

Serialization’s goals
Serialization and its counterpart, deserialization, enable us to handle data seamlessly across time and machines. This is highly relevant to current workloads because we have more and more data that we process in batches and we have more and more distributed systems that need to send data on the wire. In this section, we will dive a little bit deeper into serialization to understand how it can achieve encoding of data for later use.
How does it all work?
In order to process data across time and machines, we need to take data that is in volatile memory (memory that needs constant power in order to retain data) and save it to non-volatile memory (memory that retains stored information even after power is removed) or send data that is in volatile memory over the wire. And because we need to be able to make sense of the data that was saved to a file or sent over the wire, this data needs to have a certain structure.
The structure of the data is called the data format. It is a way of encoding data that is understood by the deserialization process in order to recreate the original data. Protobuf is one such data format.
Once this data is encoded in a certain way, we can save it to a file, send it across the network, and so on. And when the time comes to read this data, deserialization kicks in. It will take the data encoded following the data format rules (serialized data) and turn it back into data in volatile memory. Figure 1.1 summarizes graphically the data lifecycle during serialization and deserialization.
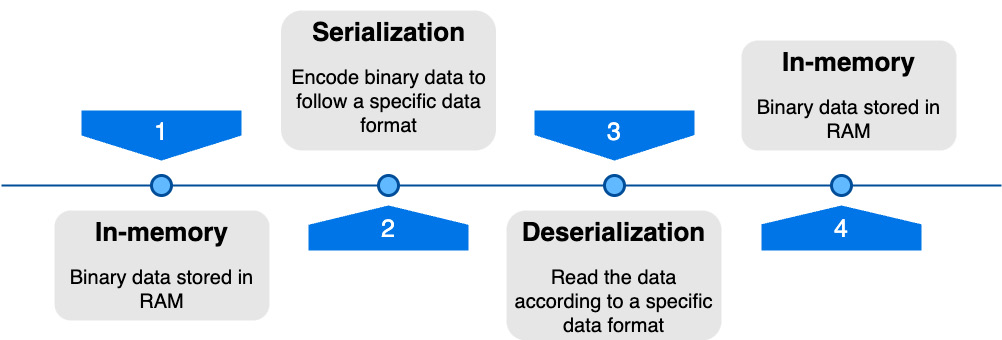
Figure 1.1 – Data lifecycle during serialization/deserialization
To summarize, in order to treat data across time and machines, we need to serialize it. This means that we need to take some sort of data and encode it with rules given by a specific data format. And after that, when we want to finally reuse the data, we deserialize the encoded data. This is the big picture of serialization and deserialization. Let us now see what the different data formats are and the metrics we can use in order to compare them.
The different data formats
As mentioned earlier in this chapter, a data format is a way of encoding data that can be interpreted by both the application engaged in serialization and the one involved in deserialization. There are multiple such formats, so it is impractical to list them all. However, we can distribute all of them into two categories:
- Text
- Binary
The most commonly used text data formats are JSON and XML. And for binary, there is Protobuf, but you might also know Apache Avro, Cap’n Proto, and others.
As with everything in software engineering, there are trade-offs for using one or the other. But before diving into these trade-offs, we need to understand the criteria on which we will base our comparison. Here are the criteria:
- Serialized data size: This is the size in bytes of the data after serialization
- Availability of data: This is the time it takes to deserialize data and use it in our code
- Readability of data: As humans, is it possible to read the serialized data without too much effort?
On top of that, certain data formats, such as Protobuf, rely on data schema to define the structure of the data. This brings another set of criteria that can be used to determine which data format is the best for your use case:
- Type safety: Can we make sure, at compile time, that the provided data is correct?
- Readability of schema: As humans, is it possible to read the schema without too much effort?
Let us now dive deeper into each criterion so that, later on, we can evaluate how Protobuf is doing against the competition.
Serialized data size
As the goal of serializing data is to send it across the wire or save it in non-volatile storage, there is a direct benefit of having a smaller payload size: we save disk space and/or bandwidth. In other words, this means that with the same amount of storage or bandwidth, the smaller payloads allow us to save/send more data.
Now, it is important to mention that, depending on the context, it is not always a good thing to have the smallest serialized data size. We are going to talk about this in the next subsection, but serializing to a smaller number of bytes means going away from the domain of human readability and going more toward the domain of machine readability.
An example of this can be illustrated if we take the following JavaScript Object Notation (JSON):
{
"person": {
"name": "Clement"
}
} Let’s compare it with the hexadecimal representation of Protobuf serialized data, which is the same as the previous data:
0a 07 43 6c 65 6d 65 6e 74
In the former code block, we can see the structure of the object clearly, but the latter is serialized as a smaller number of bytes (9 instead of 39 bytes). There is a trade-off here and while our example is not showing real-life data, we can get the idea of size saving bandwidth/storage while at the same time affecting readability.
Finally, serializing to a smaller number of bytes has another benefit which is that, since there are fewer bytes, we can go over all the data in less time and thus deserialize it faster. This is linked to the concept of availability of data, and this is what we are going to see now.
Availability of data
It is not a surprise that the bigger the number of bytes we deal with, the more processing power it will take. It is important to understand that deserialization is not free and that the more human-readable data is, the more data massaging will be required and thus more processing power will be used.
