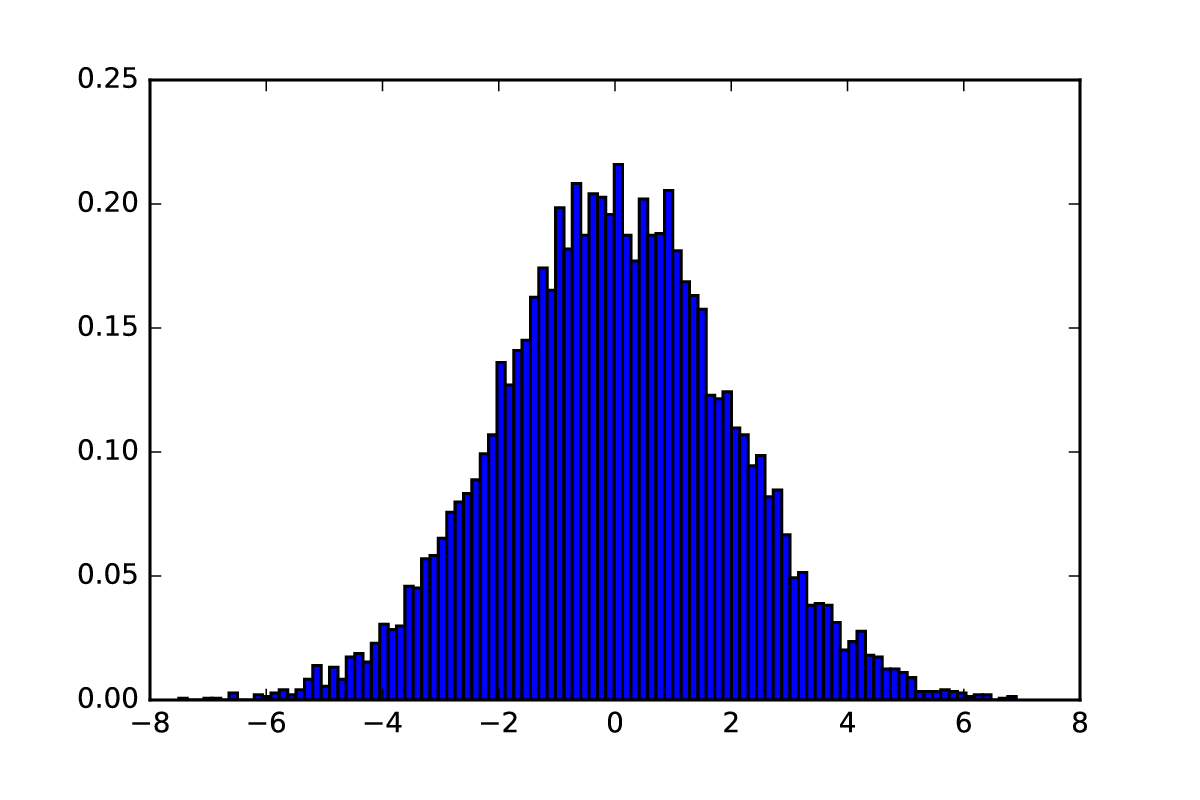
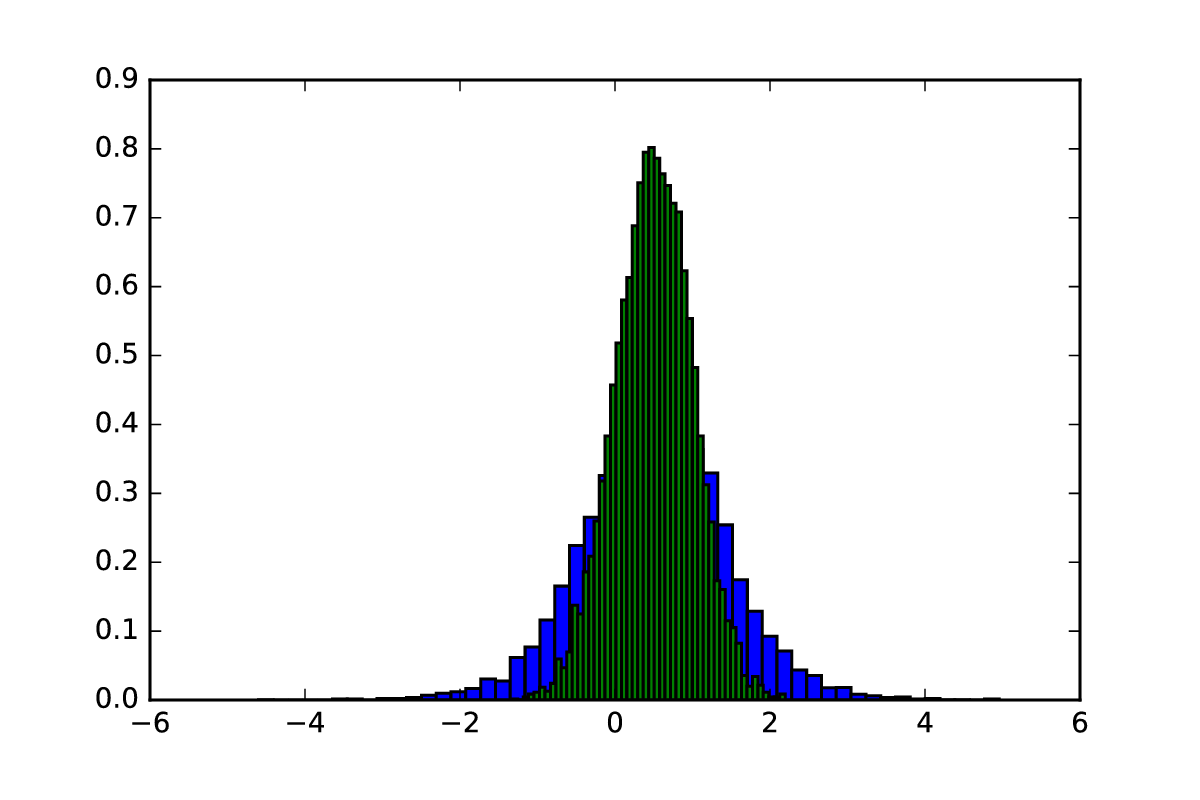
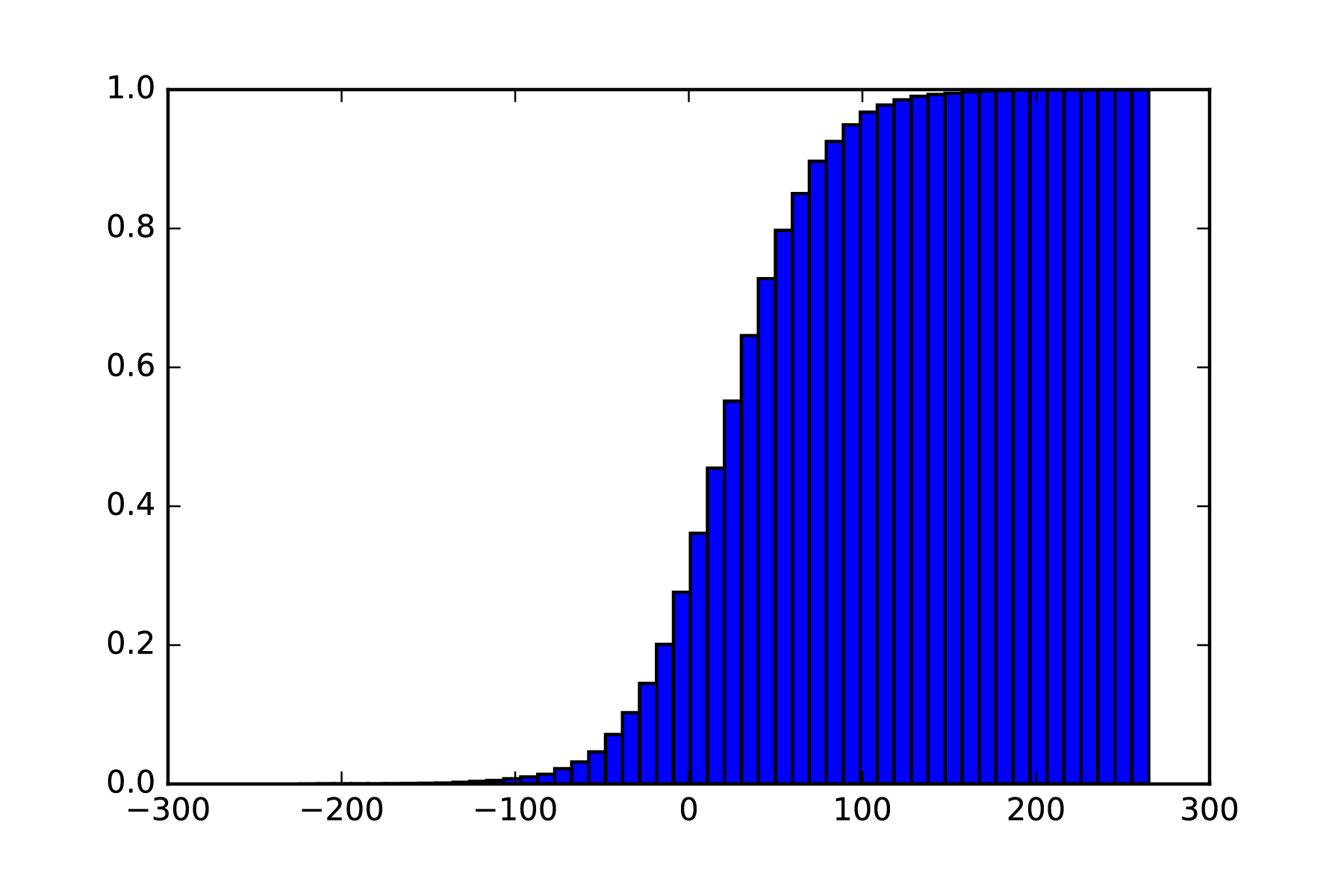
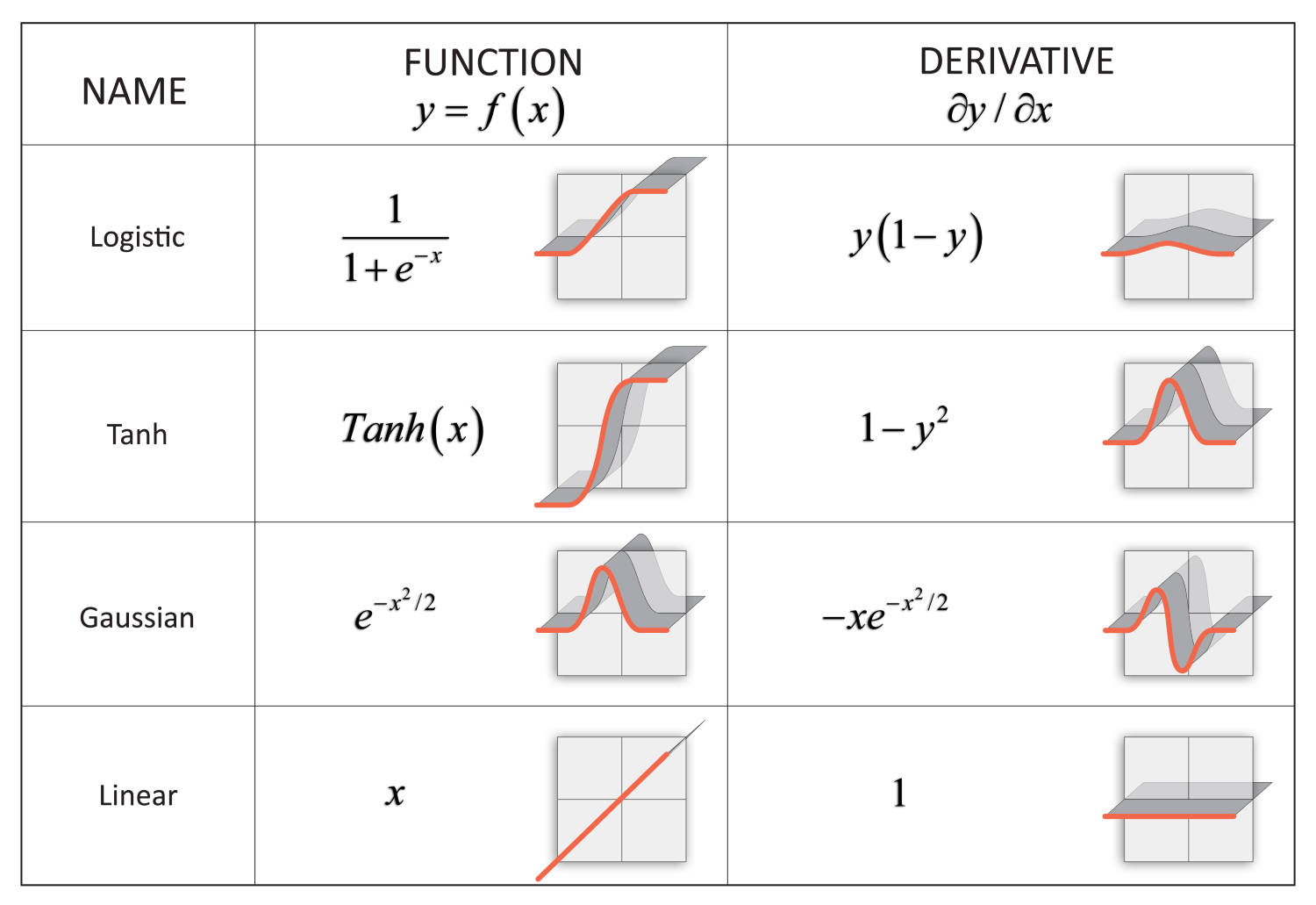
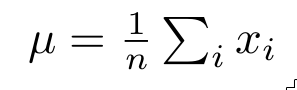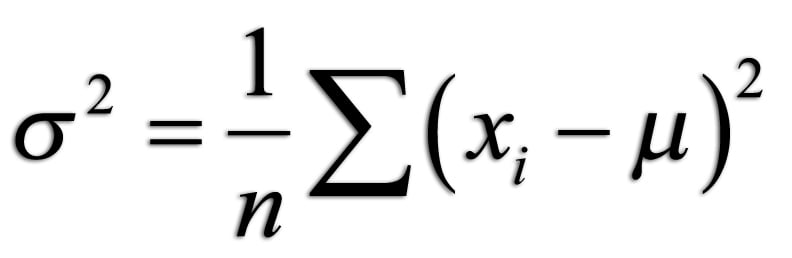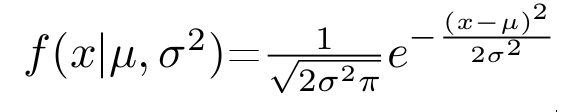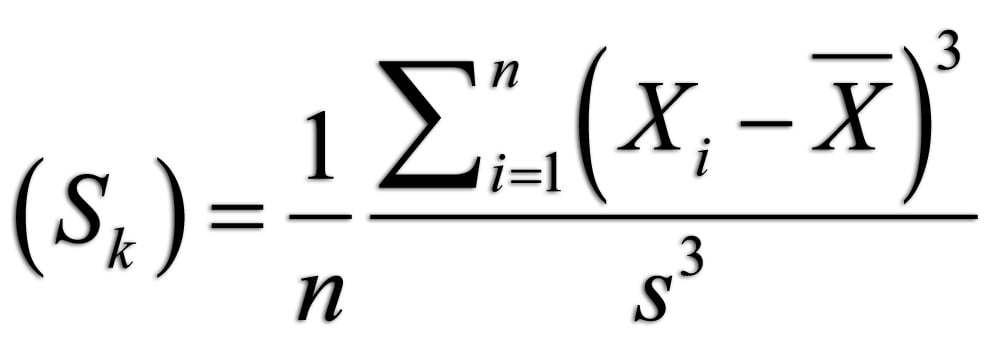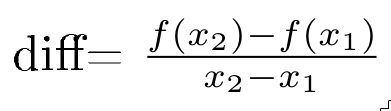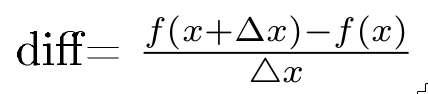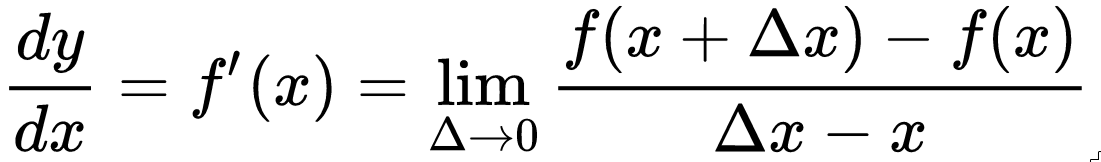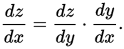If we want to measure how a function changes over time, the first intuitive step would be to take the value of a function and then measure it at the subsequent point. Subtracting the second value from the first would give us an idea of how much the function changes over time:
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
def quadratic(var):
return 2* pow(var,2)
