

One of the main constraints of a linear regression model is the fact that it tries to fit a linear function to the input data. The polynomial regression model overcomes this issue by allowing the function to be a polynomial, thereby increasing the accuracy of the model.
Let's consider the following figure:
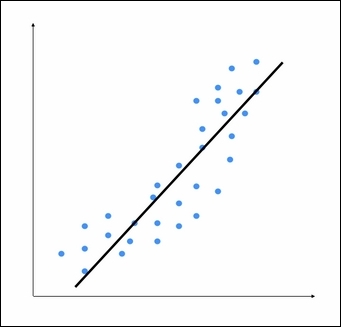
We can see that there is a natural curve to the pattern of datapoints. This linear model is unable to capture this. Let's see what a polynomial model would look like:
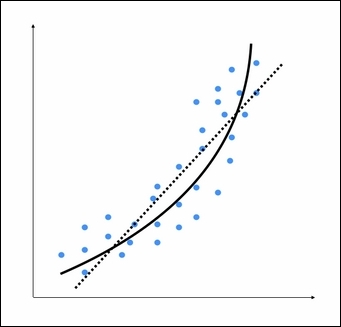
The dotted line represents the linear regression model, and the solid line represents the polynomial regression model. The curviness of this model is controlled by the degree of the polynomial. As the curviness of the model increases, it gets more accurate. However, curviness adds complexity to the model as well, hence, making it slower. This is a trade off where you have to decide between how accurate you want your model to be given the computational constraints.
Add the following lines to
regressor.py:from sklearn.preprocessing import PolynomialFeatures polynomial = PolynomialFeatures(degree=3)
We initialized a polynomial of the degree
3in the previous line. Now we have to represent the datapoints in terms of the coefficients of the polynomial:X_train_transformed = polynomial.fit_transform(X_train)Here,
X_train_transformedrepresents the same input in the polynomial form.Let's consider the first datapoint in our file and check whether it can predict the right output:
datapoint = [0.39,2.78,7.11] poly_datapoint = polynomial.fit_transform(datapoint) poly_linear_model = linear_model.LinearRegression() poly_linear_model.fit(X_train_transformed, y_train) print "\nLinear regression:", linear_regressor.predict(datapoint)[0] print "\nPolynomial regression:", poly_linear_model.predict(poly_datapoint)[0]
The values in the variable datapoint are the values in the first line in the input data file. We are still fitting a linear regression model here. The only difference is in the way in which we represent the data. If you run this code, you will see the following output:
Linear regression: -11.0587294983 Polynomial regression: -10.9480782122
As you can see, this is close to the output value. If we want it to get closer, we need to increase the degree of the polynomial.
Let's make it
10and see what happens:polynomial = PolynomialFeatures(degree=10)
You should see something like the following:
Polynomial regression: -8.20472183853
Now, you can see that the predicted value is much closer to the actual output value.