Great open source software almost always comes about because one or more clever developers had a problem to solve and no viable or cost effective solution available. Django is no exception. Adrian and Jacob have long since retired from the project, but the fundamentals of what drove them to create Django live on. It is this solid base of real-world experience that has made Django as successful as it is. In recognition of their contribution, I think it best we let them introduce Django in their own words (edited and reformatted from the original book).
By Adrian Holovaty and Jacob Kaplan-Moss-December 2009
In the early days, web developers wrote every page by hand. Updating a website meant editing HTML; a redesign involved redoing every single page, one at a time. As websites grew and became more ambitious, it quickly became obvious that that approach was tedious, time-consuming, and ultimately untenable.
A group of enterprising hackers at National Center for Supercomputing Applications (the NCSA where Mosaic, the first graphical web browser, was developed) solved this problem by letting the web server spawn external programs that could dynamically generate HTML. They called this protocol the Common Gateway Interface (CGI), and it changed the web forever. It's hard now to imagine what a revelation CGI must have been: instead of treating HTML pages as simple files on disk, CGI allows you to think of your pages as resources generated dynamically on demand.
The development of CGI ushered in the first generation of dynamic websites. However, CGI has its problems: CGI scripts need to contain a lot of repetitive boilerplate code, they make code reuse difficult, and they can be difficult for first-time developers to write and understand.
PHP fixed many of these problems, and it took the world by storm—it is now the most popular tool used to create dynamic websites, and dozens of similar languages (ASP, JSP, and so on.) followed PHP's design closely. PHP's major innovation is its ease of use: PHP code is simply embedded into plain HTML; the learning curve for someone who already knows HTML is extremely shallow.
But PHP has its own problems; it is very ease of use encourages sloppy, repetitive, ill-conceived code. Worse, PHP does little to protect programmers from security vulnerabilities, and thus many PHP developers found themselves learning about security only once it was too late.
These and similar frustrations led directly to the development of the current crop of third-generation web development frameworks. With this new explosion of web development comes yet another increase in ambition; web developers are expected to do more and more every day.
Django was invented to meet these new ambitions.
Django grew organically from real-world applications written by a web development team in Lawrence, Kansas, USA. It was born in the fall of 2003, when the web programmers at the Lawrence Journal-World newspaper, Adrian Holovaty, and Simon Willison, began using Python to build applications.
The World Online team, responsible for the production and maintenance of several local news sites, thrived in a development environment dictated by journalism deadlines. For the sites—including LJWorld.com, Lawrence.com, and KUsports.com—journalists (and management) demanded that features be added and entire applications be built on an intensely fast schedule, often with only day's or hour's notice. Thus, Simon and Adrian developed a time-saving web development framework out of necessity—it was the only way they could build maintainable applications under the extreme deadlines.
In summer 2005, after having developed this framework to a point where it was efficiently powering most of World Online's sites, the team, which now included Jacob Kaplan-Moss, decided to release the framework as open source software. They released it in July 2005 and named it Django, after the jazz guitarist Django Reinhardt.
This history is relevant because it helps explain two key things. The first is Django's "sweet spot." Because Django was born in a news environment, it offers several features (such as its admin site, covered in Chapter 5, The
Django
Admin
Site) that are particularly well suited for "content" sites such as Amazon.com, craigslist.org, and washingtonpost.com that offer dynamic and database-driven information.
Don't let that turn you off, though Django is particularly good for developing those sorts of sites, that doesn't preclude it from being an effective tool for building any sort of dynamic website. (There's a difference between being particularly effective at something and being ineffective at other things.)
The second matter to note is how Django's origins have shaped the culture of its open source community. Because Django was extracted from real-world code, rather than being an academic exercise or commercial product, it is acutely focused on solving web development problems that Django's developers themselves have faced—and continue to face. As a result, Django itself is actively improved on an almost daily basis. The framework's maintainers have a vested interest in making sure Django saves developers time, produces applications that are easy to maintain and performs well under load.
