

Web scraping with R
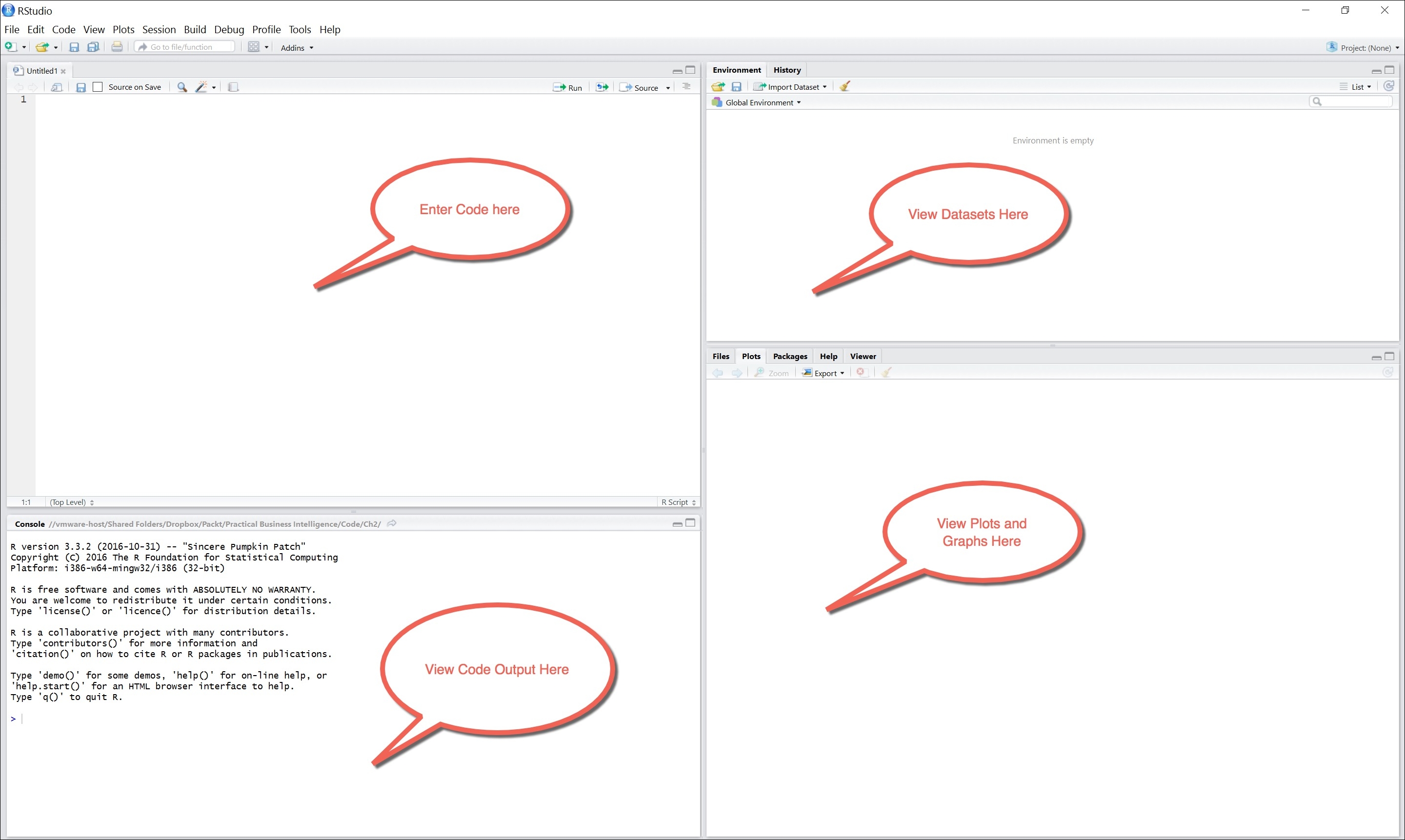
When we first open up RStudio, the first thing that we see is four main quadrants. These four quadrants represent our coding input as well as coding output, as shown in the following screenshot:
Let's now set up a new file, which we will use to get our web scraper up and running, by going to File | New File | R Script, as seen in the following screenshot:

We now have a blank R file to begin our coding. The next step is identifying the website data that will be the source of our web scraping exercise.
