

Introduction to XAI
XAI is the most effective practice to ensure that AI and ML solutions are transparent, trustworthy, responsible, and ethical so that all regulatory requirements on algorithmic transparency, risk mitigation, and a fallback plan are addressed efficiently. AI and ML explainability techniques provide the necessary visibility into how these algorithms operate at every stage of their solution life cycle, allowing end users to understand why and how queries are related to the outcome of AI and ML models.
Understanding the key terms
Usually, for ML models, for addressing the how questions, we use the term interpretability, and for addressing the why questions, we use the term explainability. In this book, the terms model interpretability and model explainability are interchangeably used. However, for providing human-friendly holistic explanations of the outcome of ML models, we will need to make ML algorithms both interpretable and explainable, thus allowing the end users to easily comprehend the decision-making process of these models.
In most scenarios, ML models are considered as black-boxes, where we feed in any training data and it is expected to predict on new, unseen data. Unlike conventional programming, where we program specific instructions, an ML model automatically tries to learn these instructions from the data. As illustrated in Figure 1.1, when we try to find out the rationale for the model prediction, we do not get enough information!
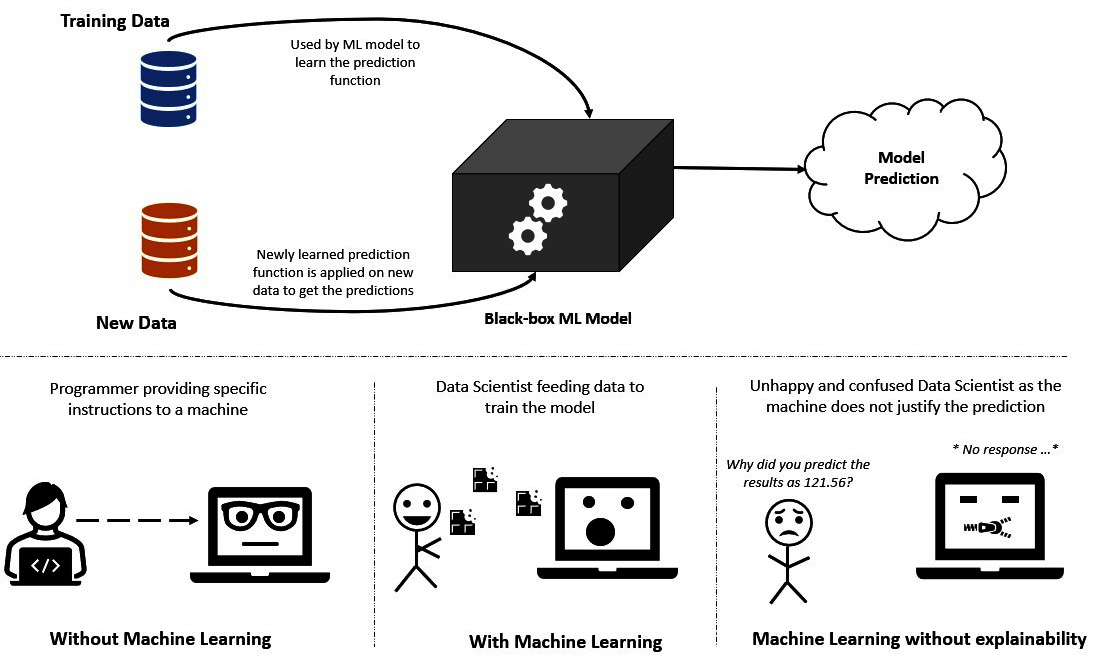
Figure 1.1 – Conventionally, black-box models do not provide any rationale behind predictions
Now, let's understand the impact of incorrect predictions and inaccurate ML models.
Consequences of poor predictions
Traditionally, all ML models were believed to be magical black-boxes that can automatically decipher interesting patterns and insights from the data and provide silver bullet outcomes! As compared to conventional rule-based computer programs, which are limited by the intelligence of the programmer, well-trained ML algorithms are considered to provide rich insights and accurate predictions even in complex situations. But the fact is, all ML models suffer from bias, which can be due to the inductive bias of the algorithm itself, or it can be due to the presence of bias in the dataset used for training the model. In practice, there can be other reasons, such as data drift, concept drift, and overfitted or underfitted models, for which model predictions can go wrong. As the famous British statistician George E.P. Box once said, "All models are wrong, but some are useful"; all statistical, scientific, and ML models can give incorrect outcomes if the initial assumptions of these methods are not consistent. Therefore, it is important for us to know why an ML model predicted a specific outcome, what can be done if it is wrong, and how the predictions can be improved.
Figure 1.2 illustrates a collection of news headlines highlighting the failure of AI algorithms towards producing fair and unbiased outcomes.

