

Having learned about the row store engine of SAP HANA, now let us learn about the column store engine. Data will be stored in RAM, similar to the row store engine. The concept of column storage has emerged from Text Retrieval and Extraction (TREX). This technology was further developed into a full relational column-based datastore. Compression works well with columns and can speed up operations on columns up to a factor of 10. Column storage is optimized for high performance of a read operation. There are two types of indices for column store table for each column: a main storage and a delta storage. For write operations, the delta storage is optimized. The main storage is optimized in terms of the read performance and memory consumption. Performance issues when loading directly to compressed columns can be addressed by the delta tables.
The architecture of a column store is shown in the following diagram:
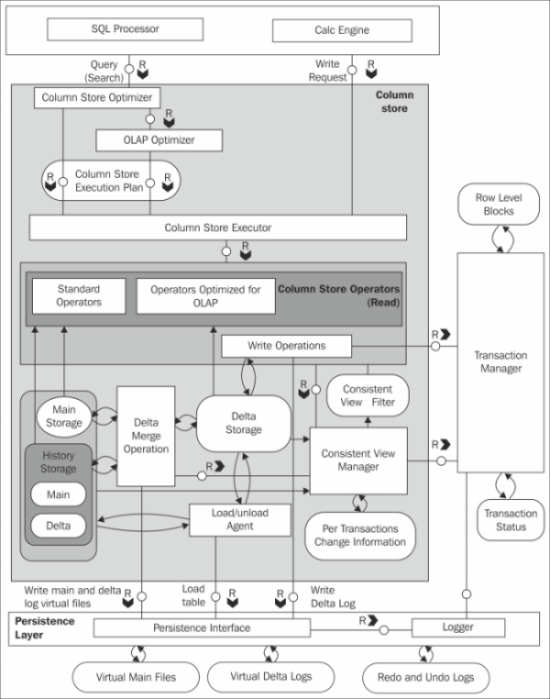
The components of the column engine are explained as follows:
Optimizer and Executor: Optimizer gets the logical execution plan from SQL Parser or Calc engine as input, and generates the optimized physical execution plan based on the database statistics. The best plan for accessing row or column stores will be determined by the database optimizer. Executor basically executes the physical execution plan to access the row and column stores, and also processes all the intermediate results.
Main Storage: Data is highly compressed and stored in the main storage. Being compressed and stored in column storage, data is read very fast.
Delta Storage: Delta storage is designed for fast writing operation. When there is an update operation to be performed, a new entry is added into the delta storage.
Delta Merge: Write operations are only performed on the delta storage. The database is transferred to the main storage in order to transform the data into a format that is optimized in terms of memory consumption and read performance. This is accomplished by a process called delta merge. The following section is intended to give a better understanding of how this happens and when.
The following diagram describes the different states of a merge process, which objects are involved, and how they are accessed.

The following operations are performed for the merge process:
Before the merge operation: All the write operations go to the storage Delta1, and the read operations read from the storages Main1 and Delta1.
During the merge operation: When the merge operation is in progress, all the changes go into the second delta storage Delta2. The read operations continue from the original main storage (Main1) and from both the delta storage (Delta1 and Delta2). The uncommitted changes from Delta1 are copied to Delta2. The committed entries in Delta1 and content of Main1 are merged into the new main storage, that is, Main2.
After the merge operation: Main1 and Delta1 storages are deleted after the merge operation is complete.
The consistent view manager creates a consistent view throughout data for the moment in time when the query hits the system. Isolation of concurrent transactions is enforced by a central transaction manager, maintaining information about all write transactions and the consistent view manager deciding on visibility of records per table. A so-called transaction token is generated by the transaction manager for each transaction, encoding which transactions are open, and is committed at the point in time when the transaction has started. The transaction token holds all the information needed to construct the consistent view for a transaction or a statement. It is passed as additional context information to all the operations and engines that are involved in the execution of a statement.
It is better to go with column storage under the following situations:
Recommended when the tables contain huge volumes of data
Used when lot of aggregations need to be done on the tables
Used when the tables have huge number of columns
Used when the table has to be searched based on the values of few columns
The main advantages with column storage are
Number of cache cycles will be reduced and this will help to retrieve the data at a faster rate
Supports parallel processing
For more information, refer the following links: