

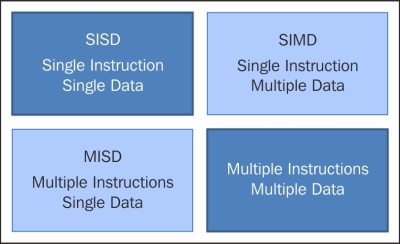
Based on the number of instructions and data that can be processed simultaneously, computer systems are classified into four categories:
Single instruction, single data (SISD)
Single instruction, multiple data (SIMD)
Multiple instruction, single data (MISD)
Multiple instruction, multiple data (MIMD)
This classification is known as Flynn's taxonomy.
The SISD computing system is a uniprocessor machine. It executes a single instruction that operates on a single data stream. In SISD, machine instructions are processed sequentially.
In a clock cycle, the CPU executes the following operations:
Fetch: The CPU fetches the data and instructions from a memory area, which is called a register.
Decode: The CPU decodes the instructions.
Execute: The instruction is carried out on the data. The result of the operation is stored in another register.
Once the execution stage is complete, the CPU sets itself to begin another CPU cycle.

The SISD architecture schema
The algorithms that run on these types of computers are sequential (or serial), since they do not contain any parallelism. Examples of SISD computers are hardware systems with a single CPU.
The main elements of these architectures (Von Neumann architectures) are:
The conventional single processor computers are classified as SISD systems. The following figure specifically shows which areas of a CPU are used in the stages of fetch, decode, and execute:
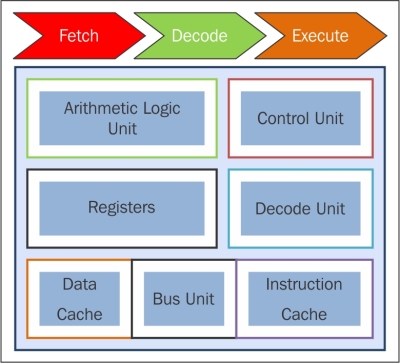
CPU's components in the fetch-decode-execute phase
In this model, n processors, each with their own control unit, share a single memory unit. In each clock cycle, the data received from the memory is processed by all processors simultaneously, each in accordance with the instructions received from its control unit. In this case, the parallelism (instruction-level parallelism) is obtained by performing several operations on the same piece of data. The types of problems that can be solved efficiently in these architectures are rather special, such as those regarding data encryption; for this reason, the computer MISD did not find space in the commercial sector. MISD computers are more of an intellectual exercise than a practical configuration.
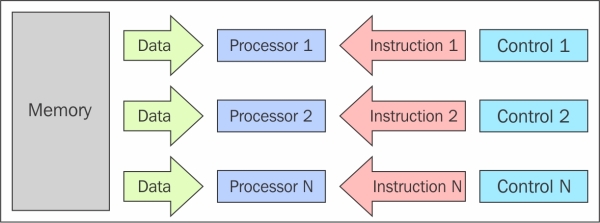
The MISD architecture scheme
A SIMD computer consists of n identical processors, each with its own local memory, where it is possible to store data. All processors work under the control of a single instruction stream; in addition to this, there are n data streams, one for each processor. The processors work simultaneously on each step and execute the same instruction, but on different data elements. This is an example of data-level parallelism. The SIMD architectures are much more versatile than MISD architectures. Numerous problems covering a wide range of applications can be solved by parallel algorithms on SIMD computers. Another interesting feature is that the algorithms for these computers are relatively easy to design, analyze, and implement. The limit is that only the problems that can be divided into a number of subproblems (which are all identical, each of which will then be solved contemporaneously, through the same set of instructions) can be addressed with the SIMD computer. With the supercomputer developed according to this paradigm, we must mention the Connection Machine (1985 Thinking Machine) and MPP (NASA - 1983). As we will see in Chapter 6, GPU Programming with Python, the advent of modern graphics processor unit (GPU), built with many SIMD embedded units has lead to a more widespread use of this computational paradigm.
This class of parallel computers is the most general and more powerful class according to Flynn's classification. There are n processors, n instruction streams, and n data streams in this. Each processor has its own control unit and local memory, which makes MIMD architectures more computationally powerful than those used in SIMD. Each processor operates under the control of a flow of instructions issued by its own control unit; therefore, the processors can potentially run different programs on different data, solving subproblems that are different and can be a part of a single larger problem. In MIMD, architecture is achieved with the help of the parallelism level with threads and/or processes. This also means that the processors usually operate asynchronously. The computers in this class are used to solve those problems that do not have a regular structure that is required by the model SIMD. Nowadays, this architecture is applied to many PCs, supercomputers, and computer networks. However, there is a counter that you need to consider: asynchronous algorithms are difficult to design, analyze, and implement.
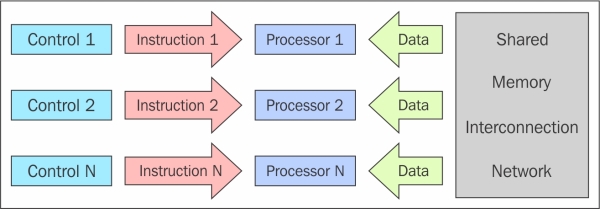
The MIMD architecture scheme