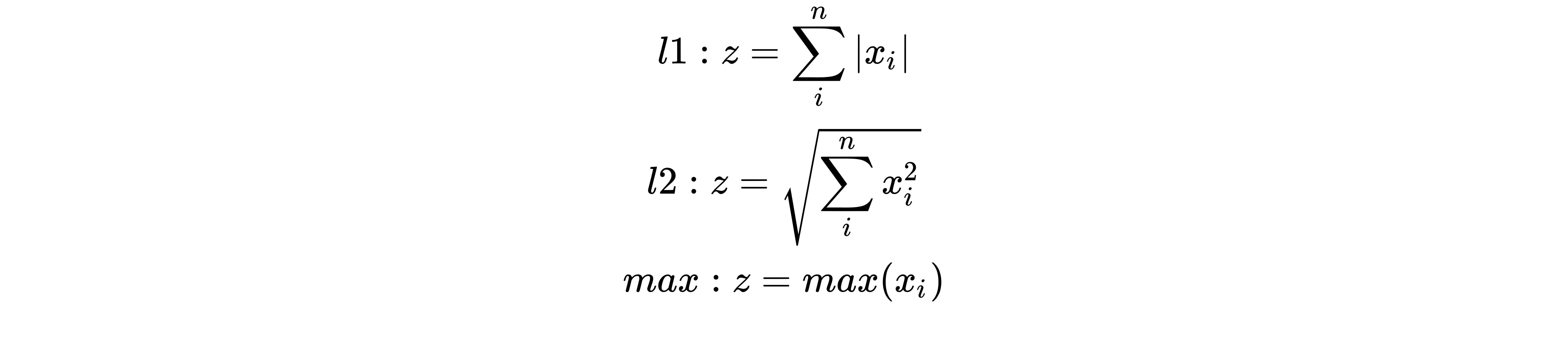Data normalization is used when you want to adjust the values in the feature vector so that they can be measured on a common scale. One of the most common forms of normalization that is used in machine learning adjusts the values of a feature vector so that they sum up to 1.
-
Book Overview & Buying

-
Table Of Contents

Python Machine Learning Cookbook - Second Edition
By :
Python Machine Learning Cookbook
By:
Overview of this book
This eagerly anticipated second edition of the popular Python Machine Learning Cookbook will enable you to adopt a fresh approach to dealing with real-world machine learning and deep learning tasks.
With the help of over 100 recipes, you will learn to build powerful machine learning applications using modern libraries from the Python ecosystem. The book will also guide you on how to implement various machine learning algorithms for classification, clustering, and recommendation engines, using a recipe-based approach. With emphasis on practical solutions, dedicated sections in the book will help you to apply supervised and unsupervised learning techniques to real-world problems. Toward the concluding chapters, you will get to grips with recipes that teach you advanced techniques including reinforcement learning, deep neural networks, and automated machine learning.
By the end of this book, you will be equipped with the skills you need to apply machine learning techniques and leverage the full capabilities of the Python ecosystem through real-world examples.
Table of Contents (18 chapters)
Preface
 Free Chapter
Free Chapter
The Realm of Supervised Learning
Constructing a Classifier
Predictive Modeling
Clustering with Unsupervised Learning
Visualizing Data
Building Recommendation Engines
Analyzing Text Data
Speech Recognition
Dissecting Time Series and Sequential Data
Analyzing Image Content
Biometric Face Recognition
Reinforcement Learning Techniques
Deep Neural Networks
Unsupervised Representation Learning
Automated Machine Learning and Transfer Learning
Unlocking Production Issues
Other Books You May Enjoy