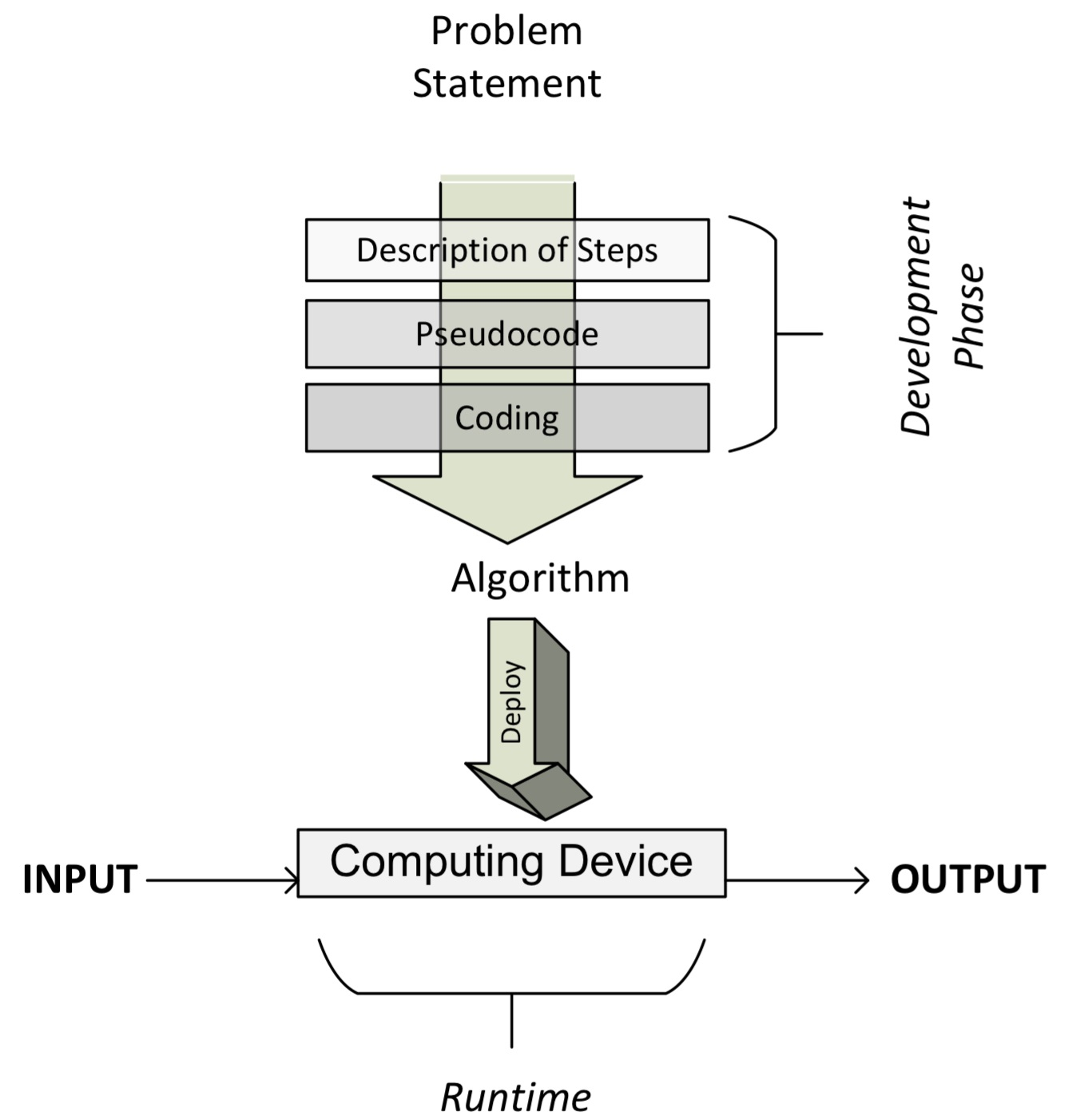
When designing an algorithm, it is important to find different ways to specify its details. The ability to capture both its logic and architecture is required. Generally, just like building a home, it is important to specify the structure of an algorithm before actually implementing it. For more complex distributed algorithms, pre-planning the way their logic will be distributed across the cluster at running time is important for the iterative efficient design process. Through pseudocode and execution plans, both these needs are fulfilled and are discussed in the next section.
-
Book Overview & Buying

-
Table Of Contents

40 Algorithms Every Programmer Should Know
By :
40 Algorithms Every Programmer Should Know
By:
Overview of this book
Algorithms have always played an important role in both the science and practice of computing. Beyond traditional computing, the ability to use algorithms to solve real-world problems is an important skill that any developer or programmer must have. This book will help you not only to develop the skills to select and use an algorithm to solve real-world problems but also to understand how it works.
You’ll start with an introduction to algorithms and discover various algorithm design techniques, before exploring how to implement different types of algorithms, such as searching and sorting, with the help of practical examples. As you advance to a more complex set of algorithms, you'll learn about linear programming, page ranking, and graphs, and even work with machine learning algorithms, understanding the math and logic behind them. Further on, case studies such as weather prediction, tweet clustering, and movie recommendation engines will show you how to apply these algorithms optimally. Finally, you’ll become well versed in techniques that enable parallel processing, giving you the ability to use these algorithms for compute-intensive tasks.
By the end of this book, you'll have become adept at solving real-world computational problems by using a wide range of algorithms.
Table of Contents (19 chapters)
Preface
Section 1: Fundamentals and Core Algorithms
 Free Chapter
Free Chapter
Overview of Algorithms
Data Structures Used in Algorithms
Sorting and Searching Algorithms
Designing Algorithms
Graph Algorithms
Section 2: Machine Learning Algorithms
Unsupervised Machine Learning Algorithms
Traditional Supervised Learning Algorithms
Neural Network Algorithms
Algorithms for Natural Language Processing
Recommendation Engines
Section 3: Advanced Topics
Data Algorithms
Cryptography
Large-Scale Algorithms
Practical Considerations
Other Books You May Enjoy