Figure 1.2 – Growing concern of bias and lack of fairness of ML models being reported frequently
Before completely agreeing with me on the necessity of model explainability, let me try to give some practical examples of low-stake and high-stake domains to understand the consequences of poor predictions. Weather forecasting is one of the classical forecasting problems that is extremely challenging (as it depends on multiple dynamic factors) where ML is extensively used, and the ability of ML algorithms to consider multiple parameters of different types makes it more efficient than standard statistical models to predict the weather. Despite having highly accurate forecast models, there are times when weather forecasting algorithms might miss the prediction of rainfall, even though it starts raining after a few minutes! But the consequences of such a poor prediction might not be so severe, and moreover, most people do not blindly rely on automated weather predictions, thus making weather forecasting a low-stake domain problem.
Similarly, for another low-stake domain, such as a content recommendation system, even if an ML algorithm provides an irrelevant recommendation, at the most, the end users might spend more time explicitly searching for relevant content. While the overall experience of the end user might be impacted, still, there is no severe loss of life or livelihood. Hence, the need for model explainability is not critical for low-stake domains, but providing explainability to model predictions does make the automated intelligent systems more trustworthy and reliable for end users, thus increasing AI adoption by enhancing the end user experience.
Now, let me give an example where the consequences of poor predictions led to a severe loss of reputation and valuation of a company, impacting many lives! In November 2021, an American online real estate marketplace company called Zillow (https://www.zillow.com/) reported having lost over 40% of its stock value, and the home-buying division Offers lost over $300 million because of its failure to detect the unpredictability of their home price forecasting algorithms (for more information, please refer to the sources mentioned in the References section). In order to compensate for the loss, Zillow had to take drastic measures of cutting down its workforce and several thousands of families were impacted.
Similarly, multiple technology companies have been accused of using highly biased AI algorithms that could result in social unrest due to racial or gender discrimination. One such incident happened in 2015 when Google Photos made a massive racist blunder by automatically tagging an African-American couple as Gorilla (please look into the sources mentioned in the References section for more information). Although these blunders were unintentional and mostly due to biased datasets or non-generalized ML models, the consequences of these incidents can create massive social, economic, and political havoc. Bias in ML models in other high-stake domains, such as healthcare, credit lending, and recruitment, continuously reminds us of the need for more transparent solutions and XAI solutions on which end users can rely.
As illustrated in Figure 1.3, the consequences of poor predictions highlight the importance of XAI, which can provide early indicators to prevent loss of reputation, money, life, or livelihood due to the failure of AI algorithms:

Figure 1.3 – Common consequences of poor prediction of ML models
Now, let's try to summarize the need for model explainability in the next section.
Summarizing the need for model explainability
In the previous section, we learned that the consequences of poor predictions can impact many lives in high-risk domains, and even in low-risk domains the end user's experience can be affected. Samek and Binder's work in Tutorial on Interpretable Machine Learning, MICCAI'18, highlights the main necessity of model explainability. Let me try to summarize the key reasons why model explainability is essential:
- Verifying and debugging ML systems: As we have seen some examples where wrong model decisions can be costly and dangerous, model explainability techniques help us to verify and validate ML systems. Having an interpretation for incorrect predictions helps us to debug the root cause and provides a direction to fix the problem. We will discuss the different stages of an explainable ML system in more detail in Chapter 10, XAI Industry Best Practices.
- Using user-centric approaches to improve ML models: XAI provides a mechanism to include human experience and intuition to improve ML systems. Traditionally, ML models are evaluated based on prediction error. Using such evaluation approaches to improve ML models doesn't add any transparency and may not be robust and efficient. However, using explainability approaches, we can use human experience to verify predictions and understand whether model-centric or data-centric approaches are further needed to improve the ML model. Figure 1.4 compares a classical ML system with an explainable ML system:

Figure 1.4 – Comparison between classical ML and explainable ML approach
- Learning new insights: ML is considered to automatically unravel interesting insights and patterns from data that are not obvious to human beings. Explainable ML provides us with a mechanism to understand the rationale behind the insights and patterns automatically picked up by the model and allows us to study these patterns in detail to make new discoveries.
- Compliance with legislation: Many regulatory bodies, such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), have expressed severe concerns about the lack of explainability in AI. So, growing global AI regulations have empowered individuals with the right to demand an explanation of automated decision-making systems that can affect them. Model explainability techniques try to ensure ML models are compliant with proposed regulatory laws, thereby promoting fairness, accountability, and transparency.

Figure 1.5 – (Top) Screenshots of tweets from the European Commission, highlighting the right to demand explanations. (Bottom) Table showing some important regulatory laws established for making automated decision systems explainable, transparent, accountable, and fair
The need for model explainability can be visualized in the following diagram of the FAT model of explainable ML as provided in the book Interpretable Machine Learning with Python by Serg Masís.

Figure 1.6 – FAT model of explainable ML (from Interpretable Machine Learning with Python by Serg Masís)
Figure 1.6 shows the pyramid that forms the FAT model of explainable ML system for increasing AI adoption. Let us discuss about defining explanation methods and approaches in the next section.