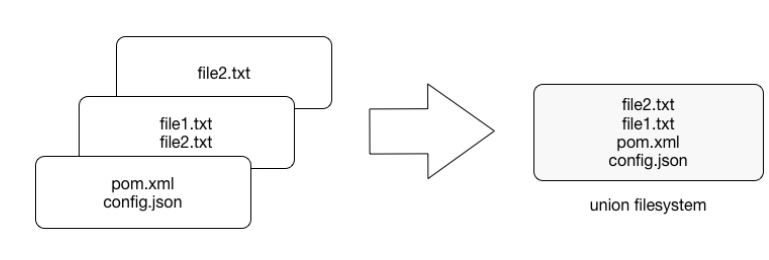
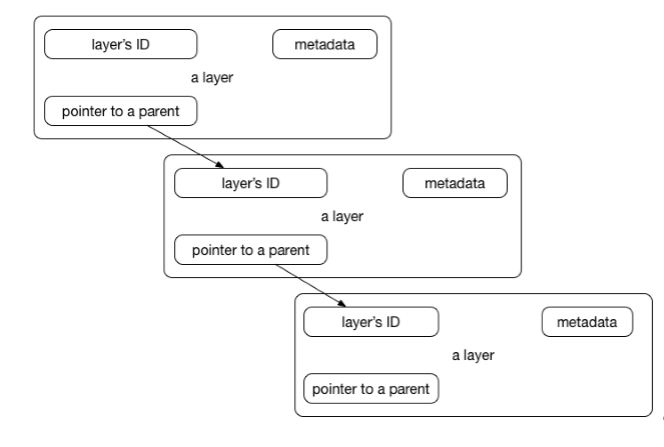
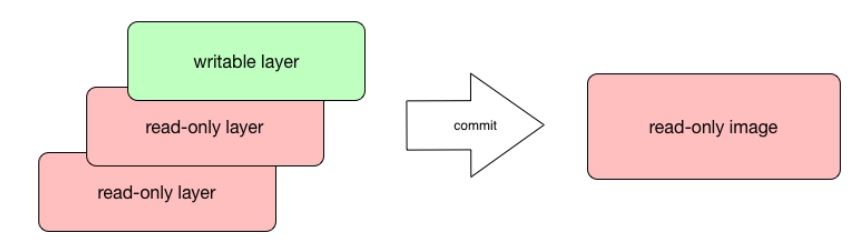
When dealing with Kubernetes, we will be working with Docker containers; it is an open source container cluster manager. To run our own Java application, we will need to create an image first. Let's begin with the concept of Docker images.
-
Book Overview & Buying

-
Table Of Contents

Docker and Kubernetes for Java Developers
By :
Docker and Kubernetes for Java Developers
By:
Overview of this book
Imagine creating and testing Java EE applications on Apache Tomcat Server or Wildfly Application server in minutes along with deploying and managing Java applications swiftly. Sounds too good to be true? But you have a reason to cheer as such scenarios are only possible by leveraging Docker and Kubernetes.
This book will start by introducing Docker and delve deep into its networking and persistent storage concepts. You will then proceed to learn how to refactor monolith application into separate services by building an application and then packaging it into Docker containers. Next, you will create an image containing Java Enterprise Application and later run it using Docker. Moving on, the book will focus on Kubernetes and its features and you will learn to deploy a Java application to Kubernetes using Maven and monitor a Java application in production. By the end of the book, you will get hands-on with some more advanced topics to further extend your knowledge about Docker and Kubernetes.
Table of Contents (12 chapters)
Preface
 Free Chapter
Free Chapter
Introduction to Docker
Networking and Persistent Storage
Working with Microservices
Creating Java Microservices
Creating Images with Java Applications
Running Containers with Java Applications
Introduction to Kubernetes
Using Kubernetes with Java
Working with the Kubernetes API
Deploying Java on Kubernetes in the Cloud
More Resources