

Ryan is a marketing manager at Dely Inc. Dely is a food delivery start-up and is trying to establish itself in the city of London. Dely is good at logistics and wants to aggregate restaurants on their platform, so when consumers order food from these restaurants, Dely will be responsible for the actual delivery. Dely is hoping that with every delivery they do, they will get a percentage cut from the restaurants. In return, restaurants have to think about their kitchen and not the logistical aspects. If you carefully think, virtually, every restaurant, big or small, is their probable lead. Dely wants to reach out to these restaurants and hopes to add them to their platform and fulfill their delivery needs.
Ryan is responsible for getting in touch with restaurants and wants to run a marketing campaign on all the target restaurants. But before he can do this, he needs to create a database of all the restaurants in London. He needs details, such as the name of the restaurant, the street address, and the contact number so that he can reach these restaurants. Ryan knows all his leads are listed on Yelp, but doesn't know where to start. Also, if he starts looking at all restaurants manually, it will take him a huge amount of time. With the knowledge you gained in this chapter, can you help Ryan with lead generation?
We covered the legal aspects of web scraping in the initial parts of the chapter. I would like to warn you again on this. The example covered in this chapter, again, is for you to understand how to perform web scraping. Also, here we're scraping Yelp for public data, which is commonly available, as in this case, it is available on the restaurant's website itself.
Now, if you look at Ryan's problem, he needs an automated way of collecting the database of all the restaurants listed in London. Yes, you got it right. Web scraping can help Ryan build this database. Can it be that easy? Let's see in this recipe.
For this recipe, we don't need any extra modules. We'll use the BeautifulSoup and urllib Python modules that we used in the previous recipes of this chapter.
We start by going to the Yelp website (https://yelp.com/) and searching for all the restaurants in the city of London. When you do that, you'll get a list of all the restaurants in London. Observe the URL that displays the search criteria. It is https://www.yelp.com/search?find_desc=Restaurants&find_loc=London. See the following screenshot for reference:

Now, if you click on any of the restaurants' link that shows up in the search results, we should get the details that Ryan needs. See the following screenshot, where we get the details of Ffiona's Restaurant. Note how every restaurant has a dedicated URL; in this case, it is https://www.yelp.com/biz/ffionas-restaurant-london?osq=Restaurants. Also note that on this page, we have the name of the restaurant, the street address, and even the contact number. All the details that Ryan needs for his campaign; that's cool!

