-
Book Overview & Buying

-
Table Of Contents

Mastering Microsoft Power BI - Second Edition
By :
Mastering Microsoft Power BI
By:
Overview of this book
Mastering Microsoft Power BI, Second Edition, provides an advanced understanding of Power BI to get the most out of your data and maximize business intelligence. This updated edition walks through each essential phase and component of Power BI, and explores the latest, most impactful Power BI features.
Using best practices and working code examples, you will connect to data sources, shape and enhance source data, and develop analytical data models. You will also learn how to apply custom visuals, implement new DAX commands and paginated SSRS-style reports, manage application workspaces and metadata, and understand how content can be staged and securely distributed via Power BI apps. Furthermore, you will explore top report and interactive dashboard design practices using features such as bookmarks and the Power KPI visual, alongside the latest capabilities of Power BI mobile applications and self-service BI techniques. Additionally, important management and administration topics are covered, including application lifecycle management via Power BI pipelines, the on-premises data gateway, and Power BI Premium capacity.
By the end of this Power BI book, you will be confident in creating sustainable and impactful charts, tables, reports, and dashboards with any kind of data using Microsoft Power BI.
Table of Contents (18 chapters)
Preface

 Free Chapter
Free Chapter
Planning Power BI Projects
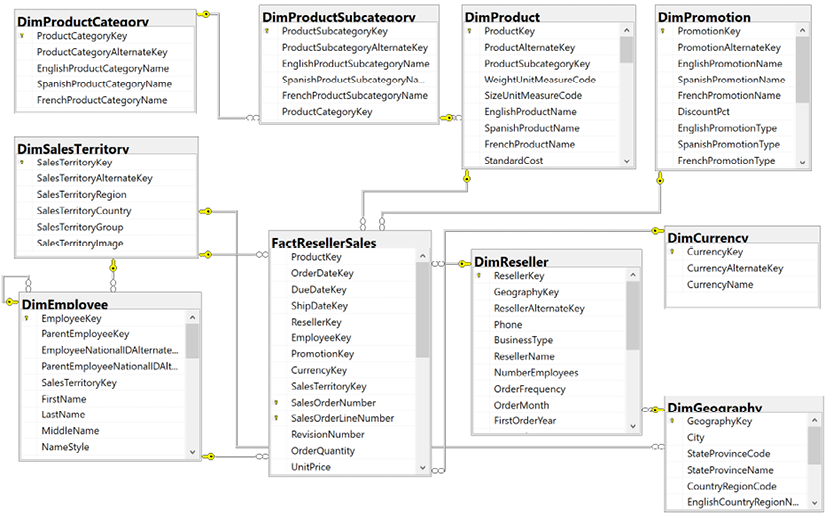
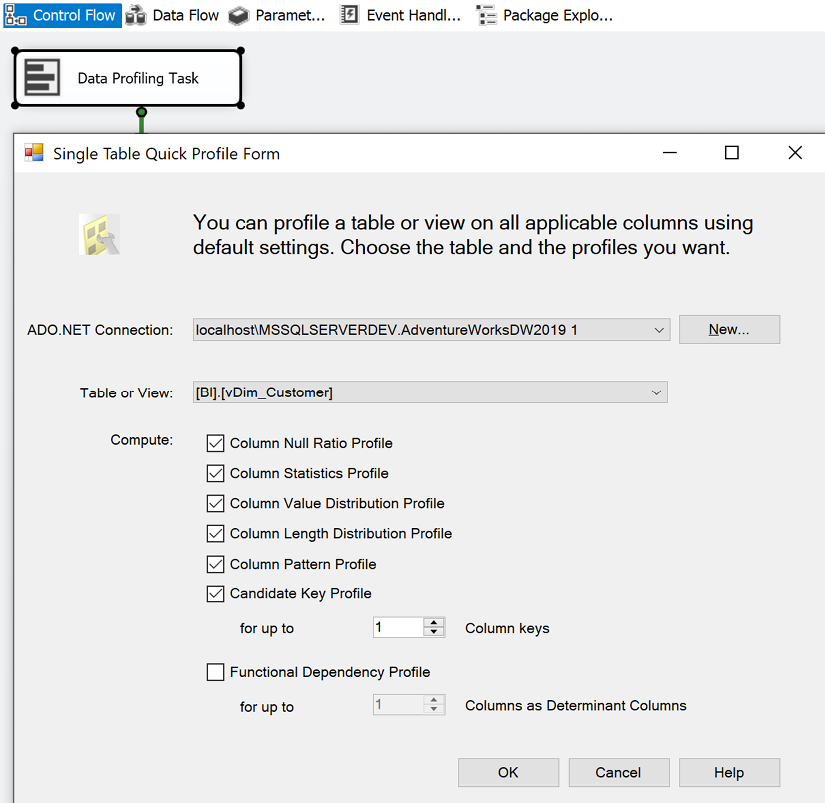
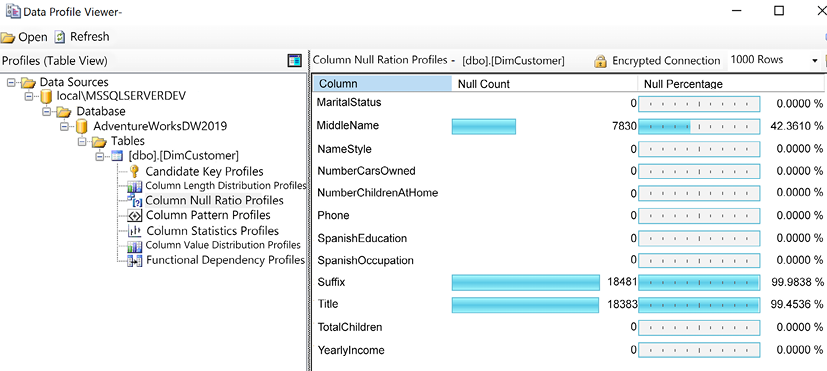
Preparing Data Sources
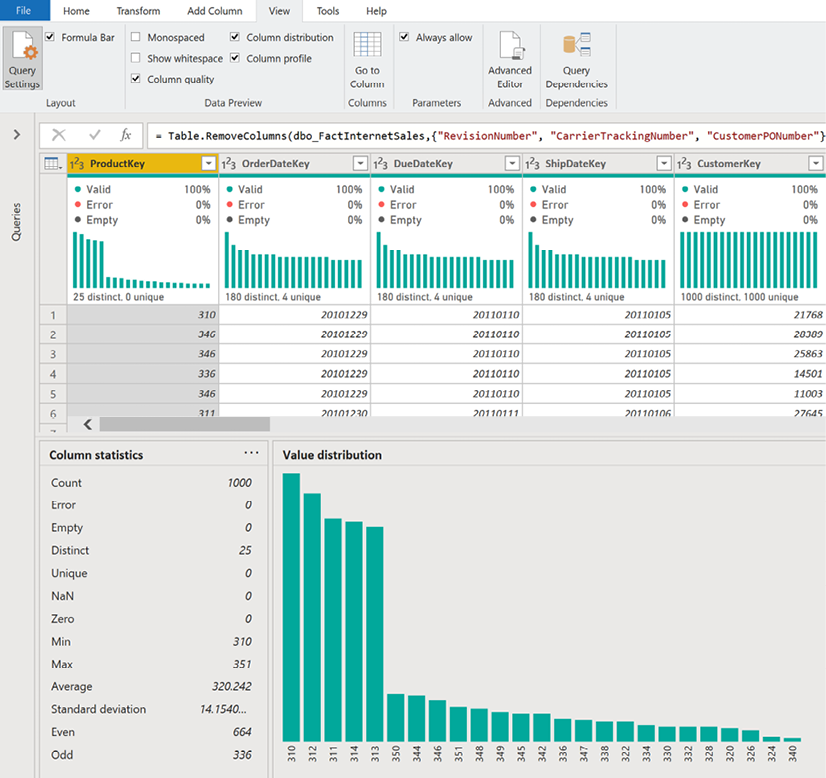
Connecting to Sources and Transforming Data with M
Designing Import, DirectQuery, and Composite Data Models
Developing DAX Measures and Security Roles
Planning Power BI Reports
Creating and Formatting Visualizations
Applying Advanced Analytics
Designing Dashboards
Managing Workspaces and Content
Managing the On-Premises Data Gateway
Deploying Paginated Reports
Creating Power BI Apps and Content Distribution
Administering Power BI for an Organization
Building Enterprise BI with Power BI Premium
Other Books You May Enjoy
Index