

Using TL with Transformers
TL is a field of Artificial Intelligence (AI) and ML that aims to make models reusable for different tasks—for example, a model trained on a given task such as A is reusable (fine-tuning) on a different task such as B. In an NLP field, this is achievable by using Transformer-like architectures that can capture the understanding of language itself by language modeling. Such models are called language models—they provide a model for the language they have been trained on. TL is not a new technique, and it has been used in various fields such as computer vision. ResNet, Inception, VGG, and EfficientNet are examples of such models that can be used as pre-trained models able to be fine-tuned on different computer-vision tasks.
Shallow TL using models such as Word2vec, GloVe, and Doc2vec is also possible in NLP. It is called shallow because there is no model behind this kind of TL and instead, the pre-trained vectors for words/tokens are utilized. You can use these token- or document-embedding models followed by a classifier or use them combined with other models such as RNNs instead of using random embeddings.
TL in NLP using Transformer models is also possible because these models can learn a language itself without any labeled data. Language modeling is a task used to train transferable weights for various problems. Masked language modeling is one of the methods used to learn a language itself. As with Word2vec's window-based model for predicting center tokens, in masked language modeling, a similar approach takes place, with key differences. Given a probability, each word is masked and replaced with a special token such as [MASK]. The language model (a Transformer-based model, in our case) must predict the masked words. Instead of using a window, unlike with Word2vec, a whole sentence is given, and the output of the model must be the same sentence with masked words filled.
One of the first models that used the Transformer architecture for language modeling is BERT, which is based on the encoder part of the Transformer architecture. Masked language modeling is accomplished by BERT by using the same method described before and after training a language model. BERT is a transferable language model for different NLP tasks such as token classification, sequence classification, or even question answering.
Each of these tasks is a fine-tuning task for BERT once a language model is trained. BERT is best known for its key characteristics on the base Transformer encoder model, and by altering these characteristics, different versions of it—small, tiny, base, large, and extra-large—are proposed. Contextual embedding enables a model to have the correct meaning of each word based on the context in which it is given—for example, the word Cold can have different meanings in two different sentences: Cold-hearted killer and Cold weather. The number of layers at the encoder part, the input dimension, the output embedding dimension, and the number of multi-head attention mechanisms are these key characteristics, as illustrated in the following screenshot:
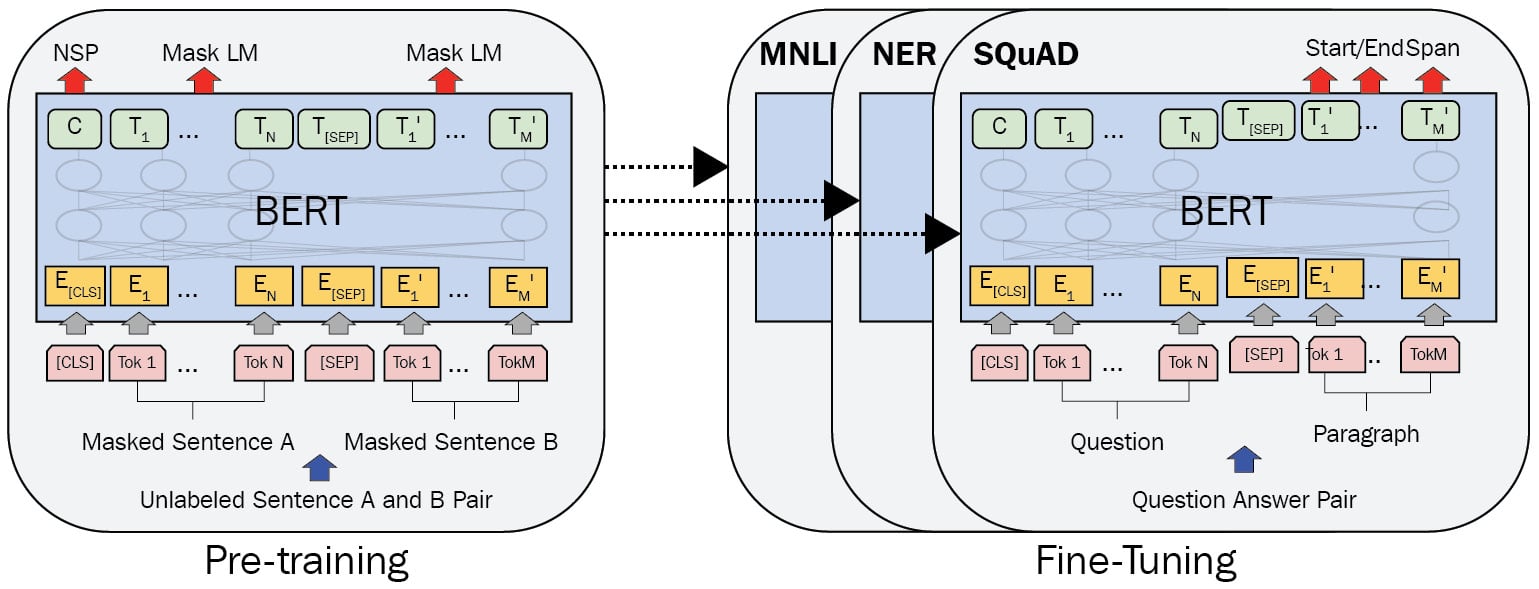
Figure 1.21 – Pre-training and fine-tuning procedures for BERT (Image inspired from J. Devlin et al., Bert: Pre-training of deep bidirectional Transformers for language understanding, 2018)
As you can see in Figure 1.21, the pre-training phase also consists of another objective known as next-sentence prediction. As we know, each document is composed of sentences followed by each other, and another important part of training for a model to grasp the language is to understand the relations of sentences to each other—in other words, whether they are related or not. To achieve these tasks, BERT introduced special tokens such as [CLS] and [SEP]. A [CLS] token is an initially meaningless token used as a start token for all tasks, and it contains all information about the sentence. In sequence-classification tasks such as NSP, a classifier on top of the output of this token (output position of 0) is used. It is also useful in evaluating the sense of a sentence or capturing its semantics—for example, when using a Siamese BERT model, comparing these two [CLS] tokens for different sentences by a metric such as cosine-similarity is very helpful. On the other hand, [SEP] is used to distinguish between two sentences, and it is only used to separate two sentences. After pre-training, if someone aims to fine-tune BERT on a sequence-classification task such as sentiment analysis, which is a sequence-classification task, they will use a classifier on top of the output embedding of [CLS]. It is also notable that all TL models can be frozen during fine-tuning or freed; frozen means seeing all weights and biases inside the model as constants and stopping training on them. In the example of sentiment analysis, just the classifier will be trained, not the model if it is frozen.