OK nice, so we now know how to get the list of restaurants and also fetch the relevant details for a restaurant. But how do we achieve this in an automated way? As we saw in the web scraping example, we need to look for the HTML elements on the web pages from where we can collect this data.
Let's start with the search page. Open the search page (https://www.yelp.com/search?find_desc=Restaurants&find_loc=London) on your Chrome browser. Now, right-click on the first restaurant's URL and click on Inspect to get the HTML elements. If you notice, in the following screenshot, all the restaurants that are listed on the search page have a common CSS class name,
biz-name, which indicates the name of the restaurant. It also contains thehreftag, which points to the dedicated URL of the restaurant. In our screenshot, we get the name, Ffiona's Restaurant, and thehrefpoints to the restaurant's URL, https://yelp.com/biz/ffionas-restaurant-london?osq=Resturants.
Now, let's look at the dedicated page of the restaurant to see how we collect the street address and the contact number of the restaurant with the HTML elements. We perform the same operation, right-click, and Inspect to get the HTML elements of street address and contact number. See the following screenshot for reference. Note that for the street address, we have a separate CSS class,
street-address, and the contact number is available under a span with the class name, biz-phone.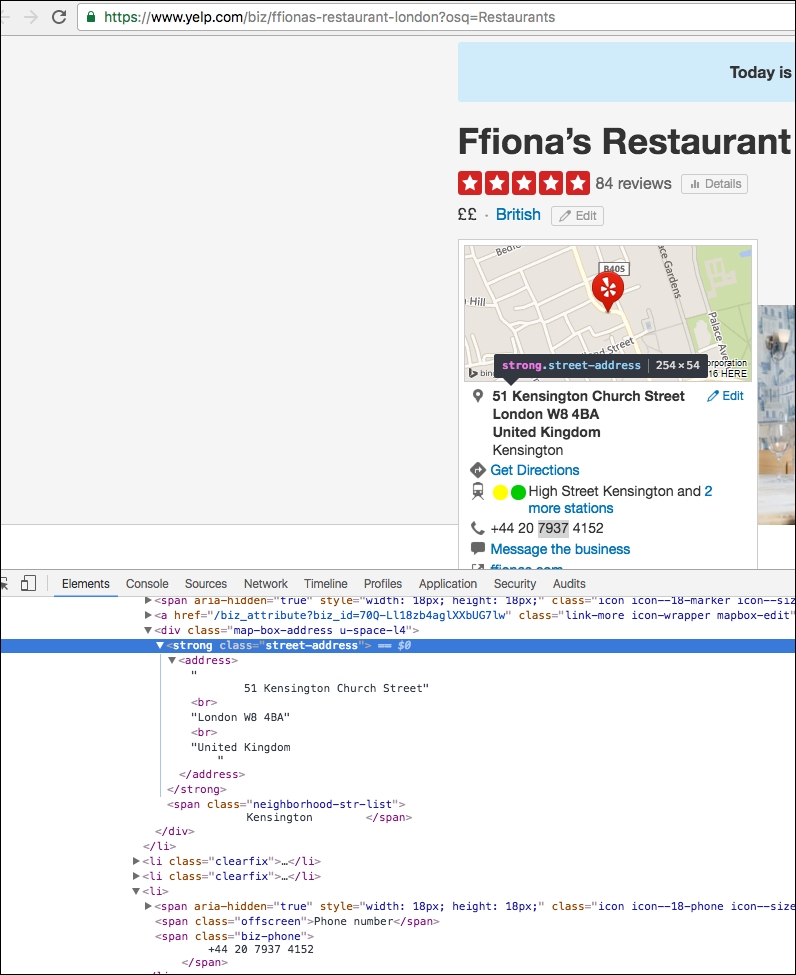
Awesome! So, we now have all the HTML elements that can be used to scrape the data in an automated way. Let's now look at the implementation. The following Python code performs these operations in an automated way:
from bs4 import BeautifulSoup from threading import Thread import urllib #Location of restaurants home_url = "https://www.yelp.com" find_what = "Restaurants" location = "London" #Get all restaurants that match the search criteria search_url = "https://www.yelp.com/search?find_desc=" + find_what + "&find_loc=" + location s_html = urllib.urlopen(search_url).read() soup_s = BeautifulSoup(s_html, "lxml") #Get URLs of top 10 Restaurants in London s_urls = soup_s.select('.biz-name')[:10] url = [] for u in range(len(s_urls)): url.append(home_url + s_urls[u]['href']) #Function that will do actual scraping job def scrape(ur): html = urllib.urlopen(ur).read() soup = BeautifulSoup(html, "lxml") title = soup.select('.biz-page-title') saddress = soup.select('.street-address') phone = soup.select('.biz-phone') if title: print "Title: ", title[0].getText().strip() if saddress: print "Street Address: ", saddress[0].getText().strip() if phone: print "Phone Number: ", phone[0].getText().strip() print "-------------------" threadlist = [] i=0 #Making threads to perform scraping while i<len(url): t = Thread(target=scrape,args=(url[i],)) t.start() threadlist.append(t) i=i+1 for t in threadlist: t.join()OK, great! Now, if we run the preceding Python code, we get the details of the top 10 restaurants in London, along with their names, street addresses and contact numbers. Refer to the following screenshot:
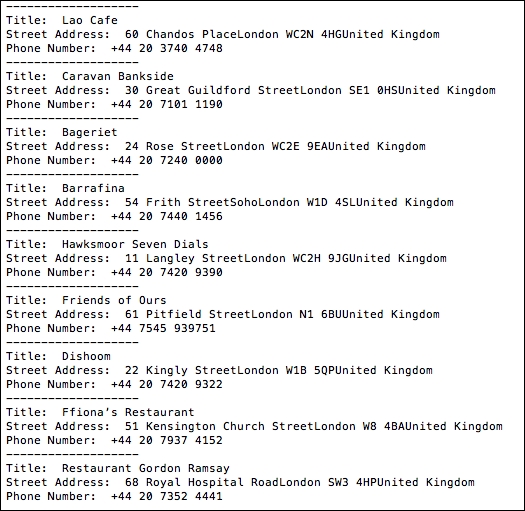
In the preceding screenshot, we get the records of 10 restaurants in London provided by Yelp. Title is the name of the restaurant and Street Address and Phone Number are self-explanatory. Awesome! We did it for Ryan.
In the preceding code snippet, we built the search criteria. We searched on https://yelp.com and looked for restaurants in London. With these details, we got the search URL on Yelp.
We then created a urllib object and used the urlopen() method on this search URL to read() the list of all the restaurants provided by Yelp matching the search criteria. The list of all the restaurants is stored as an HTML page, which is stored in the variable, s_html.
Using the BeautifulSoup module, we created a soup instance on the HTML content so that we could start extracting the required data using the CSS elements.
Initially, we browsed the top 10 results of the search on Yelp and got the URLs of the restaurants. We stored these URLs in the URL Python list. To get the URL, we selected the CSS class name biz-name using the code soup_s.select(.biz-name)[:10].
We also defined a method, scrape(), which takes the restaurant URL as a parameter. In this method, we read the details of the restaurant, such as name, street address, and contact number, using the CSS class names biz-page-title, street-address, and biz-phone, respectively. To get the exact data, we selected the HTML elements using title=soup.select(.biz-page-title) and got the data with title[0].getText().strip(). Note that the select() method returns the found element as an array, so we need to look for index 0 to get the actual text.
We iterated through all the restaurant URLs in a while loop and scraped the URL using the scrape() method to get the details for each restaurant. It prints the name, street address, and contact number for each restaurant on your console, as we saw in the preceding screenshot.
To improve on the performance of our screaping program, we performed data extraction for every restaurant in an independent thread. We created a new thread with t = Thread(target=scrape,args=(url[i],)) and got the results from each of them with the t.join() call.
That’s it, folks! Ryan is extremely happy with this effort. In this example, we helped Ryan and automated a critical business task for him. Throughout this book we'll look at various use cases where Python can be leveraged to automate business processes and make them efficient. Interested in more? Well, see you in the next chapter.