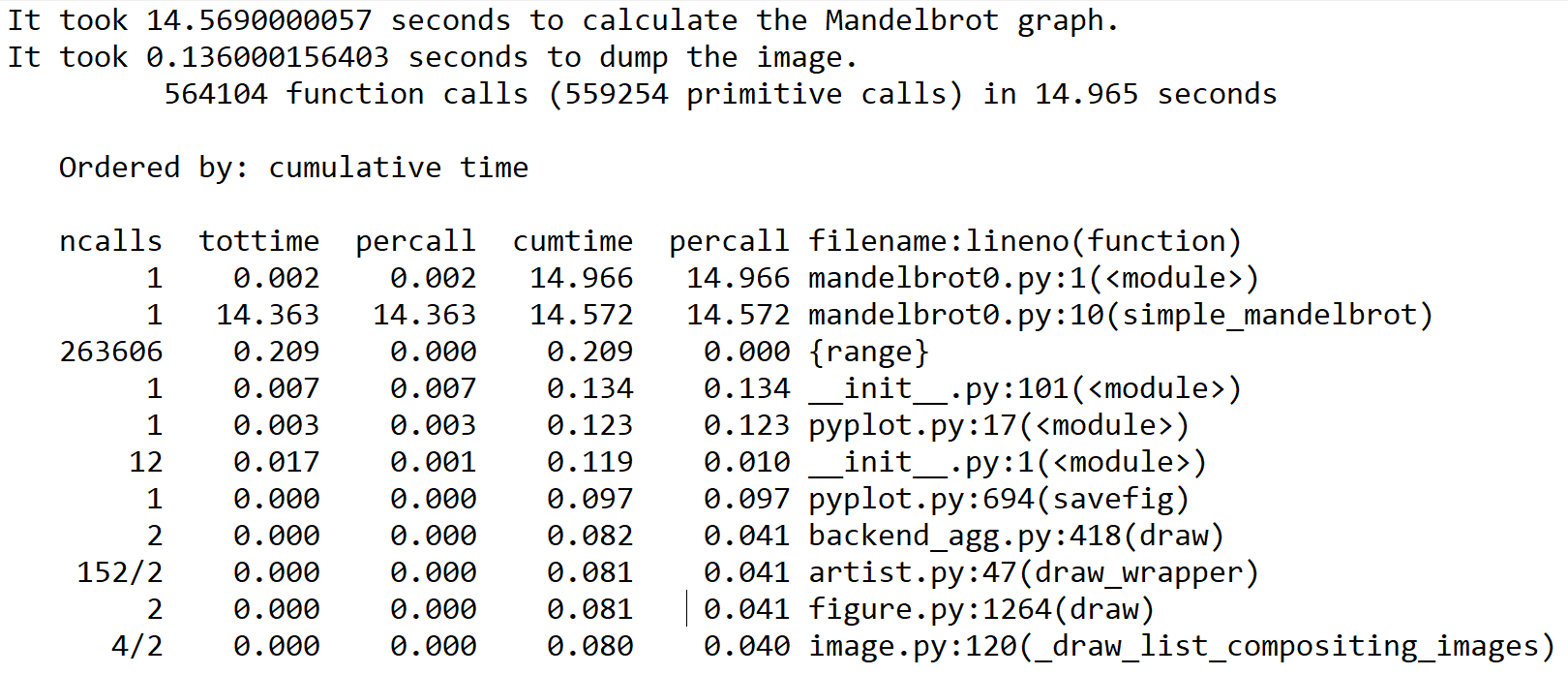
We saw in the previous example that we can individually time different functions and components with the standard time function in Python. While this approach works fine for our small example program, this won't always be feasible for larger programs that call on many different functions, some of which may or may not be worth our effort to parallelize, or even optimize on the CPU. Our goal here is to find the bottlenecks and hotspots of a program—even if we were feeling energetic and used time around every function call we make, we might miss something, or there might be some system or library calls that we don't even consider that happen to be slowing things down. We should find candidate portions of the code to offload onto the GPU before we even think about rewriting the code to run on the GPU; we must always follow the wise words of the famous American computer scientist Donald Knuth: Premature optimization is the root of all evil.
We use what is known as a profiler to find these hot spots and bottlenecks in our code. A profiler will conveniently allow us to see where our program is taking the most time, and allow us to optimize accordingly.