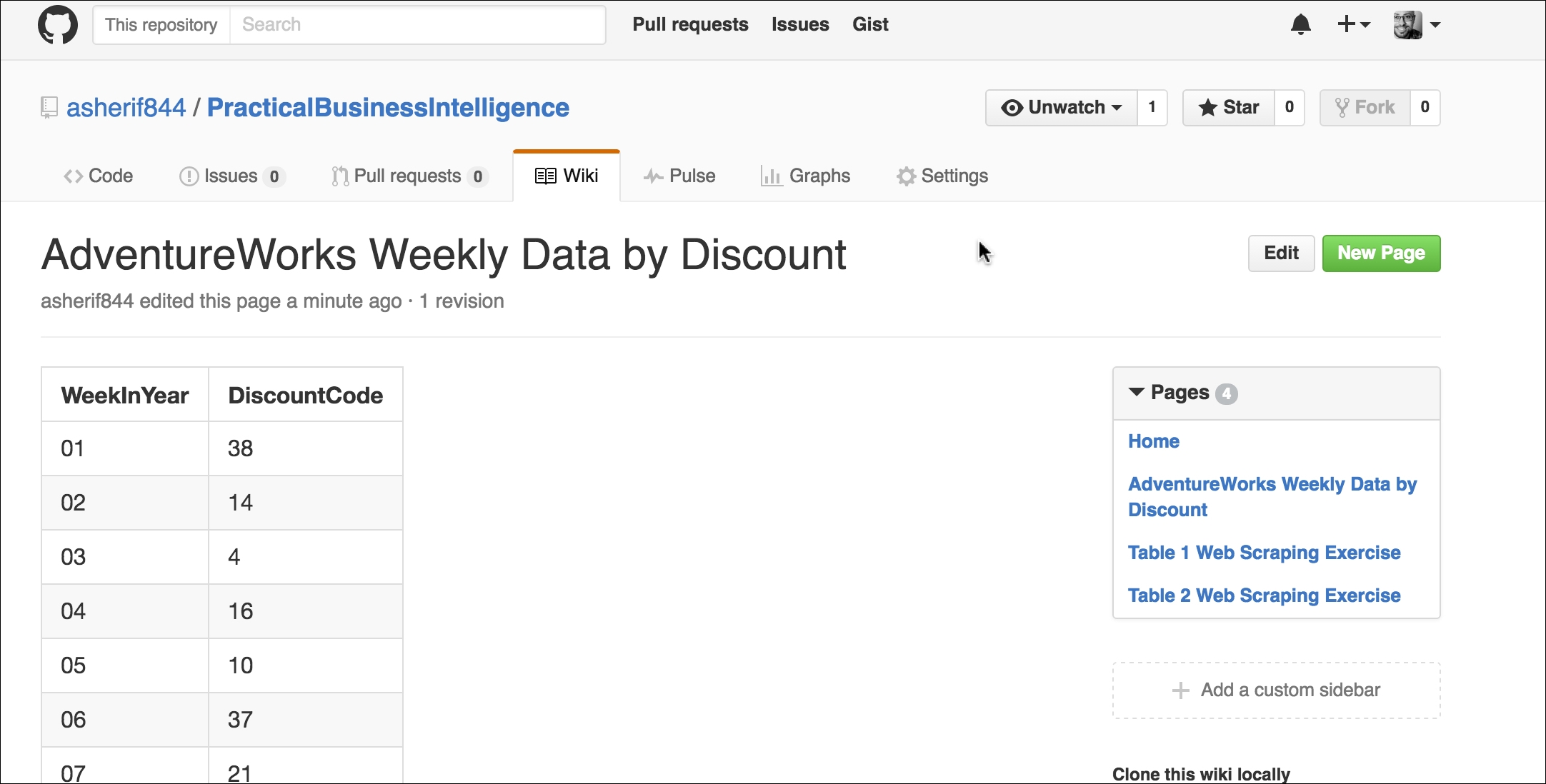
The following link (https://github.com/asherif844/PracticalBusinessIntelligence/wiki/AdventureWorks---Weekly-Data-by-Discount) within GitHub has a useful table that we can scrape from to incorporate into our database.
|
WeekInYear |
DiscountCode |
|
01 |
38 |
|
02 |
14 |
|
03 |
4 |
|
04 |
16 |
|
05 |
10 |
The full data in the table can also be seen in the following screenshot:
In order to scrape this Wikipedia table from R, we will need to install a couple of libraries within our R framework...