-
Book Overview & Buying

-
Table Of Contents

Python Real-World Projects
By :
Python Real-World Projects
By:
Overview of this book
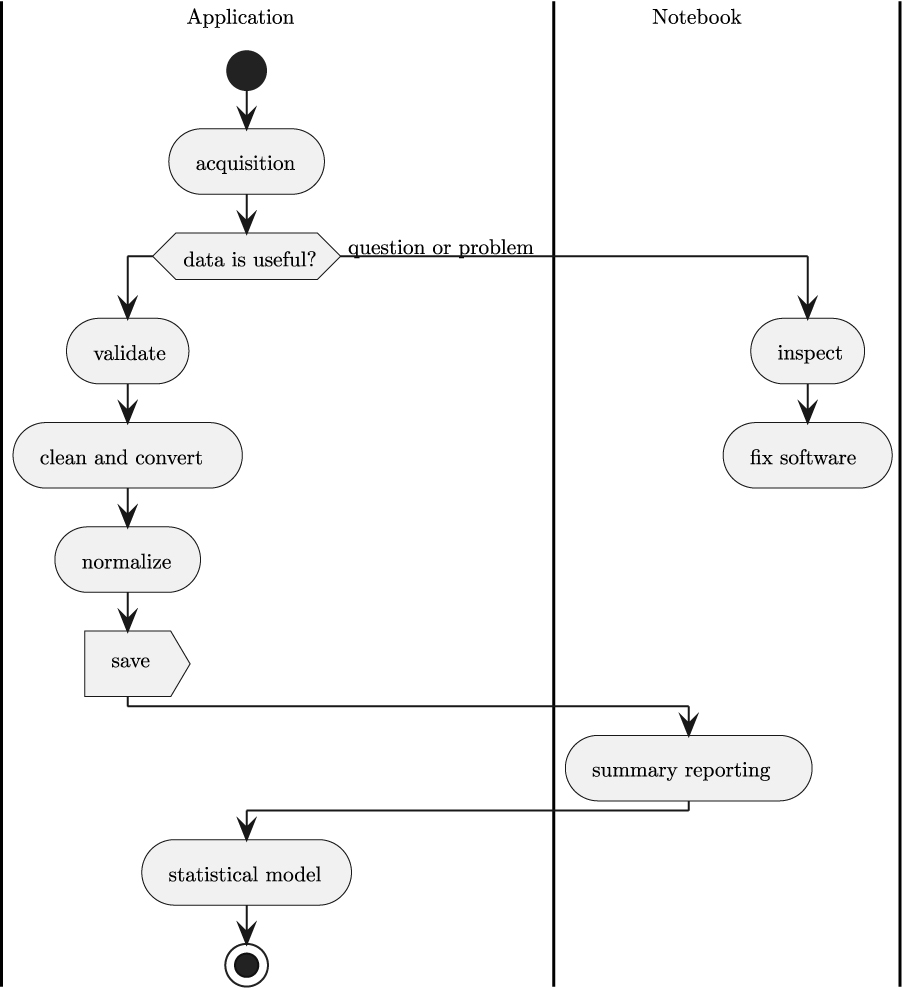
In today's competitive job market, a project portfolio often outshines a traditional resume. Python Real-World Projects empowers you to get to grips with crucial Python concepts while building complete modules and applications. With two dozen meticulously designed projects to explore, this book will help you showcase your Python mastery and refine your skills. Tailored for beginners with a foundational understanding of class definitions, module creation, and Python's inherent data structures, this book is your gateway to programming excellence. You’ll learn how to harness the potential of the standard library and key external projects like JupyterLab, Pydantic, pytest, and requests. You’ll also gain experience with enterprise-oriented methodologies, including unit and acceptance testing, and an agile development approach. Additionally, you’ll dive into the software development lifecycle, starting with a minimum viable product and seamlessly expanding it to add innovative features. By the end of this book, you’ll be armed with a myriad of practical Python projects and all set to accelerate your career as a Python programmer.
Table of Contents (20 chapters)
Preface

Chapter 1: Project Zero: A Template for Other Projects
 Free Chapter
Free Chapter
Chapter 2: Overview of the Projects
Chapter 3: Project 1.1: Data Acquisition Base Application
Chapter 4: Data Acquisition Features: Web APIs and Scraping
Chapter 5: Data Acquisition Features: SQL Database
Chapter 6: Project 2.1: Data Inspection Notebook
Chapter 7: Data Inspection Features
Chapter 8: Project 2.5: Schema and Metadata
Chapter 9: Project 3.1: Data Cleaning Base Application
Chapter 10: Data Cleaning Features
Chapter 11: Project 3.7: Interim Data Persistence
Chapter 12: Project 3.8: Integrated Data Acquisition Web Service
Chapter 13: Project 4.1: Visual Analysis Techniques
Chapter 14: Project 4.2: Creating Reports
Chapter 15: Project 5.1: Modeling Base Application
Chapter 16: Project 5.2: Simple Multivariate Statistics
Chapter 17: Next Steps
Other Books You Might Enjoy
Index