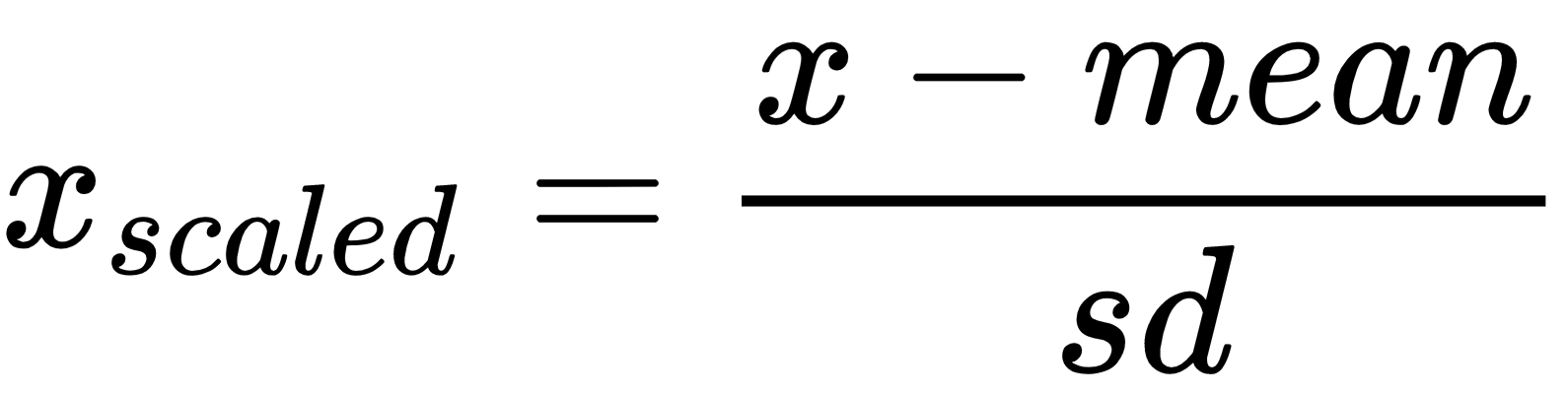In the real world, we usually have to deal with a lot of raw data. This raw data is not readily ingestible by machine learning algorithms. To prepare data for machine learning, we have to preprocess it before we feed it into various algorithms. This is an intensive process that takes plenty of time, almost 80 percent of the entire data analysis process, in some scenarios. However, it is vital for the rest of the data analysis workflow, so it is necessary to learn the best practices of these techniques. Before sending our data to any machine learning algorithm, we need to cross check the quality and accuracy of the data. If we are unable to reach the data stored in Python correctly, or if we can't switch from raw data to something that can be analyzed, we cannot go ahead. Data can be preprocessed in many ways—standardization, scaling, normalization, binarization, and one-hot encoding are some examples of preprocessing techniques. We will address them through simple examples.
-
Book Overview & Buying

-
Table Of Contents

Python Machine Learning Cookbook - Second Edition
By :
Python Machine Learning Cookbook
By:
Overview of this book
This eagerly anticipated second edition of the popular Python Machine Learning Cookbook will enable you to adopt a fresh approach to dealing with real-world machine learning and deep learning tasks.
With the help of over 100 recipes, you will learn to build powerful machine learning applications using modern libraries from the Python ecosystem. The book will also guide you on how to implement various machine learning algorithms for classification, clustering, and recommendation engines, using a recipe-based approach. With emphasis on practical solutions, dedicated sections in the book will help you to apply supervised and unsupervised learning techniques to real-world problems. Toward the concluding chapters, you will get to grips with recipes that teach you advanced techniques including reinforcement learning, deep neural networks, and automated machine learning.
By the end of this book, you will be equipped with the skills you need to apply machine learning techniques and leverage the full capabilities of the Python ecosystem through real-world examples.
Table of Contents (18 chapters)
Preface
 Free Chapter
Free Chapter
The Realm of Supervised Learning
Constructing a Classifier
Predictive Modeling
Clustering with Unsupervised Learning
Visualizing Data
Building Recommendation Engines
Analyzing Text Data
Speech Recognition
Dissecting Time Series and Sequential Data
Analyzing Image Content
Biometric Face Recognition
Reinforcement Learning Techniques
Deep Neural Networks
Unsupervised Representation Learning
Automated Machine Learning and Transfer Learning
Unlocking Production Issues
Other Books You May Enjoy