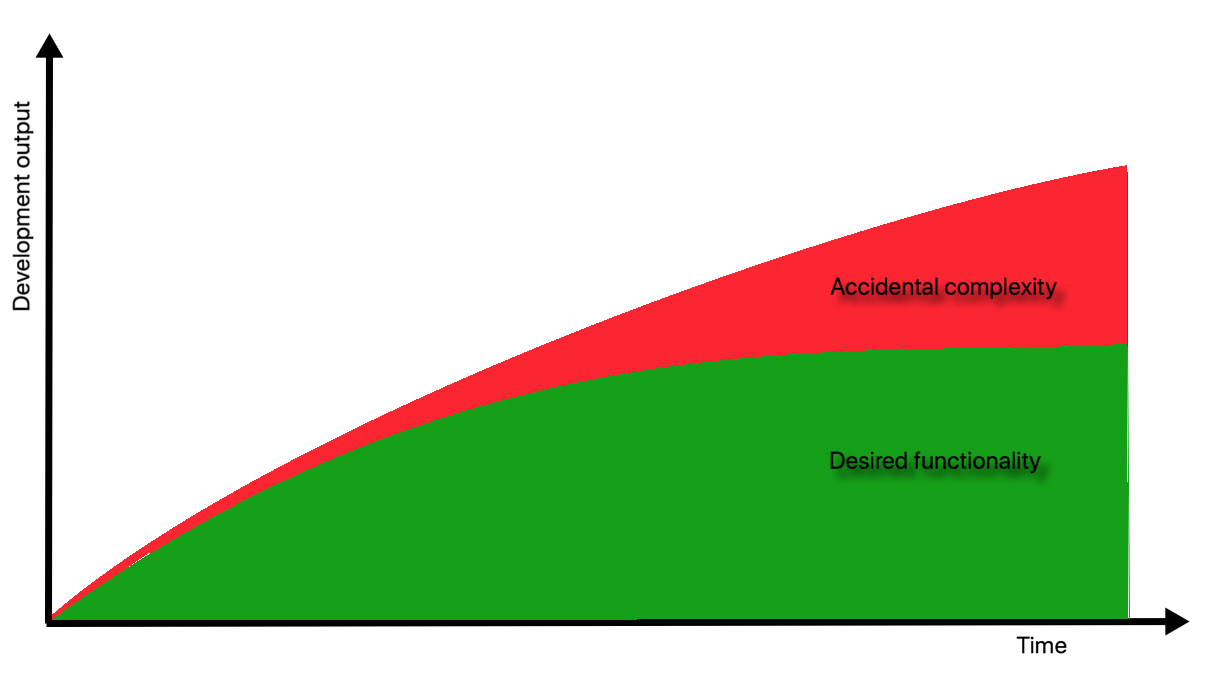
When dealing with problems, we don't always know whether these problems are complex. And if they are complex, how complex? Is there a tool for measuring complexity? If there is, it would be beneficial to measure, or at least categorize, the problem's complexity before starting to solve it. Such measurement would help to regulate the solution's complexity as well, since complex problems also demand a complex solution, with rare exceptions to this rule. If you disagree, we will be getting deeper into this topic in the following section.
In 2007, Dave Snowden and Mary Boone published a paper called A Leader's Framework for Decision Making in Harvard Business Review, 2007. This paper won the Outstanding Practitioner-Oriented Publication in OB award from the Academy of Management's Organizational Behavior division. What is so unique about it, and which framework does it describe?
The framework is Cynefin. This word is Welsh for something like habitat, accustomed, familiar. Snowden started to work on it back in 1999 when he worked at IBM. The work was so valuable that IBM established the Cynefin Center for Organizational Complexity, and Dave Snowden was its founder and director.
Cynefin divides all problems into five categories or complexity domains. By describing the properties of problems that fall into each domain, it provides a sense of place for any given problem. After the problem is categorized into one of the domains, Cynefin then also offers some practical approaches to deal with this kind of problem:
Cynefin framework, image by Dave Snowden
These five realms have specific characteristics, and the framework provides attributes for both, identifying to which domain your problem belongs, and how the problem needs to be addressed.
