



The gradient descent algorithm is not the only optimization algorithm available to optimize our network weights, however it's the basis for most other algorithms. While understanding every optimization algorithm out there is likely a PhD worth of material, we will devote a few sentences to some of the most practical.
-
Book Overview & Buying

-
Table Of Contents

Deep Learning Quick Reference
By :
Deep Learning Quick Reference
By:
Overview of this book
Deep learning has become an essential necessity to enter the world of artificial intelligence. With this book deep learning techniques will become more accessible, practical, and relevant to practicing data scientists. It moves deep learning from academia to the real world through practical examples.
You will learn how Tensor Board is used to monitor the training of deep neural networks and solve binary classification problems using deep learning. Readers will then learn to optimize hyperparameters in their deep learning models. The book then takes the readers through the practical implementation of training CNN's, RNN's, and LSTM's with word embeddings and seq2seq models from scratch. Later the book explores advanced topics such as Deep Q Network to solve an autonomous agent problem and how to use two adversarial networks to generate artificial images that appear real. For implementation purposes, we look at popular Python-based deep learning frameworks such as Keras and Tensorflow, Each chapter provides best practices and safe choices to help readers make the right decision while training deep neural networks.
By the end of this book, you will be able to solve real-world problems quickly with deep neural networks.
Table of Contents (15 chapters)
Preface
 Free Chapter
Free Chapter
The Building Blocks of Deep Learning
Using Deep Learning to Solve Regression Problems
Monitoring Network Training Using TensorBoard
Using Deep Learning to Solve Binary Classification Problems
Using Keras to Solve Multiclass Classification Problems
Hyperparameter Optimization
Training a CNN from Scratch
Transfer Learning with Pretrained CNNs
Training an RNN from scratch
Training LSTMs with Word Embeddings from Scratch
Training Seq2Seq Models
Using Deep Reinforcement Learning
Generative Adversarial Networks
Other Books You May Enjoy
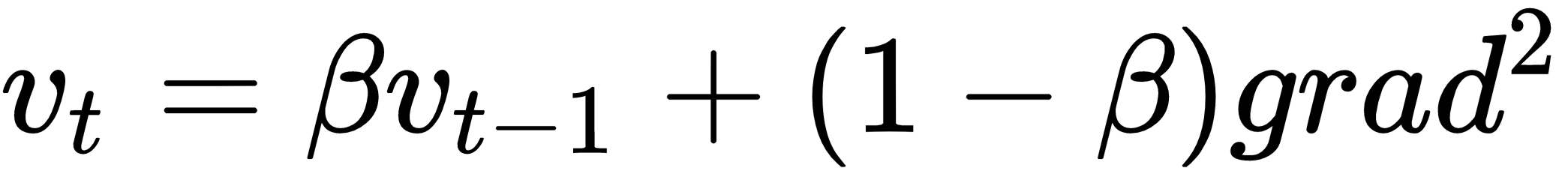
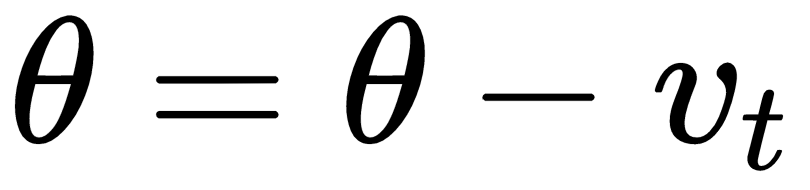
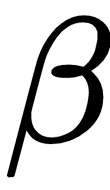 is set to 0.9 in the case of momentum, and usually this is not a hyper-parameter that needs to be changed.