Django lets you build deep, dynamic, interesting sites in an extremely short time. Django is designed to let you focus on the fun, interesting parts of your job while easing the pain of the repetitive bits. In doing so, it provides high-level abstractions of common web development patterns, shortcuts for frequent programming tasks, and clear conventions on how to solve problems. At the same time, Django tries to stay out of your way, letting you work outside the scope of the framework as needed.
We wrote this book because we firmly believe that Django makes web development better. It's designed to quickly get you moving on your own Django projects, and then ultimately teach you everything you need to know to successfully design, develop, and deploy a site that you'll be proud of.
Getting Started
There are two very important things you need to do to get started with Django:
- Install Django (obviously); and
- Get a good understanding of the Model-View-Controller (MVC) design pattern.
The first, installing Django, is really simple and detailed in the first part of this chapter. The second is just as important, especially if you are a new programmer or coming from using a programming language that does not clearly separate the data and logic behind your website from the way it is displayed. Django's philosophy is based on loose coupling, which is the underlying philosophy of MVC. We will be discussing loose coupling and MVC in much more detail as we go along, but if you don't know much about MVC, then you best not skip the second half of this chapter because understanding MVC will make understanding Django so much easier.
Before you can start learning how to use Django, you must first install some software on your computer. Fortunately, this is a simple three step process:
- Install Python.
- Install a Python Virtual Environment.
- Install Django.
If this does not sound familiar to you don't worry, in this chapter, lets assume that you have never installed software from the command line before and will lead you through it step by step.
I have written this section for those of you running Windows. While there is a strong *nix and OSX user base for Django, most new users are on Windows. If you are using Mac or Linux, there are a large number of resources on the Internet; with the best place to start being Django's own installation instructions. For more information visit https://docs.djangoproject.com/en/1.8/topics/install/.
For Windows users, your computer can be running any recent version of Windows (Vista, 7, 8.1, or 10). This chapter also assumes you're installing Django on a desktop or laptop computer and will be using the development server and SQLite to run all the example code in this book. This is by far the easiest and the best way to setup Django when you are first starting out.
If you do want to go to a more advanced installation of Django, your options are covered in Chapter 13
, Deploying Django, Chapter 20, More on Installing Django, and Chapter 21
, Advanced Database Management.
Note
If you are using Windows, I recommend that you try out Visual Studio for all your Django development. Microsoft has made a significant investment in providing support for Python and Django programmers. This includes full IntelliSense support for Python/Django and incorporation of all of Django's command line tools into the VS IDE.
Best of all it's entirely free. I know, who would have expected that from M$??, but it's true!
See Appendix G, Developing Django with Visual Studio for a complete installation guide for Visual Studio Community 2015, as well as a few tips on developing Django in Windows.
Django itself is written purely in Python, so the first step in installing the framework is to make sure you have Python installed.
Django version 1.8 LTS works with Python version 2.7, 3.3, 3.4 and 3.5. For each version of Python, only the latest micro release (A.B.C) is supported.
If you are just trialling Django, it doesn't really matter whether you use Python 2 or Python 3. If, however, you are planning on eventually deploying code to a live website, Python 3 should be your first choice. The Python wiki (for more information visit https://wiki.python.org/moin/Python2orPython3, puts the reason behind this very succinctly:
Short version: Python 2.x is legacy, Python 3.x is the present and future of the language
Unless you have a very good reason to use Python 2 (for example, legacy libraries), Python 3 is the way to go.
Tip
NOTE: All of the code samples in this book are written in Python 3
If you're on Linux or Mac OS X, you probably have Python already installed. Type python at a command prompt (or in Applications/Utilities/Terminal, in OS X). If you see something like this, then Python is installed:
Python 2.7.5 (default, June 27 2015, 13:20:20)
[GCC x.x.x] on xxx
Type "help", "copyright", "credits" or "license" for more
information.
Note
You can see that, in the preceding example, Python interactive mode is running Python 2.7. This is a trap for inexperienced users. On Linux and Mac OS X machines, it is common for both Python 2 and Python 3 to be installed. If your system is like this, you need to type python3 in front of all your commands, rather than python to run Django with Python 3.
