

Removing duplicates
We can safely assume that all the data that lands on our desks is dirty (until proven otherwise). It is a good habit to check whether everything with our data is in order. The first thing I always check for is the duplication of rows.
Getting ready
To follow this recipe, you need to have OpenRefine and virtually any Internet browser installed on your computer.
We assume that you followed the previous recipes and your data is already loaded to OpenRefine and the data types are now representative of what the columns hold. No other prerequisites are required.
How to do it…
First, we assume that within the seven days of property sales, a row is a duplicate if the same address appears twice (or more) in the dataset. It is quite unlikely that the same house is sold twice (or more times) within such a short period of time. Therefore, first, we Blank down the observations if they repeat:
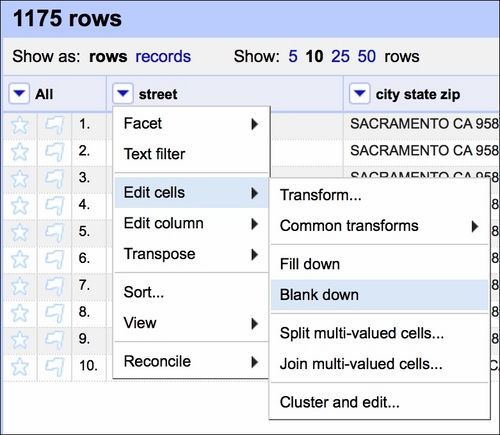
This effects in keeping only the first occurrence of a certain set of observations and blanking the rest (see the fourth row in the following screenshot):
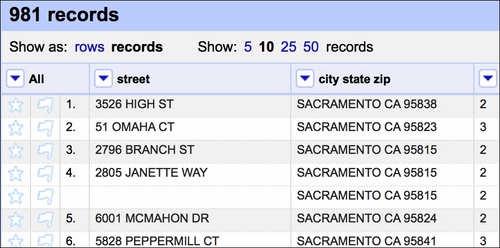
Tip
The Fill down option has the opposite effect—it would fill in the blanks with the values from the row above unless the cell is not blank.
We can now create a Facet by blank that would allow us to quickly select the blanked rows:
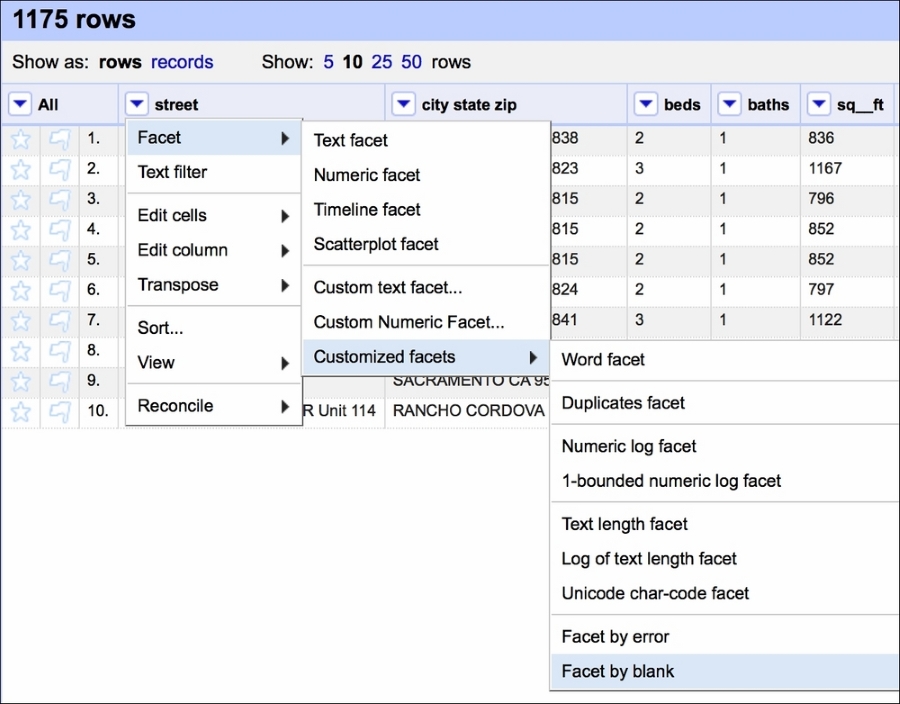
Creating such a facet allows us to quickly select all the rows that are blank and remove them from the dataset:
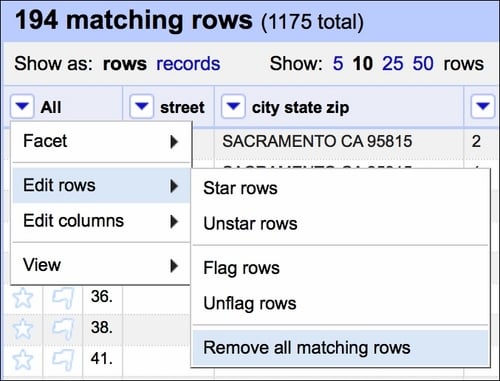
Our dataset now has no duplicate records.