

Let's take a very simple example of a traditional monolithic application: a hotel booking website.
Besides the static HTML content, the website has a booking feature that will let its users book hotels in any city in the world. Users can search for hotels, then book them with their credit cards.
When a user performs a search on the hotel website, the application goes through the following steps:
- It runs a couple of SQL queries against its hotels' database.
- An HTTP request to a partner's service is made to add more hotels to the list.
- An HTML results page is generated using an HTML template engine.
From there, once the user has found the perfect hotel and clicked on it to book it, the application performs these steps:
- The customer gets created in the database if needed, and has to authenticate.
- Payment is carried out by interacting with the bank web service.
- The app saves the payment details in the database for legal reasons.
- A receipt is generated using a PDF generator.
- A recap email is sent to the user using the email service.
- A reservation email is forwarded to the third-party hotel using the email service.
- A database entry is added to keep track of the reservation.
This process is a simplified model of course, but quite realistic.
The application interacts with a database that contains the hotel's information, the reservation details, the billing, the user information, and so on. It also interacts with external services for sending emails, making payments, and getting more hotels from partners.
In the good old LAMP (Linux-Apache-MySQL-Perl/PHP/Python) architecture, every incoming request generates a cascade of SQL queries on the database, and a few network calls to external services, and then the server generates the HTML response using a template engine.
The following diagram illustrates this centralized architecture:
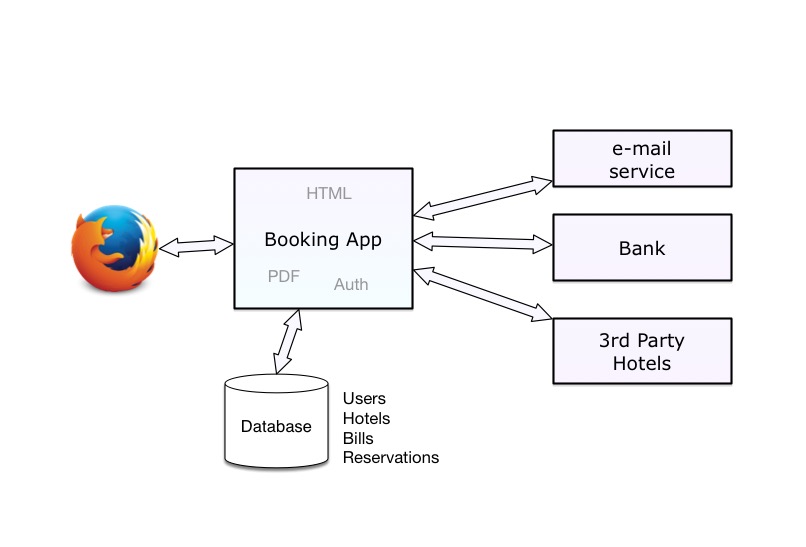
This application is a typical monolith, and it has a lot of obvious benefits.
The biggest one is that the whole application is in a single code base, and when the project coding starts, it makes everything simpler. Building a good test coverage is easy, and you can organize your code in a clean and structured way inside the code base. Storing all the data into a single database also simplifies the development of the application. You can tweak the data model, and how the code will query it.
The deployment is also a no brainer: we can tag the code base, build a package, and run it somewhere. To scale it, we can run several instances of the booking app, and run several databases with some replication mechanism in place.
If your application stays small, this model works well and is easy to maintain for a single team.
But projects are usually growing, and they get bigger than what was first intended. And having the whole application in a single code base brings some nasty issues along the way. For instance, if you need to make a sweeping change that is large in scope such as changing your banking service or your database layer, the whole application gets into a very unstable state. These changes are a big deal in the project's life, and they necessitate a lot of extra testing to deploy a new version. And changes like this will happen in a project life.
Small changes can also generate collateral damage because different parts of the system have different uptime and stability requirements. Putting the billing and reservation processes at risk because the function that creates the PDF crashes the server is a bit of a problem.
Uncontrolled growth is another issue. The application is bound to get new features, and with developers leaving and joining the project, the code organization might start to get messy, the tests a bit slower. This growth usually ends up with a spaghetti code base that's hard to maintain, with a hairy database that needs complicated migration plans every time some developer refactors the data model.
Big software projects usually take a couple of years to mature, and then they slowly start to turn into an incomprehensible mess that's hard to maintain. And it does not happen because developers are bad. It happens because as the complexity grows, fewer people fully understand the implications of every small change they make. So they try to work in isolation in one corner of the code base, and when you take the 10,000-foot view of the project, you can see the mess.
We've all been there.
It's not fun, and developers who work on such a project dream of building the application from scratch with the newest framework. And by doing so, they usually fall into the same issues again--the same story is repeated.
The following points summarize the pros and cons of the monolithic approach:
- Starting a project as a monolith is easy, and probably the best approach.
- A centralized database simplifies the design and organization of the data.
- Deploying one application is simple.
- Any change in the code can impact unrelated features. When something breaks, the whole application may break.
- Solutions to scale your application are limited: you can deploy several instances, but if one particular feature inside the app takes all the resources, it impacts everything.
- As the code base grows, it's hard to keep it clean and under control.
There are, of course, some ways to avoid some of the issues described here.
The obvious solution is to split the application into separate pieces, even if the resulting code is still going to run in a single process. Developers do this by building their apps with external libraries and frameworks. Those tools can be in-house or from the Open Source Software (OSS) community.
Building a web app in Python if you use a framework like Flask, lets you focus on the business logic, and makes it very appealing to externalize some of your code into Flask extensions and small Python packages. And splitting your code into small packages is often a good idea to control your application growth.
"Small is beautiful."
- The UNIX Philosophy
For instance, the PDF generator described in the hotel booking app could be a separate Python package that uses Reportlab and some templates to do the work.
Chances are this package can be reused in some other apps, and maybe, even published to the Python Package Index (PyPI) for the community.
But you're still building a single application and some problems remain, like the inability to scale parts differently, or any indirect issue introduced by a buggy dependency.
You'll even get new challenges, because you're now using dependencies. One problem you can get is dependency hell. If one part of your application uses a library, but the PDF generator can only use a specific version of that library, there are good chances you will eventually have to deal with it with some ugly workaround, or even fork the dependency to have a custom fix there.
Of course, all the problems described in this section do not appear on day 1 when the project starts, but rather pile up over time.
Let's now look at how the same application would look like if we were to use microservices to build it.