-
Book Overview & Buying

-
Table Of Contents

Introduction to R for Quantitative Finance
By :
Introduction to R for Quantitative Finance
By:
Overview of this book
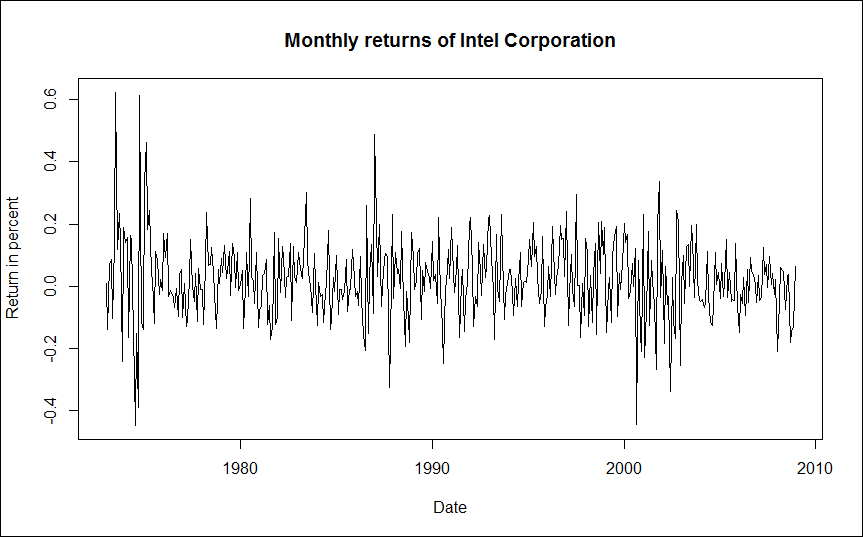
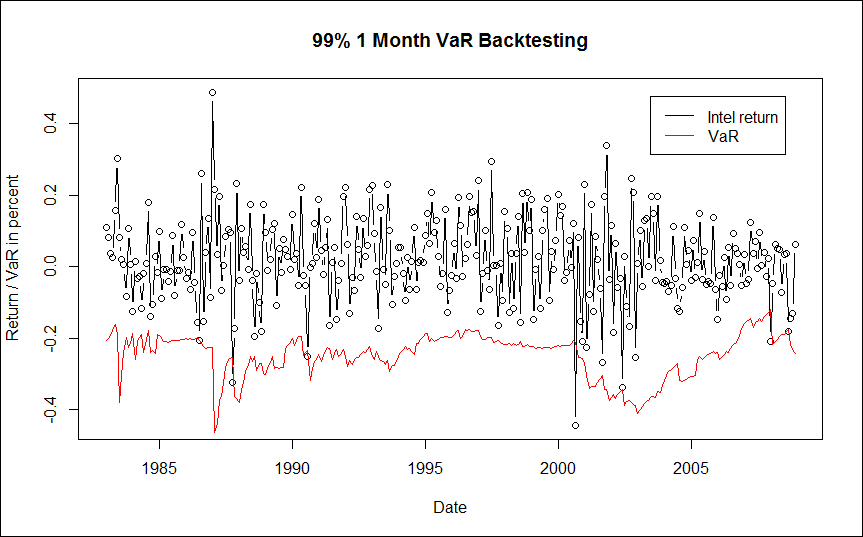
Introduction to R for Quantitative Finance will show you how to solve real-world quantitative fi nance problems using the statistical computing language R. The book covers diverse topics ranging from time series analysis to fi nancial networks. Each chapter briefl y presents the theory behind specific concepts and deals with solving a diverse range of problems using R with the help of practical examples.This book will be your guide on how to use and master R in order to solve quantitative finance problems. This book covers the essentials of quantitative finance, taking you through a number of clear and practical examples in R that will not only help you to understand the theory, but how to effectively deal with your own real-life problems.Starting with time series analysis, you will also learn how to optimize portfolios and how asset pricing models work. The book then covers fixed income securities and derivatives such as credit risk management.
Table of Contents (17 chapters)
Introduction to R for Quantitative Finance

Credits
About the Authors
About the Reviewers
www.PacktPub.com
Preface
 Free Chapter
Free Chapter
Time Series Analysis
Portfolio Optimization
Asset Pricing Models
Fixed Income Securities
Estimating the Term Structure of Interest Rates
Derivatives Pricing
Credit Risk Management
Extreme Value Theory
Financial Networks
References
Index