Most of the time you will spend on a deep learning project will be spent working with data and one of the main reasons that a deep learning project will fail is because of bad, or poorly understood data. This issue is often overlooked when we are working with well-known and well-constructed datasets. The focus here is on learning the models. The algorithms that make deep learning models work are complex enough themselves without this complexity being compounded by something that is only partially known, such as an unfamiliar dataset. Real-world data is noisy, incomplete, and error prone. These axes of confoundedness mean that if a deep learning algorithm is not giving sensible results, after errors of logic in the code are eliminated, bad data, or errors in our understanding of the data, are the likely culprit.
So putting aside our wrestle with data, and with an understanding that deep learning can provide valuable real-world insights, how do we learn deep learning? Our starting point is to eliminate as many of the variables that we can. This can be achieved by using data that is well known and representative of a specific problem; say, for example, classification. This enables us to have both a starting point for deep learning tasks, as well as a standard to test model ideas.
One of the most well-known datasets is the MNIST dataset of hand-written digits, where the usual task is to correctly classify each of the digits, from zero through nine. The best models get an error rate of around 0.2%. We could apply this well-performing model with a few adjustments, to any visual classification task, with varying results. It is unlikely we will get results anywhere near 0.2% and the reason is because the data is different. Understanding how to tweek a deep learning model to take into account these sometimes subtle differences in data, is one of the key skills of a successful deep learning practitioner.
Consider an image classification task of facial recognition from color photographs. The task is still classification but the differences in that data type and structure dictate how the model will need to change to take this into account. How this is done is at the heart of machine learning. For example, if we are working with color images, as opposed to black and white images, we will need two extra input channels. We will also need output channels for each of the possible classes. In a handwriting classification task, we need 10 output channels; one channel for each of the digits. For a facial recognition task, we would consider having an output channel for each target face (say, for criminals in a police database).
Clearly, an important consideration is data types and structures. The way image data is structured in an image is vastly different to that of, say, an audio signal, or output from a medical device. What if we are trying to classify people's names by the sound of their voice, or classify a disease by its symptoms? They are all classification tasks; however, in each specific case, the models that represent each of these will be vastly different. In order to build suitable models in each case, we will need to become intimately acquainted with the data we are using.
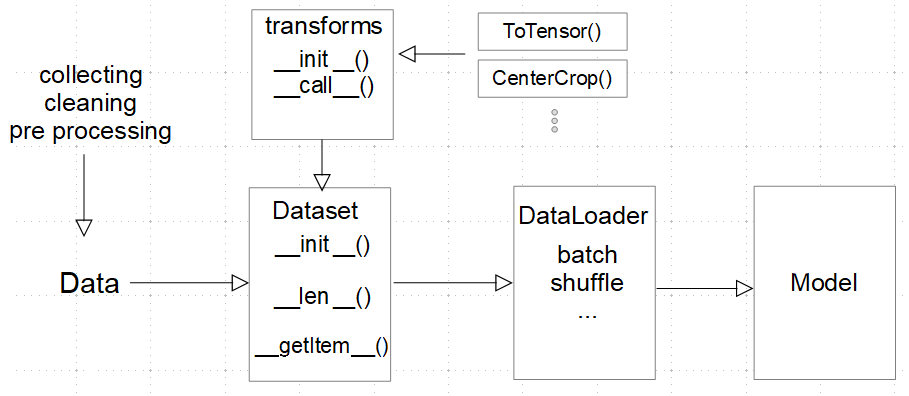
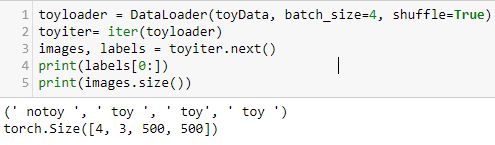
It is beyond the scope of this book to discuss the nuances and subtleties of each data type, format, and structure. What we can do is give you a brief insight into the tools, techniques, and best practice of data handling in PyTorch. Deep learning datasets are often very large and it is an important consideration to see how they are handled in memory. We need to be able to transform data, output data in batches, shuffle data, and perform many other operations on data before we feed it to a model. We need to be able to do all these things without loading the entire dataset into memory, since many datasets are simply too large. PyTorch takes an object approach when working with data, creating class objects for each specific activity. We will examine this in more detail in the coming sections.