

The importance of parameters
As we discussed in the previous section on caching methods, the primary reason to parameterize queries is to ensure that query execution plans get reused – but why is this important and what other reasons might there be to use parameters?
Security
One reason for using parameterized queries is for security. Using a properly formatted parameterized query can protect against SQL injection attacks. A SQL injection attack is one where a malicious user can execute database code (in this case, T-SQL) on a server by appending it to a data entry field in the application. As an example, assume we have an application that contains a form that asks the user to enter their name into a text box. If the application were to use an ad hoc statement to insert this data into the database, it would generally concatenate a T-SQL string with the user input, as in the following code:
DECLARE @sql nvarchar(MAX);
SET @sql = N'INSERT Users (Name) VALUES (''' + <user input> + ''');';
EXECUTE (@sql); A malicious user might enter the following value into the text box:
Bob'); DROP TABLE Users; --
If this is the case, the actual code that gets sent to the SQL Database Engine would look like the following:
INSERT Users (Name) VALUES ('Bob'); DROP TABLE Users; --'); This is a valid T-SQL syntax that would successfully execute. It would first insert a row into the Users table with the Name column set to 'Bob', then it would drop the Users table. This would of course break the application, and unless there was some sort of auditing in place, we would never know what happened.
Let’s look at this example again using a parameterized query. The code might look like the following:
EXECUTE sp_executesql @stmt = N'INSERT Users (Name) VALUES (@name)', @params = N'@name nvarchar(100)', @name = <user input>
This time, if the user were to send the same input, rather than executing the query that the user embedded in the string, the Database Engine would insert a row into the Users table with the Name column set to 'Bob'); DROP TABLE Users; --'. This would obviously look a bit strange, but it wouldn’t break the application nor breach security.
Performance
Another reason to leverage parameters is performance. In a busy SQL system, particularly one that has a primarily Online Transaction Processing (OLTP) workload, we may have hundreds or even thousands of queries executing per second.
Assume that each one of these queries takes about 100 ms to compile and consumes about the same amount of CPU. This would mean that each second on the system, the server could be consuming hundreds of seconds of CPU time just compiling queries. That’s a lot of resources to consume just for preparing the queries for execution, and it doesn’t leave a lot of overhead for actually executing them.
Also recall that when plans are not reused, the procedure cache can become very large and consume memory that in turn won’t be available for storing data and executing queries. In short, a system that spends too much time compiling queries may become CPU and/or memory bound and may perform poorly.
Parameter sniffing
Given that query plan reuse is so important, why wouldn’t the SQL Database Engine parameterize every query that comes in by default? One of the reasons for this is to avoid query performance issues that may result from parameter sniffing. Parameter sniffing is something the SQL Database Engine does in order to optimize a parameterized query. The first time a stored procedure or other parameterized query executes, the input parameter values are used to drive the optimization process and produce the execution plan, as discussed in the Query optimization essentials section.
That execution plan will then be cached and reused by subsequent executions of the procedure or query. For most queries, this is a good thing because using a specific value will result in a more accurate cost estimation. In some situations, however, particularly where the data distribution is skewed in some way, the parameters that are sent the first time the query is executed may not represent the typical use case of the query, and the plan that is generated may perform poorly when other parameter values are sent. This is a case where reusing a plan might not be a good thing, because the plan is highly sensitive to user-defined runtime parameters that have widely different data distributions for the same column.
Parameter sniffing, or parameter sensitivity, is a very common cause of plan variability and performance issues in the SQL Database Engine.
Parameter Sensitive Plan Optimization
SQL Server 2022 introduces the Parameter Sensitive Plan Optimization feature (commonly referred to as PSP Optimization), which allows the Database Engine to simultaneously cache multiple plans for a single parameterized query that uses equality predicates.
With PSP Optimization, during the initial compilation of a parameterized query, the Query Optimizer will evaluate up to three parameters that are likely sensitive to non-uniform (skewed) data distributions. The feature uses the statistics histograms to search for where the cardinality difference between the least-occurring value and the most-occurring value for a given column is orders of magnitude off. The result is the creation of what is called a dispatcher plan, which contains the logic (dispatcher expression) that bucketizes the predicates’ values, upon which different plan variants can be compiled independently.
For each cardinality bucket, a query plan variant will only be compiled if needed, based on actual runtime parameters. If the parameter values that would result in a given plan variant are never used at runtime, then that variant of the plan defined in the dispatcher plan will never actually get compiled. This behavior prevents plan-cache bloating by compiling a plan only if and when its predicate value demands it.
