

Another aspect that we need to consider to evaluate a parallel architecture is memory organization or rather, the way in which the data is accessed. No matter how fast the processing unit is, if the memory cannot maintain and provide instructions and data at a sufficient speed, there will be no improvement in performance. The main problem that must be overcome to make the response time of the memory compatible with the speed of the processor is the memory cycle time, which is defined as the time that has elapsed between two successive operations. The cycle time of the processor is typically much shorter than the cycle time of the memory. When the processor starts transferring data (to or from the memory), the memory will remain occupied for the entire time of the memory cycle: during this period, no other device (I/O controller, processor, or even the processor itself that made the request) can use the memory because it will be committed to respond to the request.
The memory organization in MIMD architecture
Solutions to the problem of access memory resulted in a dichotomy of MIMD architectures. In the first type of system, known as the shared memory system, there is high virtual memory and all processors have equal access to data and instructions in this memory. The other type of system is the distributed memory model, wherein each processor has a local memory that is not accessible to other processors. The difference between shared memory and distributed memory lies in the structure of the virtual memory or the memory from the perspective of the processor. Physically, almost every system memory is divided into distinct components that are independently accessible. What distinguishes a shared memory from a distributed memory is the memory access management by the processing unit. If a processor were to execute the instruction load R0, i, which means load in the R0 register the contents of the memory location i, the question now is what should happen? In a system with shared memory, the i index is a global address and the memory location i is the same for each processor. If two processors were to perform this instruction at the same time, they would load the same information in their registers R0. In a distributed memory system, i is a local address. If two processors were to load the statement R0 at the same time, different values may end up in the respective register's R0, since, in this case, the memory cells are allotted one for each local memory. The distinction between shared memory and distributed memory is very important for programmers because it determines the way in which different parts of a parallel program must communicate. In a system, shared memory is sufficient to build a data structure in memory and go to the parallel subroutine, which are the reference variables of this data structure. Moreover, a distributed memory machine must make copies of shared data in each local memory. These copies are created by sending a message containing the data to be shared from one processor to another. A drawback of this memory organization is that sometimes, these messages can be very large and take a relatively long transfer time.
The schema of a shared memory multiprocessor system is shown in the following figure. The physical connections here are quite simple. The bus structure allows an arbitrary number of devices that share the same channel. The bus protocols were originally designed to allow a single processor, and one or more disks or tape controllers to communicate through the shared memory here. Note that each processor has been associated with a cache memory, as it is assumed that the probability that a processor needs data or instructions present in the local memory is very high. The problem occurs when a processor modifies data stored in the memory system that is simultaneously used by other processors. The new value will pass from the processor cache that has been changed to shared memory; later, however, it must also be passed to all the other processors, so that they do not work with the obsolete value. This problem is known as the problem of cache coherency, a special case of the problem of memory consistency, which requires hardware implementations that can handle concurrency issues and synchronization similar to those having thread programming.
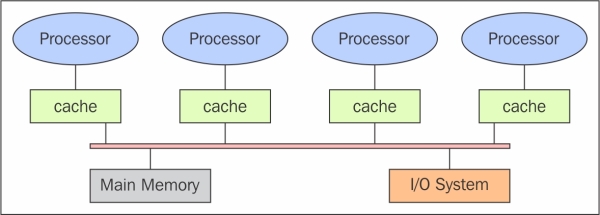
The shared memory architecture schema
The main features of shared memory systems are:
The memory is the same for all processors, for example, all the processors associated with the same data structure will work with the same logical memory addresses, thus accessing the same memory locations.
The synchronization is made possible by controlling the access of processors to the shared memory. In fact, only one processor at a time can have access to the memory resources.
A shared memory location must not be changed from a task while another task accesses it.
Sharing data is fast; the time required for the communication between two tasks is equal to the time for reading a single memory location (it is depending on the speed of memory access).
The memory access in shared memory systems are as follows:
Uniform memory access (UMA): The fundamental characteristic of this system is the access time to the memory that is constant for each processor and for any area of memory. For this reason, these systems are also called as symmetric multiprocessor (SMP). They are relatively simple to implement, but not very scalable; the programmer is responsible for the management of the synchronization by inserting appropriate controls, semaphores, locks, and so on in the program that manages resources.
Non-uniform memory access (NUMA): These architectures divide the memory area into a high-speed access area that is assigned to each processor and a common area for the data exchange, with slower access. These systems are also called as Distributed Shared Memory Systems (DSM). They are very scalable, but complex to develop.
No remote memory access (NORMA): The memory is physically distributed among the processors (local memory). All local memories are private and can only access the local processor. The communication between the processors is through a communication protocol used for exchange of messages, the message-passing protocol.
Cache only memory access (COMA): These systems are equipped with only cache memories. While analyzing NUMA architectures, it was noticed that these architectures kept the local copies of the data in the cache and that these data were stored as duplication in the main memory. This architecture removes duplicates and keeps only the cache memories, the memory is physically distributed among the processors (local memory). All local memories are private and can only access the local processor. The communication between the processors is through a communication protocol for exchange of messages, the message-passing protocol.