The first domain is Simple, or Obvious. Here, you have problems that can be described as known knowns, where best practices and an established set of rules are available, and there is a direct link between a cause and a consequence. The sequence of actions for this domain is sense-categorize-response. Establish facts (sense), identify processes and rules (categorize), and execute them (response).
Snowden, however, warns about the tendency for people to wrongly classify problems as simple. He identifies three cases for this:
- Oversimplification: This correlates with some of the cognitive biases described in the following section.
- Entrained thinking: When people blindly use the skills and experiences they have obtained in the past and therefore become blinded to new ways of thinking.
- Complacency: When things go well, people tend to relax and overestimate their ability to react to the changing world. The danger of this case is that when a problem is classified as simple, it can quickly escalate to the chaotic domain due to a failure to adequately assess the risks. Notice the shortcut from Simple to Chaotic domain at the bottom of the diagram, which is often being missed by those who study the framework.
For this book, it is important to remember two main things:
- If you identify the problem as obvious, you probably don't want to set up a complex solution and perhaps would even consider buying some off-the-shelf software to solve the problem, if any software is required at all.
- Beware, however, of wrongly classifying more complex problems in this domain to avoid applying the wrong best practices instead of doing more thorough exploration and research.
The second domain is Complicated. Here, you find problems that require expertise and skill to find the relation between cause and effect, since there is no single answer to these problems. These are known unknowns. The sequence of actions in this realm is sense-analyze-respond. As we can see, analyze replaces categorize because there is no clear categorization of facts in this domain. Proper analysis needs to be done to identify which good practice to apply. Categorization can be done here too, but you need to go through more choices and analyze the consequences as well. That is where previous experience is necessary. Engineering problems are typically in this category, where a clearly understood problem requires a sophisticated technical solution.
In this realm, assigning qualified people to do some design up front and then perform the implementation makes perfect sense. When a thorough analysis is done, the risk of implementation failure is low. Here, it makes sense to apply DDD patterns for both strategic and tactical design, and to the implementation, but you could probably avoid more advanced exploratory techniques such as EventStorming. Also, you might spend less time on knowledge crunching, if the problem is thoroughly understood.
Complex is the third complexity domain in Cynefin. Here, we encounter something that no one has done before. Making even a rough estimate is impossible. It is hard or impossible to predict the reaction to our action, and we can only find out about the impact that we have made in retrospect. The sequence of actions in this domain is probe-sense-respond. There are no right answers here and no practices to rely upon. Previous experience won't help either. These are unknown unknowns, and this is the place where all innovation happens. Here, we find our core domain, the concept, which we will get to later in the book.
The course of action for the complex realm is led by experiments and prototypes. There is very little sense in creating a big design up front since we have no idea how it will work and how the world will react to what we are doing. Work here needs to be done in small iterations with continuous and intensive feedback.
Advanced modeling and implementation techniques that are lean enough to respond to changes quickly are the perfect fit in this context. In particular, modeling using EventStorming and implementation using event-sourcing are very much at home in the complex domain. A thorough strategic design is necessary, but some tactical patterns of DDD can be safely ignored when doing spikes and prototypes, to save time. However, again, event-sourcing could be your best friend. Both EventStorming and event-sourcing are described later in the book.
The fourth domain is Chaotic. This is where hellfire burns and the Earth spins faster than it should. No one wants to be here. Appropriate actions here are act-sense-respond, since there is no time for spikes. It is probably not the best place for DDD since there is no time or budget for any sort of design available at this stage.
Disorder is the fifth and final realm, right in the middle. The reason for it is that when being at this stage, it is unclear which complexity context applies to the situation. The only way out from disorder is to try breaking the problem into smaller pieces that can be then categorized into those four complexity contexts and then deal with them accordingly.
This is only a brief overview of the categorization of complexity. There is more to it, and I hope your mind gets curious to see examples, videos, and articles about the topic. That was the exact reason for me to bring it in, so please feel free to stop reading now and explore the complexity topic some more. For this book the most important outcome is that DDD can be applied almost everywhere, but it is of virtually no use in obvious and chaotic domains. Using EventStorming as a design technique in complex systems would be useful for both complicated and complex domains, along with event-sourcing, which suits complex domains best.