is set to 0.9 in the case of momentum, and usually this is not a hyper-parameter that needs to be changed.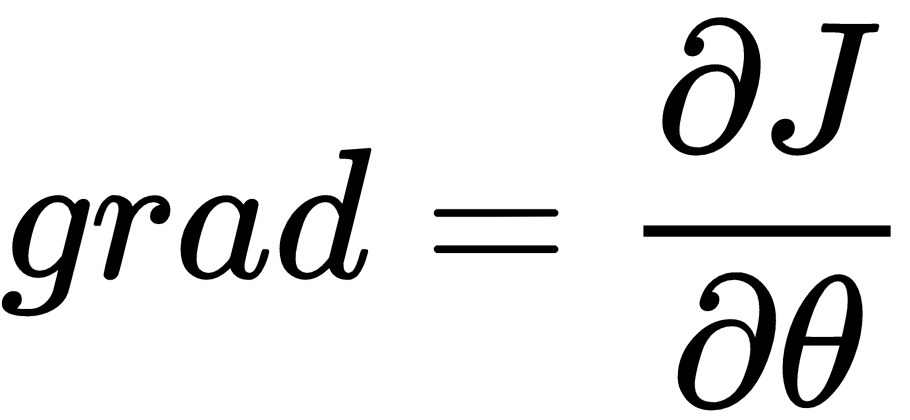
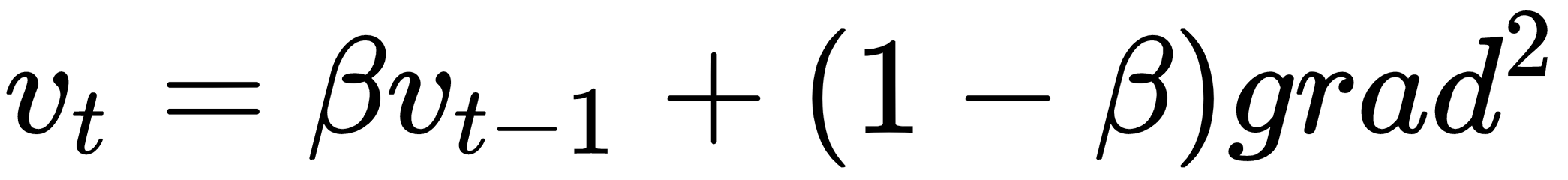
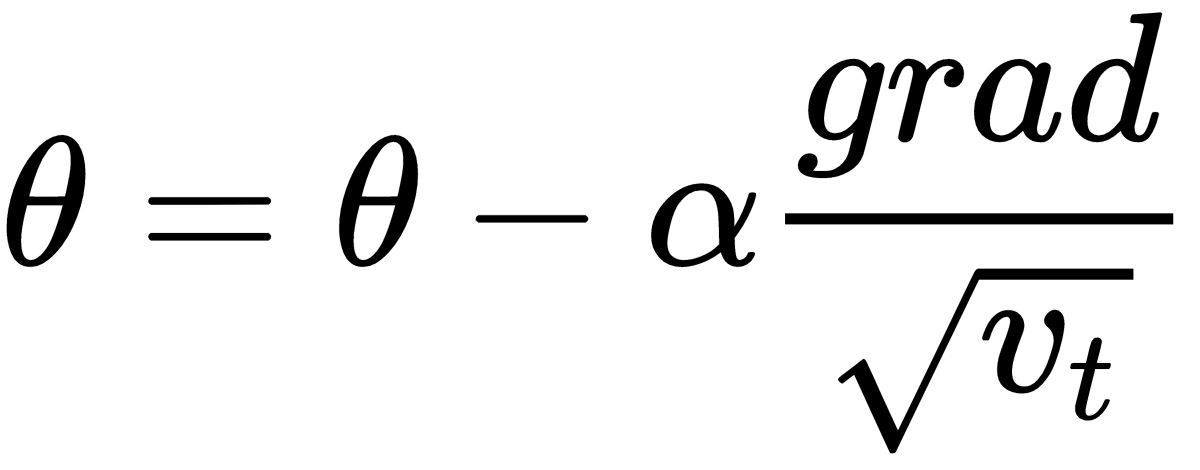
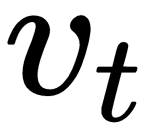 is large.