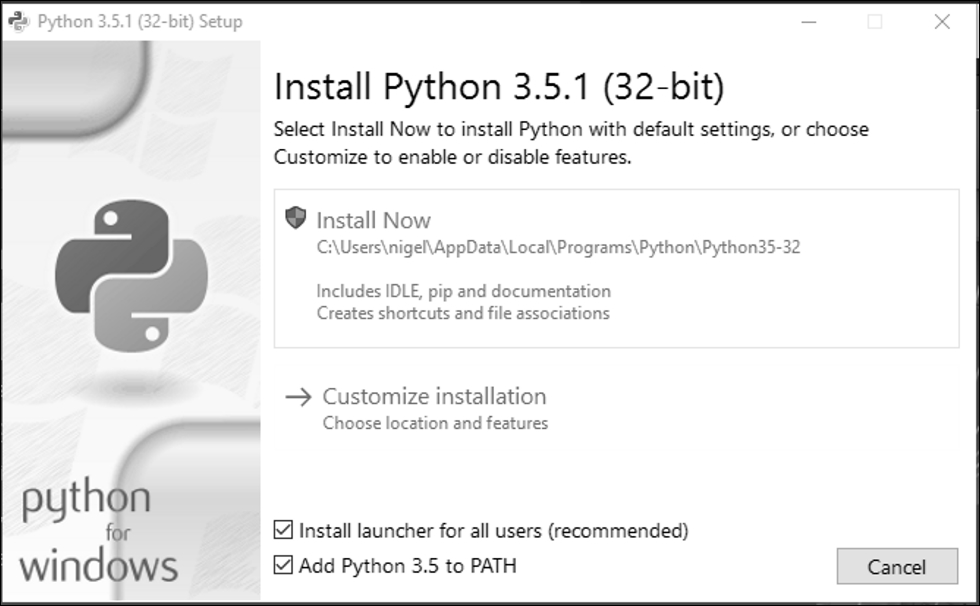
Assuming Python is not installed on your system, we first need to get the installer. Go to https://www.python.org/downloads/, and click the big yellow button that says Download Python 3.x.x.
At the time of writing, the latest version of Python is 3.5.1, but it may have been updated by the time you read this, so the numbers may be slightly different.
DO NOT download version 2.7.x as this is the old version of Python. All of the code in this book is written in Python 3, so you will get compilation errors if you try to run the code on Python 2.
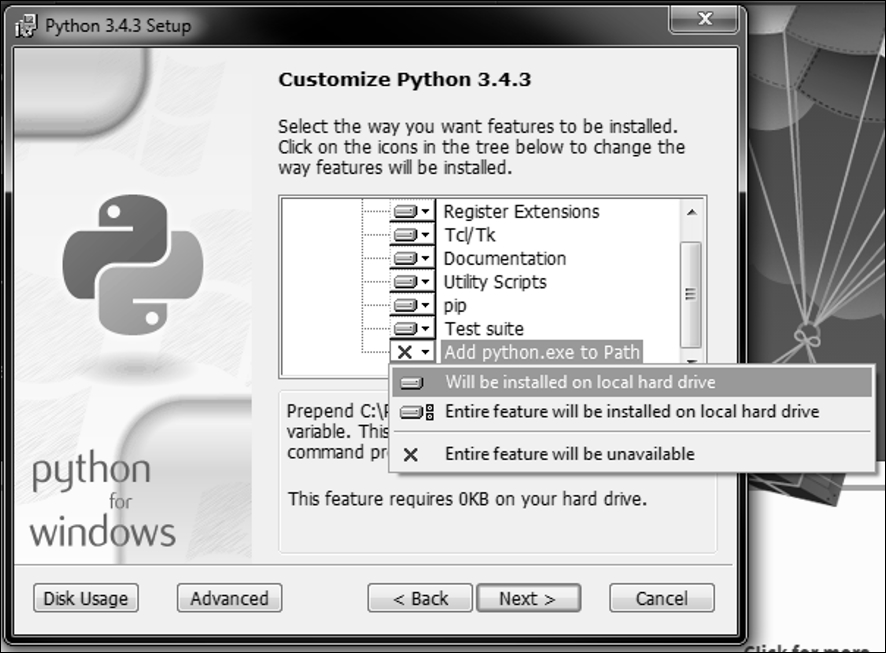
Once you have downloaded the Python installer, go to your Downloads folder and double-click the file python-3.x.x.msi to run the installer. The installation process is the same as any other Windows program, so if you have installed software before, there should be no problem here, however, the is one extremely important customization you must make.
