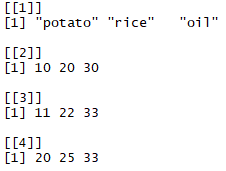
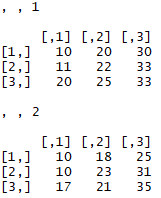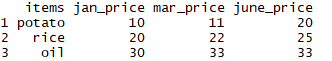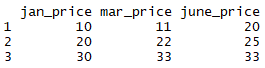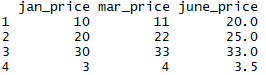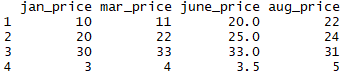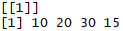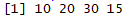Before we start delving deep into R for geospatial analysis, we need to have a good understanding of how R handles and stores different types of data. We also need to know how to undertake different operations on that data.
-
Book Overview & Buying

-
Table Of Contents

Hands-On Geospatial Analysis with R and QGIS
By :
Hands-On Geospatial Analysis with R and QGIS
By:
Overview of this book
Managing spatial data has always been challenging and it's getting more complex as the size of data increases. Spatial data is actually big data and you need different tools and techniques to work your way around to model and create different workflows. R and QGIS have powerful features that can make this job easier.
This book is your companion for applying machine learning algorithms on GIS and remote sensing data. You’ll start by gaining an understanding of the nature of spatial data and installing R and QGIS. Then, you’ll learn how to use different R packages to import, export, and visualize data, before doing the same in QGIS. Screenshots are included to ease your understanding.
Moving on, you’ll learn about different aspects of managing and analyzing spatial data, before diving into advanced topics. You’ll create powerful data visualizations using ggplot2, ggmap, raster, and other packages of R. You’ll learn how to use QGIS 3.2.2 to visualize and manage (create, edit, and format) spatial data. Different types of spatial analysis are also covered using R. Finally, you’ll work with landslide data from Bangladesh to create a landslide susceptibility map using different machine learning algorithms.
By reading this book, you’ll transition from being a beginner to an intermediate user of GIS and remote sensing data in no time.
Table of Contents (12 chapters)
Preface
 Free Chapter
Free Chapter
Setting Up R and QGIS Environments for Geospatial Tasks
Fundamentals of GIS Using R and QGIS
Creating Geospatial Data
Working with Geospatial Data
Remote Sensing Using R and QGIS
Point Pattern Analysis
Spatial Analysis
GRASS, Graphical Modelers, and Web Mapping
Classification of Remote Sensing Images
Landslide Susceptibility Mapping
Other Books You May Enjoy