is large.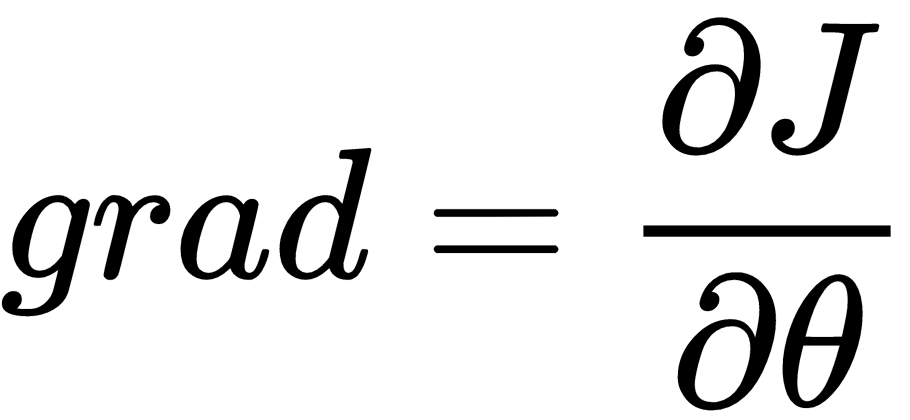
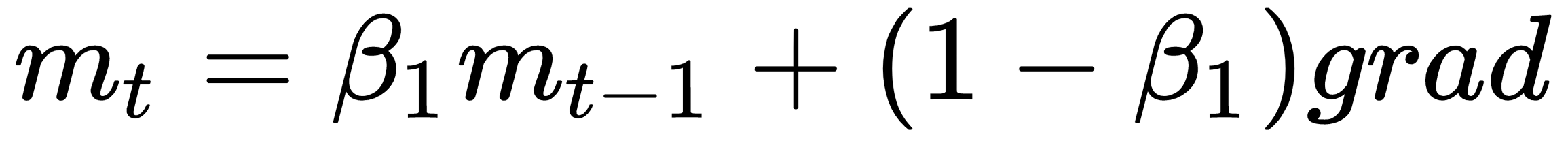
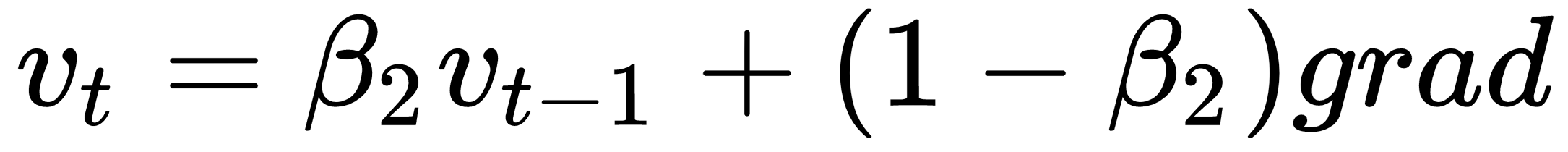
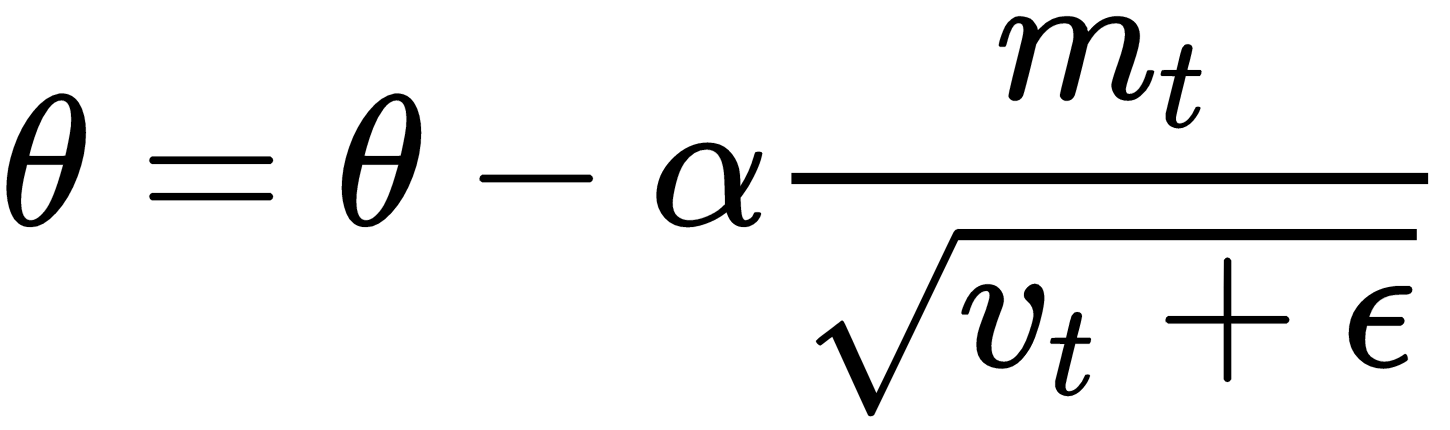
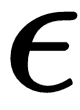 is some very small number to prevent division by 0.
is some very small number to prevent division by 0.






