

Simply using multiple threads in a program is not a very complicated task. If your program can be easily separated into several independent tasks, then you just run them in different threads, and these threads can be scaled along with the number of CPU cores. However, usually real world programs require some interaction between these threads, such as exchanging information to coordinate their work. This cannot be implemented without sharing some data, which requires allocating some RAM space in such a way that it is accessible from all the threads. Dealing with this shared state is the root of almost every problem related to parallel programming.
The first common problem with shared state is undefined access order. If we have read and write access, this leads to incorrect calculation results. This situation is commonly referred to as a race condition.
Following is a sample of a race condition. We have a counter, which is being changed from different threads simultaneously. Each thread increments the counter, then does some work, and then decrements the counter.
const int iterations = 10000;
var counter = 0;
ThreadStart proc = () => {
for (int i = 0; i < iterations; i++) {
counter++;
Thread.SpinWait(100);
counter--;
}
};
var threads = Enumerable
.Range(0, 8)
.Select(n => new Thread(proc))
.ToArray();
foreach (var thread in threads)
thread.Start();
foreach (var thread in threads)
thread.Join();
Console.WriteLine(counter);The expected counter value is 0. However, when you run the program, you get different numbers (which is usually not 0, but it could be) each time. The reason is that incrementing and decrementing the counter is not an atomic operation, but consists of three separate steps – reading the counter value, incrementing or decrementing this value, and writing the result back into the counter.
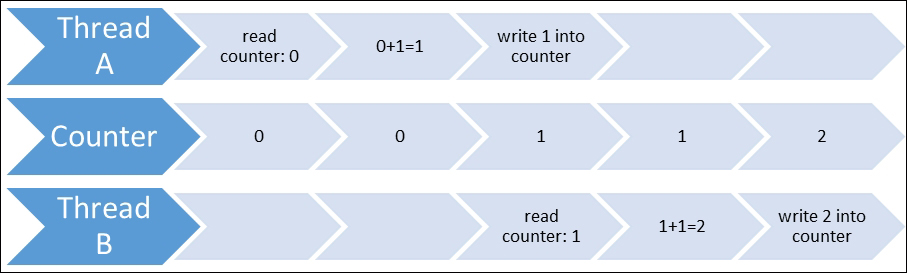
Let us assume that we have initial counter value 0, and two threads. The first thread reads 0, increments it to 1, and writes 1 into the counter. The second thread reads 1 from the counter, increments it to 2, and then writes 2 into the counter. This seems to be correct and is exactly what we expected. This scenario is represented in the following diagram:
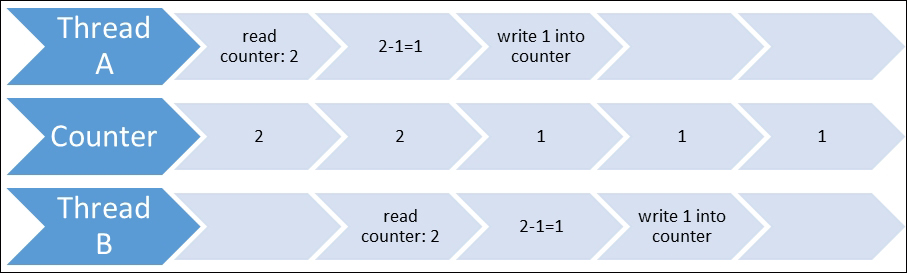
Now the first thread reads 2 from the counter, and at the same time it decrements it to 1; the second thread reads 2 from the counter, because the first thread hasn't written 1 into the counter yet. So now, the first thread writes 1 into the counter, and the second thread decrements 2 to 1 and writes the value 1 into the counter. As a result, we have the value 1, while we're expecting 0. This scenario is represented in the following diagram:
Tip
Downloading the example code
You can download the example code files from your account at http://www.packtpub.com for all the Packt Publishing books you have purchased. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
To avoid this, we have to restrict access to the counter so that only one thread reads it at a time, calculates the result, and writes it back. Such a restriction is called a lock. However, by using it to resolve a race condition problem, we create other possibilities for our concurrent code to fail. With such a restriction, we turn our parallel process into a sequential process, which in turn means that our code runs less efficiently. The more time the code runs inside the lock, the less efficient and scalable the whole program is. This is because the lock held by one thread blocks the other threads from performing their work, thereby making the whole program take longer to run. So, we have to minimize the lock time to keep the other threads running, instead of waiting for the lock to be released to start doing their calculations.
Another problem related to locks is best illustrated by the following example. It shows two threads using two resources, A and B. The first thread needs to lock object A first, then B, while the second thread starts with locking B and then A.
const int count = 10000;
var a = new object();
var b = new object();
var thread1 =
new Thread(
() =>
{
for (int i = 0; i < count; i++)
lock (a)
lock (b)
Thread.SpinWait(100);
});
var thread2 =
new Thread(
() =>
{
for (int i = 0; i < count; i++)
lock (b)
lock (a)
Thread.SpinWait(100);
});
thread1.Start();
thread2.Start();
thread1.Join();
thread2.Join();
Console.WriteLine("Done");It looks like this code is alright, but if you run it several times, it will eventually hang. The reason for this lies in an issue with the locking order. If the first thread locks A, and the second locks B before the first thread does, then the second thread starts waiting for the lock on A to be released. However, to release the lock on A, the first thread needs to put a lock on B, which is already locked by the second thread. Therefore, both the threads will wait forever and the program will hang.
Such a situation is called a deadlock. It is usually quite hard to diagnose deadlocks, because it is hard to reproduce one.
Note
The best way to avoid deadlocks is to take preventive measures when writing code. The best practice is to avoid complicated lock structures and nested locks, and minimize the time in locks. If you suspect there could be a deadlock, then there is another way to prevent it from happening, which is by setting a timeout for acquiring a lock.