

The main concept behind ensemble learning is the distinction between strong and weak learners. In particular, a strong learner is a classifier or a regressor which has enough capacity to reach the highest potential accuracy, minimizing both bias and variance (thus achieving also a satisfactory level of generalization). More formally, if we consider a parametrized binary classifier f(x; θ), we define it as a strong learner if the following is true:
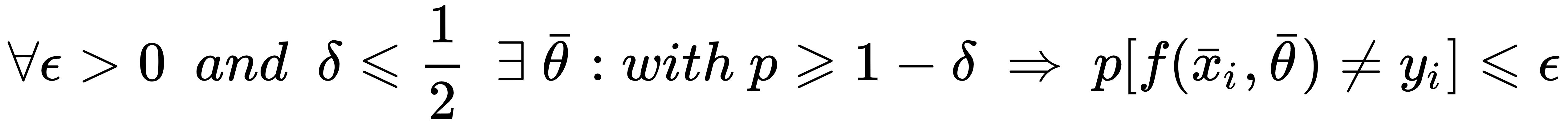
This expression can appear cryptic; however, it's very easy to understand. It simply expresses the concept that a strong learner is theoretically able to achieve any non-null probability of misclassification with a probability greater than or equal to 0.5 (that is, the threshold for a binary random guess). All the models normally employed in Machine Learning tasks are normally strong learners, even if their domain can be limited (for example, a logistic regression cannot solve non-linear problems). On the other hand...