Note
Do not forget this next step as it will solve most problems that arise from an incorrect mapping of pythonpath (an important variable for Python installations) in Windows.
By default, the Python executable is not added to the Windows PATH statement. For Django to work properly, Python must be listed in the PATH statement. Fortunately, this is easy to rectify:
Once Python is installed, you should be able to re-open the command window and type python at the command prompt and get something like this:
Python 3.5.1 (v3.5.1:37a07cee5969, Dec 6 2015, 01:38:48)
[MSC v.1900 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more
information.
>>>
While you are at it, there is one more important thing to do. Exit out of Python with CTRL+C. At the command prompt type, the following and hit enter:
python-m pip install-U pip
The output will be something similar to this:
C:\Users\nigel>python -m pip install -U pip
Collecting pip
Downloading pip-8.1.2-py2.py3-none-any.whl (1.2MB)
100% |################################| 1.2MB 198kB/s
Installing collected packages: pip
Found existing installation: pip 7.1.2
Uninstalling pip-7.1.2:
Successfully uninstalled pip-7.1.2
Successfully installed pip-8.1.2
You don't need to understand exactly what this command does right now; put briefly pip is the Python package manager. It's used to install Python packages: pip is actually a recursive acronym for Pip Installs Packages. Pip is important for the next stage of our install process, but first, we need to make sure we are running the latest version of pip (8.1.2 at the time of writing), which is exactly what this command does.
Installing a Python Virtual Environment
Note
If you are going to use Microsoft Visual Studio (VS), you can stop here and jump to Appendix G, Developing Django with Visual Studio. VS only requires that you install Python, everything else VS does for you from inside the Integrated Development Environment (IDE).
All of the software on your computer operates interdependently—each program has other bits of software that it depends on (called dependencies) and settings that it needs to find the files and other software it needs to run (called environment variables).
When you are writing new software programs, it is possible (and common!) to modify dependencies and environment variables that your other software depends on. This can cause numerous problems, so should be avoided.
A Python virtual environment solves this problem by wrapping all the dependencies and environment variables that your new software needs into a file system separate from the rest of the software on your computer.
Note
Some of you who have looked at other tutorials will note that this step is often described as optional. This is not a view I support, nor is it supported by a number of Django's core developers.
Note
The advantages of developing Python applications (of which Django is one) within a virtual environment are manifest and not worth going through here. As a beginner, you just need to take my word for it—running a virtual environment for Django development is not optional.
The virtual environment tool in Python is called virtualenv and we install it from the command line using pip:
pip install virtualenv
The output from your command window should look something like this:
C:\Users\nigel>pip install virtualenv
Collecting virtualenv
Downloading virtualenv-15.0.2-py2.py3-none-any.whl (1.8MB)
100% |################################| 1.8MB 323kB/s
Installing collected packages: virtualenv
Successfully installed virtualenv-15.0.2
Once virtualenv is installed, you need to create a virtual environment for your project by typing:
virtualenv env_mysite
Note
Most examples on the Internet use env as your environment name. This is bad; principally because it's common to have several virtual environments installed to test different configurations, and env is not very descriptive. For example, you may be developing an application that must run on Python 2.7 and Python 3.4. Environments named env_someapp_python27 and env_someapp_python34 are going to be a lot easier to distinguish than if you had named them env and env1.
In this example, I have kept it simple as we will only be using one virtual environment for our project, so I have used env_mysite. The output from your command should look something like this:
C:\Users\nigel>virtualenv env_mysite
Using base prefix
'c:\\users\\nigel\\appdata\\local\\programs\\python\\python35-32'
New python executable in
C:\Users\nigel\env_mysite\Scripts\python.exe
Installing setuptools, pip, wheel...done.