In a system with distributed memory, the memory is associated with each processor and a processor is only able to address its own memory. Some authors refer to this type of system as "multicomputer", reflecting the fact that the elements of the system are themselves small complete systems of a processor and memory, as you can see in the following figure:
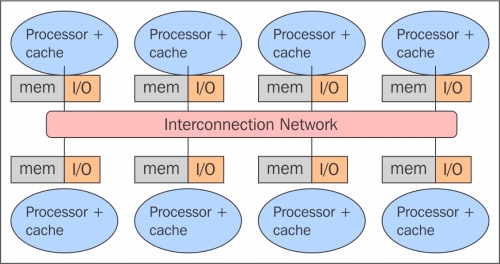
The distributed memory architecture scheme
This kind of organization has several advantages. At first, there are no conflicts at the level of the communication bus or switch. Each processor can use the full bandwidth of their own local memory without any interference from other processors. Secondly, the lack of a common bus means that there is no intrinsic limit to the number of processors, the size of the system is only limited by the network used to connect the processors. Thirdly, there are no problems of cache coherency. Each processor is responsible for its own data and does not have to worry about upgrading any copies. The main disadvantage is that the communication between processors is more difficult to implement. If a processor requires data in the memory of another processor, the two processors should necessarily exchange messages via the message-passing protocol. This introduces two sources of slowdown; to build and send a message from one processor to another takes time, and also, any processor should be stopped in order to manage the messages received from other processors. A program designed to work on a distributed memory machine must be organized as a set of independent tasks that communicate via messages.
Basic message passing
The main features of distributed memory systems are as follows:
Memory is physically distributed between processors; each local memory is directly accessible only by its processor.
Synchronization is achieved by moving data (even if it's just the message itself) between processors (communication).
The subdivision of data in the local memories affects the performance of the machine—it is essential to make a subdivision accurate, so as to minimize the communication between the CPUs. In addition to this, the processor that coordinates these operations of decomposition and composition must effectively communicate with the processors that operate on the individual parts of data structures.
The message-passing protocol is used so that the CPU's can communicate with each other through the exchange of data packets. The messages are discrete units of information; in the sense that they have a well-defined identity, so it is always possible to distinguish them from each other.
MPP machines are composed of hundreds of processors (which can be as large as hundreds of thousands in some machines) that are connected by a communication network. The fastest computers in the world are based on these architectures; some example systems of these architectures are: Earth Simulator, Blue Gene, ASCI White, ASCI Red, and ASCI Purple and Red Storm.
These processing systems are based on classical computers that are connected by communication networks. The computational clusters fall into this classification.
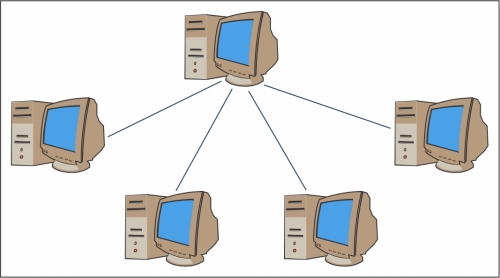
An example of a cluster of workstation architecture
In a cluster architecture, we define a node as a single computing unit that takes part in the cluster. For the user, the cluster is fully transparent—all the hardware and software complexity is masked and data and applications are made accessible as if they were all from a single node.
Here, we've identified three types of clusters:
The fail-over cluster: In this, the node's activity is continuously monitored, and when one stops working, another machine takes over the charge of those activities. The aim is to ensure a continuous service due to the redundancy of the architecture.
The load balancing cluster: In this system, a job request is sent to the node that has less activity. This ensures that less time is taken to complete the process.
The high-performance computing cluster: In this, each node is configured to provide extremely high performance. The process is also divided in multiple jobs on multiple nodes. The jobs are parallelized and will be distributed to different machines.
The introduction of GPU accelerators in the homogeneous world of supercomputing has changed the nature of how supercomputers were both used and programmed previously. Despite the high performance offered by GPUs, they cannot be considered as an autonomous processing unit as they should always be accompanied by a combination of CPUs. The programming paradigm, therefore, is very simple; the CPU takes control and computes in a serial manner, assigning to the graphic accelerator the tasks that are computationally very expensive and have a high degree of parallelism. The communication between a CPU and GPU can take place not only through the use of a high-speed bus, but also through the sharing of a single area of memory for both physical or virtual. In fact, in the case where both the devices are not equipped with their own memory areas, it is possible to refer to a common memory area using the software libraries provided by the various programming models, such as CUDA and OpenCL. These architectures are called heterogeneous architectures, wherein applications can create data structures in a single address space and send a job to the device hardware appropriate for the resolution of the task. Several processing tasks can operate safely on the same regions to avoid data consistency problems, thanks to the atomic operations. So, despite the fact that the CPU and GPU do not seem to work efficiently together, with the use of this new architecture, we can optimize their interaction with and performance of parallel applications.
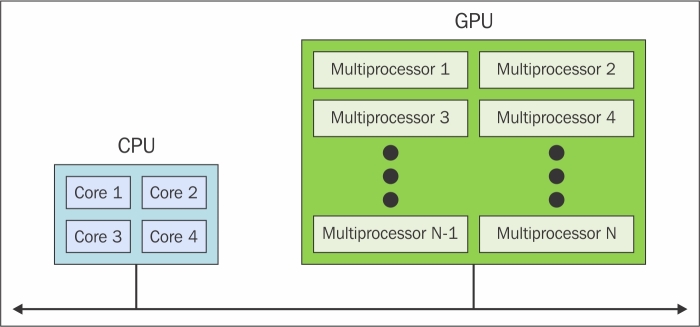
The heterogeneous architecture scheme