x=np.arange(0,.5,.1)
plt.plot(x,quadratic(x))
plt.plot([1,4], [quadratic(1), quadratic(4)], linewidth=2.0)
plt.plot([1,4], [quadratic(1), quadratic(1)], linewidth=3.0,
label="Change in x")
plt.plot([4,4], [quadratic(1), quadratic(4)], linewidth=3.0,
label="Change in y")
plt.legend()
plt.plot (x, 10*x -8 )
plt.plot()
In the preceding code example, we first defined a sample quadratic equation (2*x2) and then defined the part of the domain in which we will work with the arange function (from 0 to 0.5, in 0.1 steps).
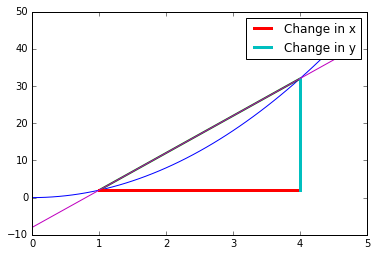
Then, we define an interval for which we measure the change of y over x, and draw lines indicating this measurement, as shown in the following graph:
Initial depiction of a starting setup for implementing differentiation
In this case, we measure the function at x=1 and x=4, and define the rate of change for this interval as follows:
Applying the formula, the result for the sample is (36-0)/3= 12.
This initial approach can serve as a way of approximately measuring this dynamic, but it's too dependent on the points at which we take the measurement, and it has to be taken at every interval we need.
To have a better idea of the dynamics of a function, we need to be able to define and measure the instantaneous change rate at every point in the function's domain.
This idea of instantaneous change brings to us the need to reduce the distance between the domain's x values, taken at a point where there are very short distances between them. We will formulate this approach with an initial value x, and the subsequent value, x + Δx:
In the following code, we approximate the difference, reducing Δx progressively:
initial_delta = .1
x1 = 1
for power in range (1,6):