The availability of data is the time it takes between deserializing data and being able to act on it in code. If we were to write pseudo code for calculating the availability of data, we would have something like the following code block:
start = timeNowMs() deserialize(data) end = timeNowMs() availability = end - start
It is as simple as this. Now, I believe we can agree that there is not much of a trade-off here. As impatient and/or performance-driven programmers, we prefer to lower the time it takes to deserialize data. The faster we get our data, the less it costs in bandwidth, developer time, and so on.
Readability of data
We mentioned the readability of data when we were talking about data serialization size. Let us now dive deeper into what it means. The readability of data refers to how easy it is to understand the structure of the data after serialization. While readability and understandability are subjective, there are formats that are inherently harder than others.
Text formats are generally easier to understand because they are designed for humans. In these formats, we want to be able to quickly edit values with a simple text editor. This is the case for XML, JSON, YAML, and others. Furthermore, the ownership of objects is clearly defined by nesting objects into other ones. All of this is very intuitive, and it makes the data human readable.
On the other hand, binary formats are designed to be read by computers. While it is feasible to read them with knowledge of the format and with some extra effort, the overall goal is to make the computer serialize/deserialize the data faster. Open such serialized data with a text editor and you will see, sometimes, it is not even possible to distinguish bytes. Instead, you would have to use tools such as hexdump to see the hexadecimal representation of the binary.
To summarize, the readability of data is a trade-off that mainly focuses on who the reader of the data is. If it is humans, go with text formats, and if it is machines, choose binary since they will be able to understand the data faster.
Type safety
As mentioned, some data formats rely on us to describe the data through schemas. If you have worked with JSON Schema or any other kind of schema, you know that we can explicitly set types to fields in order to limit the possible value. For example, say we have the following Protobuf schema (note that this is not correct because it is simplified):
message Person {
string name;
} With this Protobuf schema, we would be only able to set strings to the name field, not integers, floats, or others. On the other hand, say we add the following JSON (without JSON Schema):
{
"person": {
"name": "Clément"
}
} Nothing could stop us from setting names to a number, an array, or anything else.
This is the idea of type safety. Generally, we are trying to make the feedback loop for developers shorter. If we are setting the wrong type of data to a field, the earlier we know about it, the better. We should not be surprised by an exception when the code is in production.
However, it is important to note that there are also benefits to having dynamic typing. The main one is considered to be productivity. It is way faster to hack and iterate with JSON than to first define the schema, generate code, and import the generated code into the user code.
Once again, this is a trade-off. But this time, this is more about the maintainability and scale of your project. If you have a small project, why incur the overhead of having the extra complexity? But if you have a medium/large size project, you want to have a more rigorous process that will shorten the feedback loop for your developers.
Readability of schema
Finally, we can talk about the readability of the schema. Once again this is a subjective matter but there are points that are worth mentioning. The readability of the schema can be described as how easy it is to understand the relationship between objects and what the data represents.
Although it may appear that this applies solely to formats reliant on schemas, that’s not the case. In reality, certain data formats are both the schema and the data they represent; JSON is an example of that. With nesting and typing of data, JSON can represent objects and their relationships, as well as what the internal data looks like. An example of that is the following JSON:
{
"person": {
"name": "Clément",
"age": 100,
"friends": [
{ "name": "Mark" },
{ "name": "John" }
]
}
} It describes a person whose name (a string) is Clement, whose age (a number) is 100, and who has friends (an array) called Mark and John. As you can see, this is very intuitive. However, such a schema is not type-safe.
If we care about type safety, then we cannot choose to use straight JSON. We could set the wrong kind of data to the name, age, and friends fields. Furthermore, nothing indicates whether the objects in the friends fields are persons. This is mostly because, in JSON, we cannot create definitions of objects and use the types. All types are implicit.
Now, consider the following Protobuf schema (note that this is simplified):
message Person {
string name;
uint32 age;
repeated Person friends; // equivalent of a list
} Here we only have the schema, no data. However, we can quickly see that we have the explicit string, uint32, and Person types. This will prevent a lot of bugs by catching them at compile time. We simply cannot set a string to age, a number to name, and so on.
There are a lot more criteria for the readability of schema (boilerplate, language concepts, etc.) but we can probably agree on the fact that, for onboarding developers and maintaining the project, the type explicitness is important and will catch bugs early in the development process.
To summarize, we got ourselves another trade-off. The added complexity of an external schema might be too much for small projects. However, for medium and large projects the benefits that come with type-safe schema are worth the trouble of spending a little bit more time on schema definition.
You probably noticed, but there are a lot of trade-offs. All of these are fueled by business requirements but also by subjectivity. In this section, we saw the five important trade-offs that you need to consider before choosing a data format for your project. We saw that the size of serialized data is important to consider in order to save resources (e.g. storage and bandwidth). Then, we saw what is the availability of data in the context of deserialization and how the size of the serialized data will impact it. After that, we talked about the readability of serialized data. We said that whether the size of serialized data matters depends on who is reading the data. And finally, we talked about the readability and type safety of the schema. By having explicit types, we can make sure that only the right data gets serialized and deserialized, but it also makes reading the schema itself more approachable for new developers.