

9.3 CONNECTION WEIGHTS AND THE COMBINATION FUNCTION
The nodes in the hidden layer and the output layer collect the inputs from the previous layer and combine them using a combination function. This combination function (usually summation, Σ) produces a linear combination of the node inputs and the connection weights into a single scalar value, which we will term net. Thus, for a given node j,
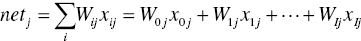
where xij represents the ith input to node j, Wij represents the weight associated with the ith input to node j, and there are I + 1 inputs to node j. Note that x1, x2, …, xI represent inputs from upstream nodes, while x0 represents a constant input, analogous to the constant factor in regression models, which by convention uniquely takes the value x0j = 1. Thus, each hidden layer or output layer node j contains an “extra” input equal to a particular weight W0j x0j = W0j, such as W0B for node B.
We...