Once virtualenv has finished setting up your new virtual environment, open Windows Explorer and have a look at what virtualenv created for you. In your home directory, you will now see a folder called \env_mysite (or whatever name you gave the virtual environment). If you open the folder, you will see the following:
\Include
\Lib
\Scripts
\src
virtualenv has created a complete Python installation for you, separate from your other software, so you can work on your project without affecting any of the other software on your system.
To use this new Python virtual environment, we have to activate it, so let's go back to the command prompt and type the following:
env_mysite\scripts\activate
This will run the activate script inside your virtual environment's \scripts folder. You will notice your command prompt has now changed:
(env_mysite) C:\Users\nigel>
The (env_mysite) at the beginning of the command prompt lets you know that you are running in the virtual environment. Our next step is to install Django.
Now that we have Python and are running a virtual environment, installing Django is super easy, just type the command:
pip install django==1.8.13
This will instruct pip to install Django into your virtual environment. Your command output should look like this:
(env_mysite) C:\Users\nigel>pip install django==1.8.13
Collecting django==1.8.13
Downloading Django-1.8.13-py2.py3-none-any.whl (6.2MB)
100% |################################| 6.2MB 107kB/s
Installing collected packages: django
Successfully installed django-1.8.13
In this case, we are explicitly telling pip to install Django 1.8.13, which is the latest version of Django 1.8 LTS at the time of writing. If you are installing Django, it's good practice to check the Django Project website for the latest version of Django 1.8 LTS.
Note
In case you were wondering, typing in pip install django will install the latest stable release of Django. If you want information on installing the latest development release of Django, see Chapter 20, More
On Installing
Django.
For some post-installation positive feedback, take a moment to test whether the installation worked. At your virtual environment command prompt, start the Python interactive interpreter by typing python and hitting enter. If the installation was successful, you should be able to import the module django:
(env_mysite) C:\Users\nigel>python
Python 3.5.1 (v3.5.1:37a07cee5969, Dec 6 2015, 01:38:48)
[MSC v.1900 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more
information.
>>> import django
>>> django.get_version()
1.8.13'
This step is not necessary in order to complete any of the examples in this book. Django comes with SQLite installed by default. SQLite requires no configuration on your part. If you would like to work with a large database engines like PostgreSQL, MySQL, or Oracle, see Chapter 21, Advanced Database Management.
Once you've installed Python, Django and (optionally) your database server/library, you can take the first step in developing a Django application by creating a project.
A project is a collection of settings for an instance of Django. If this is your first time using Django, you'll have to take care of some initial setup. Namely, you'll need to auto-generate some code that establishes a Django project: a collection of settings for an instance of Django, including database configuration, Django-specific options, and application-specific settings.
I am assuming at this stage you are still running the virtual environment from the previous installation step. If not, you will have to start it again with:
env_mysite\scripts\activate\
From your virtual environment command line, run the following command:
django-admin startproject mysite
This will create a mysite directory in your current directory (in this case \env_mysite\). If you want to create your project in a directory other than the root, you can create a new directory, change into that directory and run the startproject command from there.
Note
Warning!
You'll need to avoid naming projects after built-in Python or Django components. In particular, this means you should avoid using names such as "django" (which will conflict with Django itself) or "test" (which conflicts with a built-in Python package).
Let's look at what startproject created:
mysite/
manage.py
mysite/
__init__.py
settings.py
urls.py
wsgi.py
These files are:
- The outer
mysite/ root directory. It's just a container for your project. Its name doesn't matter to Django; you can rename it to anything you like. manage.py, a command-line utility that lets you interact with your Django project in various ways. You can read all the details about manage.py on the Django Project website (for more information visit https://docs.djangoproject.com/en/1.8/ref/django-admin/).- The inner
mysite/ directory. It's the Python package for your project. It's the name you'll use to import anything inside it (for example, mysite.urls). mysite/__init__.py, an empty file that tells Python that this directory should be considered a Python package. (Read more about packages in the official Python docs at https://docs.python.org/tutorial/modules.html#packages, if you're a Python beginner.mysite/settings.py, settings/configuration for this Django project. Appendix D, Settings will tell you all about how settings work.mysite/urls.py, the URL declarations for this Django project; a table of contents of your Django-powered site. You can read more about URLs in Chapter 2, Views and Urlconfs and Chapter 7, Advanced Views and Urlconfs.mysite/wsgi.py, an entry-point for WSGI-compatible web servers to serve your project. See Chapter 13, Deploying Django, for more details.