The following diagram shows the possible plan variants found for a parameterized query with a WHERE person.ID = @param search predicate:
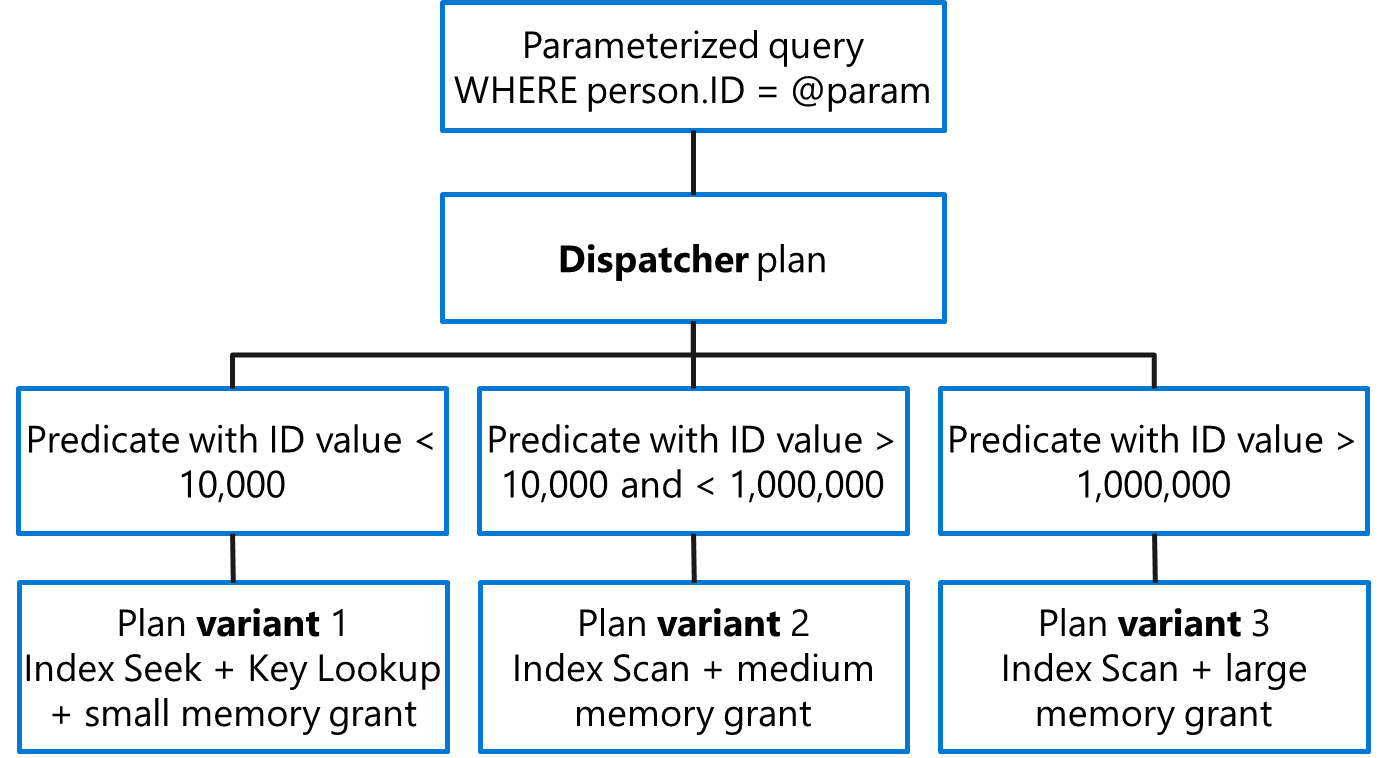
Figure 1.11: Example of a dispatcher plan defining three query plan variants
We will discuss parameter sensitivity behavior in more detail later in this book, in Chapter 5, Writing Elegant T-SQL Queries, and Chapter 6, Discovering T-SQL Anti-Patterns in Depth.
To cache or not to cache
In general, caching and reusing query plans is a good thing, and writing T-SQL code that encourages plan reuse is recommended.
In some cases, such as with a reporting or OLAP workload, caching queries might make less sense. These types of systems tend to have a heavy ad hoc workload. The queries that run are typically long-running and, while they may consume a large amount of resources in a single execution, they typically run with less frequency than OLTP systems. Since these queries tend to be long-running, saving a few hundred milliseconds by reusing a cached plan doesn’t make as much sense as creating a new plan that is designed specifically for that execution of the query. Spending that time compiling a new plan may even result in saving more time in the long run, since a fresh plan will likely perform better than a plan that was generated based on a different set of parameter values.
In summary, for most workloads in the SQL Database Engine, leveraging stored procedures and/or parameterized queries is recommended to encourage plan reuse. For workloads that have heavy ad hoc queries and/or long-running reporting-style queries, consider enabling the optimize for ad hoc workloads server setting and leveraging the RECOMPILE hint to guarantee a new plan for each execution (provided that the queries are run with a low frequency), or use forced parameterization to improve plan reuse opportunities. Also, be sure to review Chapter 8, Building Diagnostic Queries Using DMVs and DMFs, for techniques to identify single-use plans, monitor for excessive recompilation, and identify plan variability and potential parameter sniffing issues.