delta = pow (initial_delta, power)
derivative_aprox= (quadratic(x1+delta) - quadratic (x1) )/
((x1+delta) - x1 )
print "del ta: " + str(delta) + ", estimated derivative: " +
str(derivative_aprox)
In the preceding code, we first defined an initial delta, which brought an initial approximation. Then, we apply the difference function, with diminishing values of delta, thanks us to powering 0.1 with incremental powers. The results we get are as follows:
delta: 0.1, estimated derivative: 4.2
delta: 0.01, estimated derivative: 4.02
delta: 0.001, estimated derivative: 4.002
delta: 0.0001, estimated derivative: 4.0002
delta: 1e-05, estimated derivative: 4.00002
As the separation diminishes, it becomes clear that the change rate will hover around 4. But when does this process stop? In fact, we could say that this process can be followed ad infinitum, at least in a numeric sense.
This is when the concept of limit intuitively appears. We will then define this process, of making Δ indefinitely smaller, and will call it the derivative of f(x) or f'(x):
This is the formal definition of the derivative.
But mathematicians didn't stop with these tedious calculations, making a large number of numerical operations (which were mostly done manually of the 17th century), and wanted to further simplify these operations.
What if we perform another step that can symbolically define the derivative of a function?
That would require building a function that gives us the derivative of the corresponding function, just by replacing the x variable value. That huge step was also reached in the 17th century, for different function families, starting with the parabolas (y=x2+b), and following with more complex functions: