

In the SAP HANA database, during normal operation, data is automatically saved to the disk at regular savepoints. Furthermore, the log captures all the data changes. After each committed database transaction, the log is saved from the memory to the disk. When there is a power failure, the database can be restarted like any disk-based database, and it returns to its last consistent state by replaying the log since the last savepoint.
The backups are required for the following reasons:
To protect against disk failures
To make it possible to reset the database to an earlier point in time
Backups are carried out while the database is running and users can continue to work normally. The impact on system performance is negligible.
SAP HANA is an in-memory database or a database that stores its database tables in the main memory RAM. RAM is the fastest possible data storage media available as of today; however, it is volatile. During power loss, the data bits on the chip are erased or lost.
In order to avoid data loss, SAP HANA encompasses regular savepoints using two persistent storage volumes, that is, database logging or redo logging. With the combination of both redo logging and in-memory data savepoints, the system is fully capable of recovering from a sudden power failure.
The administration console of the SAP HANA studio provides a one-stop support environment for different activities such as system monitoring, back up and recovery, and user provisioning. The entire payload data from all the server nodes of the SAP HANA database instance are backed up as soon as the data area is backed up. This principle applies for both single-host and multihost environments.
During a log back up, the payload of the log segments is copied from the log area to the service-specific log backup files. Back up and recovery always applies to the entire database. It is not possible to back up or recover individual database objects. While performing a backup of the SAP HANA system, all the objects such as database tables, information models (that is, views and undo logs), information views, and metadata are all saved to a configurable persistent disk location. In the summary, all of the data and code that are stored in SAP HANA will be taken as a back up which is available at the specified path.
By default, the SAP HANA system creates log file backup for every 15 minutes (900 seconds), or when the standard log segments become full.
In case of scenarios of data center failures due to accidents such as fire, power outages, natural calamities such as earthquakes, or due to hardware failures such as the failure of any node, SAP HANA supports a hot-standby concept using synchronous mirroring with a redundant data center concept. This includes redundant SAP HANA databases also.
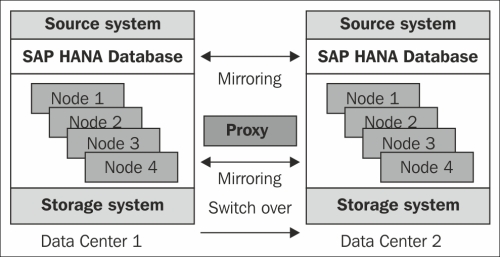
In addition, the cold-standby concept uses a standby system within one SAP HANA landscape, where the failover is triggered automatically. SAP HANA is an ACID-compliant database supporting atomicity, consistency, isolation, and durability of transactions.
In addition to recovery for Online Analytical Processing (OLAP), SAP HANA also provides transactional recovery for Online Transactional Processing (OLTP) through the administrative console in the SAP HANA studio.
The currently supported processes are given as follows:
Recovery to last data backup
Recovery to last and older (previous) data backup
Recovery to last state before crash
Point-in-time recovery
User provisioning is supported with role-based security, authentication, and analysis authorization using analytic privileges, which enables security for analytical objects based on a set of attribute values.
The administration console in SAP HANA Studio enables the version control mechanism for models of SAP HANA and SAP Data Services. SAP HANA can run in a single production landscape if the initial use case scenario is not business critical and the data load performance for the initial load is acceptable to reload the data. However, it is always recommended to align the SLT and SAP Data Services environment with the existing source system landscapes. When it comes to enterprise-grade business supporting mode of environment, SAP HANA needs to run in the standard landscape, that is, SAP development, quality assurance and staging, and production environments.

For scale-up scalability, all algorithms and data structures are designed to work on large multi-core architectures, especially focusing on the cache-aware data structures and code fragments. For scale-out scalability, the SAP HANA database is designed to run on a cluster of individual machines. This allows the distribution of data and query processing across multiple nodes. The scalability features of the SAP HANA database are heavily based on the proven technology of the SAP BWA product.
Also, refer to SAP Note: 1642148