

Understanding different components of ML pipelines
As any data scientist knows, ML is only as good as the data it’s trained on. In the real world, data is messy and complicated. Building a successful ML system, therefore, requires more than just building algorithms. It also requires a vast and complex infrastructure to support it. This includes everything from collecting and cleansing data to deploying and monitoring models. The problem is further complicated by the fact that changing anything in the system can have ripple effects throughout. A minor tweak in hyperparameters, for example, can require changes to the way data is collected and processed. As a result, building a successful ML system is an immensely complex undertaking.
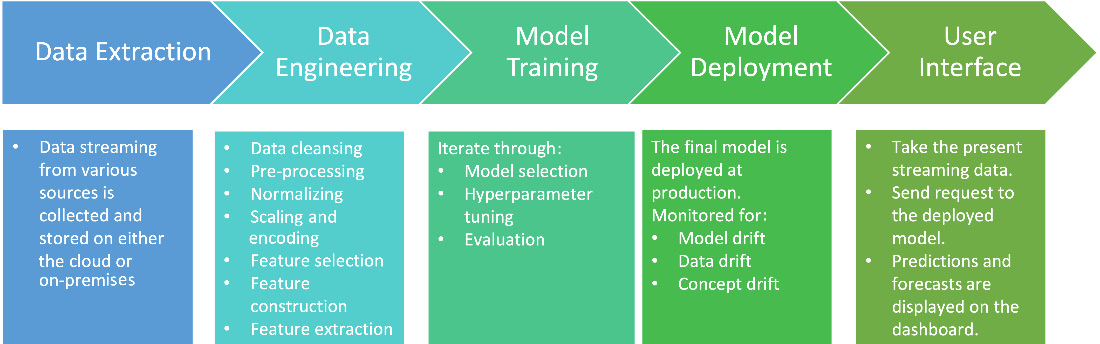
Figure 5.1 – ML workflow