

In this recipe, we'll create a new contact with which hosts and services can interact with each other, chiefly to inform the contact when the state of hosts or services changes. We'll use the simplest example of setting up an e-mail contact and configuring an existing host so that this contact receives an e-mail message when Nagios Core's host checks fail and the host is apparently unreachable. In this instance, we'll arrange for [email protected] to receive an e-mail message whenever the sparta.example.net host goes from the DOWN state to the UP state, or vice-versa.
You should have a working Nagios Core 4.0 or better server running with a web interface and at least one host to check. If you need to do this first, refer to the Creating a new network host recipe in this chapter.
For this particular kind of contact, you'll also need to have a working SMTP daemon running on the monitoring server, such as Exim or Postfix. You should verify that you're able to send messages to the target address and that they're successfully delivered to the host you expect them to be delivered to.
We can add a simple new contact to the Nagios Core configuration as follows:
Change to Nagios Core's configuration directory; ideally, it should contain a file that's devoted to contacts, such as
contacts.cfghere, and edit that file:# cd /usr/local/nagios/etc/objects # vi contacts.cfg
Add the following contact definition to the end of the file, substituting your own values for the properties in bold as you need them:
define contact { contact_name spartaadmin alias Administrator of sparta.example.net email [email protected] host_notification_commands notify-host-by-email host_notification_options d,u,r host_notification_period 24x7 service_notification_commands notify-service-by-email service_notification_options w,u,c,r service_notification_period 24x7 }Edit the definition for the
sparta.example.nethost and add or replace the definition ofcontactsfor the appropriate host to our new contactspartaadmin:define host { host_name sparta.example.net alias sparta address 192.0.2.21 max_check_attempts 3 check_period 24x7 check_command check-host-alive contacts spartaadmin notification_interval 60 notification_period 24x7 }Reload the configuration:
# /etc/init.d/nagios reload
When we are done with the preceding steps, the next time our host changes its state we should receive messages like the one shown in the following screenshot:
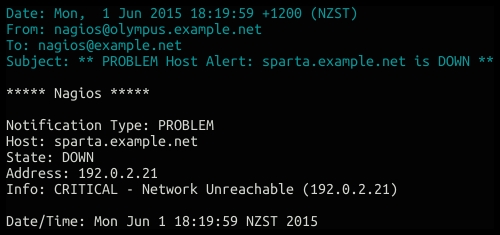
When the host becomes available again, we should receive a recovery message as follows:
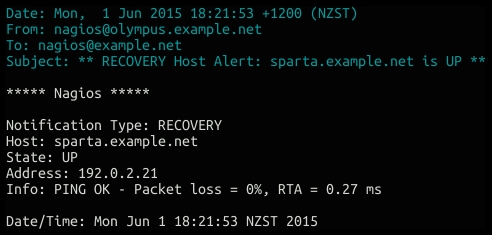
If possible, it's worth testing this setup with a test host that we can safely bring down and then up again to verify that we receive appropriate notifications.
This configuration adds a new contact to the Nagios Core configuration and references it in one of the hosts as the appropriate contact to be used when the host has problems.
We've defined the required directives for the contact and a couple of others:
contact_name: This defines a unique name for the contact so that we can refer to it in host and service definitions, or anywhere else we might need to do so in the Nagios Core configuration.alias: This defines a human-friendly name for the contact, perhaps a brief explanation of who the person or group is and/or what they're responsible for.email: This defines the e-mail address of the contact, since we're going to be sending messages by e-mails.host_notification_commands: This defines the command or commands to be run when a state change on a host prompts a notification for this contact. In this case, we're going to send e-mails to the the contact about the results with a predefined command callednotify-host-by-email.host_notification_options: This specifies different kinds of host events for which this contact should be notified. Here, we're usingd,u,r, which means that this contact will receive notifications for a host going down, becoming unreachable, or coming back up.host_notification_period: This defines the time period in which this contact can be notified by any host events. If a host notification is generated and defined to be sent to this contact, but falls outside this time period, the notification will not be sent.service_notification_commands: This defines the command or commands that are to be run when a state change on a service prompts a notification for this contact. In this case, we're going to send an e-mail to the contact about the results with a predefined command callednotify-service-by-email.service_notification_options: This specifies different kinds of service events for which this contact should be notified. Here, we're usingw,u,c,r, which means that we want to receive notifications about services enteringWARNING,UNKNOWN, orCRITICALstates, and also when they recover and go back to theOKstate.service_notification_period: This is the same as forhost_notification_period, except that this directive refers to notifications about services, not hosts.
Note that we placed the definition for the contact in contacts.cfg, which is a reasonably sensible place. However, we can place the contact definition in any file that Nagios Core will read as part of its configuration; we can organize our hosts, services, and contacts any way we like, but it helps to choose some sort of system, so we can easily identify where definitions are likely to be when we need to add, change, or remove them.
If we define a lot of contacts with similar options, it may be appropriate to have individual contacts extend contact templates, so they can inherit those common settings. The default Nagios Core configuration includes such a template, called generic-contact. We could instead define our new contact as an extension of this template as follows:
define contact {
use generic-contact
contact_name spartaadmin
alias Administrator of sparta.example.net
email [email protected]
}To see the directives defined for generic-contact, you can inspect its definition in the /usr/local/nagios/etc/objects/templates.cfg file.