

The visual dialogue model (VDM) enables chat based on images. VDM applies technologies from computer vision, Natural Language Processing (NLP) and chatbots. It has found major applications such as explaining to blind people about images, to doctors about medical scans, virtual companions and so on. Next, we will see the algorithm to solve this challenge.
The algorithm discussed here is proposed by Lu et al (https://research.fb.com/wp-content/uploads/2017/11/camera_ready_nips2017.pdf). Lu et al proposed a GAN-based VDM. The generator generates answers and the discriminator ranks those answers. The following is a schematic representation of the process:
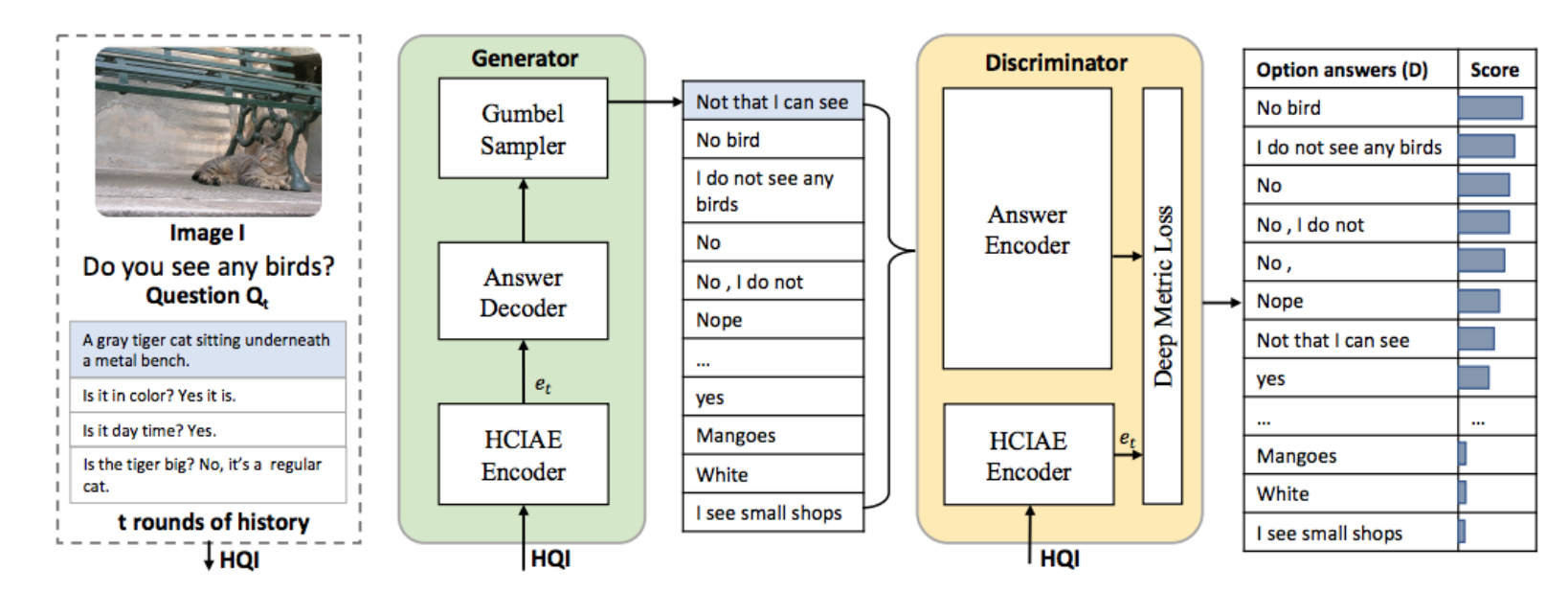
Architecture of the VDMs based on GAN techniques [Reproduced from Lu et al.]
The history of chat, the current question and image are fed as an input to the generator. Next, we will see how the generator works.