

If we have a probability space S and two events A and B, the probability of A given B is called conditional probability, and it's defined as:

As P(A, B) = P(B, A), it's possible to derive Bayes' theorem:
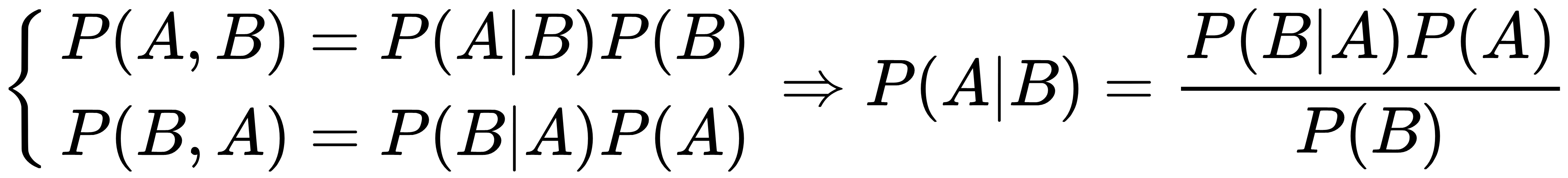
This theorem allows expressing a conditional probability as a function of the opposite one and the two marginal probabilities P(A) and P(B). This result is fundamental to many machine learning problems, because, as we're going to see in this and in the next chapters, normally it's easier to work with a conditional probability in order to get the opposite, but it's hard to work directly from the latter. A common form of this theorem can be expressed as:

Let's suppose that we need to estimate the probability of an event A given some observations B, or using the standard notation, the posterior probability of A; the previous formula expresses this value as proportional to the term P(A), which is the marginal probability of A, called prior probability...