Now, edit mysite/settings.py. It's a normal Python module with module-level variables representing Django settings. First step while you're editing settings.py, is to set TIME_ZONE to your time zone. Note the INSTALLED_APPS setting at the top of the file. That holds the names of all Django applications that are activated in this Django instance. Apps can be used in multiple projects, and you can package and distribute them for use by others in their projects. By default, INSTALLED_APPS contains the following apps, all of which come with Django:
django.contrib.admin: The admin site.django.contrib.auth: An authentication system.django.contrib.contenttypes: A framework for content types.django.contrib.sessions: A session framework.django.contrib.messages: A messaging framework.django.contrib.staticfiles: A framework for managing static files.
These applications are included by default as a convenience for the common case. Some of these applications makes use of at least one database table though, so we need to create the tables in the database before we can use them. To do that, run the following command:
python manage.py migrate
The migrate command looks at the INSTALLED_APPS setting and creates any necessary database tables according to the database settings in your settings.py file and the database migrations shipped with the app (we'll cover those later). You'll see a message for each migration it applies.
Let's verify your Django project works. Change into the outer mysite directory, if you haven't already, and run the following commands:
python manage.py runserver
You'll see the following output on the command line:
Performing system checks... 0 errors found
June 12, 2016-08:48:58
Django version 1.8.13, using settings 'mysite.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CTRL-BREAK.
You've started the Django development server, a lightweight web server written purely in Python. We've included this with Django so you can develop things rapidly, without having to deal with configuring a production server—such as Apache—until you're ready for production.
Now's a good time to note: don't use this server in anything resembling a production environment. It's intended only for use while developing.
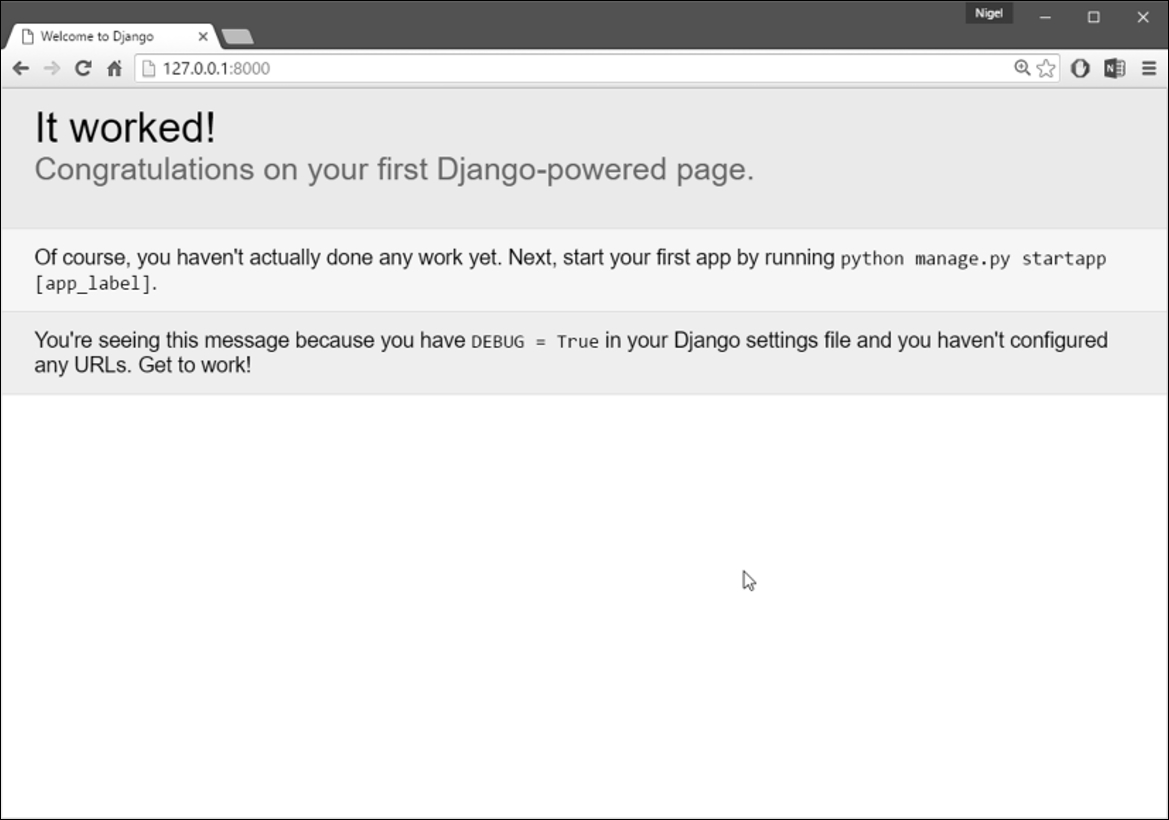
Now that the server's running, visit http://127.0.0.1:8000/ with your web browser. You'll see a "Welcome to Django" page in pleasant, light-blue pastel (Figure 1.3). It worked!
Note
Automatic reloading of runserver
The development server automatically reloads Python code for each request as needed. You don't need to restart the server for code changes to take effect. However, some actions such as adding files don't trigger a restart, so you'll have to restart the server in these cases.
Django's welcome page
The Model-View-Controller (MVC) design pattern
MVC has been around as a concept for a long time, but has seen exponential growth since the advent of the Internet because it is the best way to design client-server applications. All of the best web frameworks are built around the MVC concept. At the risk of starting a flame war, I contest that if you are not using MVC to design web apps, you are doing it wrong. As a concept, the MVC design pattern is really simple to understand:
