-
Book Overview & Buying

-
Table Of Contents

Learn T-SQL Querying - Second Edition
By :
Learn T-SQL Querying
By:
Overview of this book
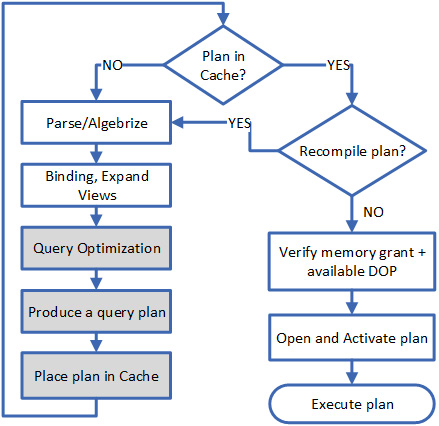
Data professionals seeking to excel in Transact-SQL for Microsoft SQL Server and Azure SQL Database often lack comprehensive resources. Learn T-SQL Querying second edition focuses on indexing queries and crafting elegant T-SQL code enabling data professionals gain mastery in modern SQL Server versions (2022) and Azure SQL Database. The book covers new topics like logical statement processing flow, data access using indexes, and best practices for tuning T-SQL queries.
Starting with query processing fundamentals, the book lays a foundation for writing performant T-SQL queries. You’ll explore the mechanics of the Query Optimizer and Query Execution Plans, learning to analyze execution plans for insights into current performance and scalability. Using dynamic management views (DMVs) and dynamic management functions (DMFs), you’ll build diagnostic queries. The book covers indexing and delves into SQL Server’s built-in tools to expedite resolution of T-SQL query performance and scalability issues. Hands-on examples will guide you to avoid UDF pitfalls and understand features like predicate SARGability, Query Store, and Query Tuning Assistant.
By the end of this book, you‘ll have developed the ability to identify query performance bottlenecks, recognize anti-patterns, and avoid pitfalls
Table of Contents (18 chapters)
Preface

Part 1: Query Processing Fundamentals
 Free Chapter
Free Chapter
Chapter 1: Understanding Query Processing
Chapter 2: Mechanics of the Query Optimizer
Part 2: Dos and Don’ts of T-SQL
Chapter 3: Exploring Query Execution Plans
Chapter 4: Indexing for T-SQL Performance
Chapter 5: Writing Elegant T-SQL Queries
Chapter 6: Discovering T-SQL Anti- Patterns in Depth
Part 3: Assembling Our Query Troubleshooting Toolbox
Chapter 7: Building Diagnostic Queries Using DMVs and DMFs
Chapter 8: Building XEvent Profiler Traces
Chapter 9: Comparative Analysis of Query Plans
Chapter 10: Tracking Performance History with Query Store
Chapter 11: Troubleshooting Live Queries
Chapter 12: Managing Optimizer Changes
Index