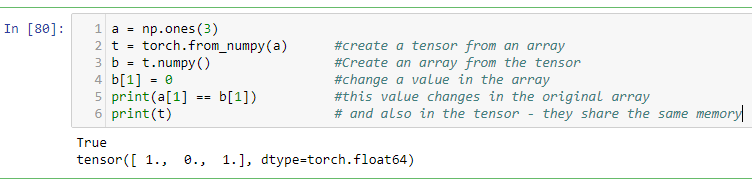
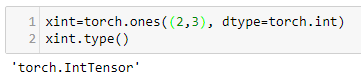
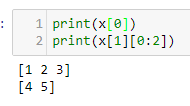
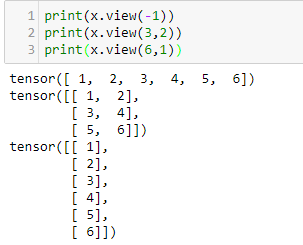
Tensors are the workhorse of PyTorch. If you know linear algebra, they are equivalent to a matrix. Torch tensors are effectively an extension of the numpy.array object. Tensors are an essential conceptual component in deep learning systems, so having a good understanding of how they work is important.
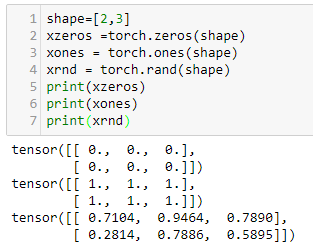
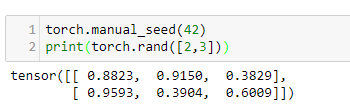
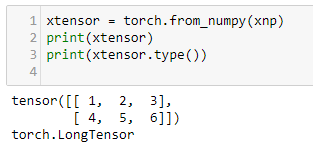
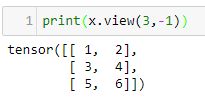
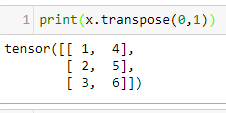
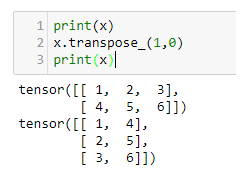
In our first example, we will be looking at tensors of size 2 x 3. In PyTorch, we can create tensors in the same way that we create NumPy arrays. For example, we can pass them nested lists, as shown in the following code:

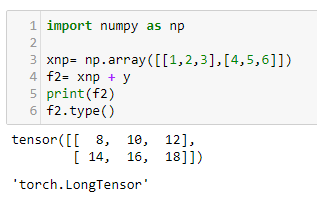
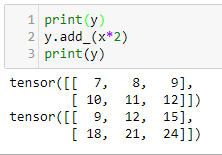
Here we have created two tensors, each with dimensions of 2 x 3. You can see that we have created a simple linear function (more about linear functions in Chapter 2, Deep Learning Fundamentals) and applied it to x and y and printed out the result. We can visualize this with the following diagram:
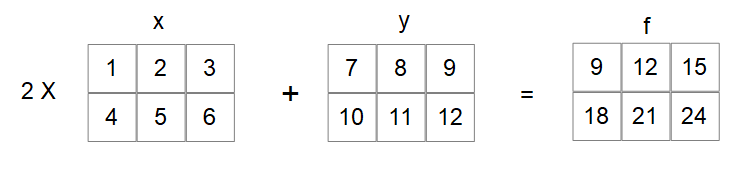
As you may know from linear algebra, matrix multiplication and addition occur element-wise so that for the first element of x, let's write this as X00. This is multiplied by two and added to the first element of y, written as Y00, giving F00 = 9. X01 = 2 and Y01 = 8 so f01 = 4 + 12. Notice that the indices start at zero.
If you have never seen any linear algebra, don't worry too much about this, as we are going to brush up on these concepts in Chapter 2, Deep Learning Fundamentals, and you will get to practice with Python indexing shortly. For now, just consider our 2 x 3 tensors as tables with numbers in them.