- The Model(M) is a model or representation of your data. It's not the actual data, but an interface to the data. The model allows you to pull data from your database without knowing the intricacies of the underlying database. The model usually also provides an abstraction layer with your database, so that you can use the same model with multiple databases.
- The View(V) is what you see. It's the presentation layer for your model. On your computer, the view is what you see in the browser for a web app, or the UI for a desktop app. The view also provides an interface to collect user input.
- The Controller(C) controls the flow of information between the model and the view. It uses programmed logic to decide what information is pulled from the database via the model and what information is passed to the view. It also gets information from the user via the view and implements business logic: either by changing the view, or modifying data through the model, or both.
Where it gets difficult is the vastly different interpretations of what actually happens at each layer-different frameworks implement the same functionality in different ways. One framework guru might say a certain function belongs in a view, while another might vehemently defend the need for it to be on the controller.
You, as a budding programmer who Gets Stuff Done, do not have to care about this because, in the end, it doesn't matter. As long as you understand how Django implements the MVC pattern, you are free to move on and get some real work done. Although, watching a flame war in a comment thread can be a highly amusing distraction...
Django follows the MVC pattern closely, however, it does use its own logic in the implementation. Because the C is handled by the framework itself and most of the excitement in Django happens in models, templates and views, Django is often referred to as an MTV framework. In the MTV development pattern:
- M stands for "Model," the data access layer. This layer contains anything and everything about the data: how to access it, how to validate it, which behaviors it has, and the relationships between the data. We will be looking closely at Django's models in Chapter 4, Models.
- T stands for "Template," the presentation layer. This layer contains presentation-related decisions: how something should be displayed on a web page or other type of document. We will explore Django's templates in Chapter 3, Templates.
- V stands for "View," the business logic layer. This layer contains the logic that accesses the model and defers to the appropriate template(s). You can think of it as the bridge between models and templates. We will be checking out Django's views in the next chapter.
This is probably the only unfortunate bit of naming in Django, because Django's view is more like the controller in MVC, and MVC's view is actually a Template in Django. It is a little confusing at first, but as a programmer getting a job done, you really won't care for long. It is only a problem for those of us who have to teach it. Oh, and to the flamers of course.