHOR(“John Madieu <[email protected]>”);MODULE_LICENSE(“GPL”);
In the preceding example, the current process (actually, this is insmod) will be put to sleep in the wait queue for 5 seconds and woken up by the work handler. The output of dmesg is as follows:
[342081.385491] Wait queue example [342081.385505] Going to sleep my_init [342081.385515] Waitqueue module handler work_handler [342086.387017] Wake up the sleeping module [342086.387096] woken up by the work job [342092.912033] waitqueue example cleanup
You may have noticed that I did not check the return value of wait_event_interruptible(). Sometimes (if not most of the time), this can lead to serious issues. The following is a true story: I’ve had to intervene in a company to fix a bug where killing (or sending a signal to) a user space task was making their kernel module crash the system (panic and reboot – of course, the system was configured so that it rebooted on panic). The reason this happened was because there was a thread in this user process that did an ioctl() on the char device exposed by their kernel module. This resulted in a call to wait_event_interruptible() in the kernel on a given flag, which meant there was some data that needed to be processed in the kernel (the select() system call could not be used).
So, what was their mistake? The signal that was sent to the process was making wait_event_interruptible() return without the flag being set (which meant data was still not available), and its code was not checking its return value, nor rechecking the flag or performing a sanity check on the data that was supposed to be available. The data was being accessed as if the flag had been set and it actually dereferenced an invalid pointer.
The solution could have been as simple as using the following code:
if (wait_event_interruptible(...)){
pr_info(“catching a signal supposed make us crashing\n”);
/* handle this case and do not access data */
[….]
} else {
/* accessing data and processing it */
[…]
}
However, for some reason (historical to their design), we had to make it uninterruptible, which resulted in us using wait_event(). However, note that this function puts the process into an exclusive wait (an uninterruptible sleep), which means it can’t be interrupted by signals. It should only be used for critical tasks. Interruptible functions are recommended in most situations.
Now that we are familiar with the kernel locking APIs, we will look at various work deferring mechanisms, all of which are heavily used when writing Linux device drivers.