

In order to demonstrate the concepts of each of the main components (Academy, Agent, and Brain/Decision), we will construct a simple example based on the classic multi-armed bandit problem. The bandit problem is so named because of its similarity to the slot machine that is colloquially known in Vegas as the one armed bandit. It is named as such because the machines are notorious for taking the poor tourist's money who play them. While a traditional slot machine has only one arm, our example will feature four arms or actions a player can take, with each action providing the player with a given reward. Open up Unity to the Simple project we started in the last section:
- From the menu, select GameObject | 3D Object | Cube and rename the new object Bandit.
- Click the Gear icon beside the Transform component and select Reset from the context menu. This will reset our object to (0,0,0), which works well since it is the center of our scene.
- Expand the Materials section on the Mesh Renderer component and click the Target icon. Select the NetMat material, as shown in the following screenshot:
- Open the Assets/Simple/Scripts folder in the Project window.
- Right-click (Command Click on macOS) in a blank area of the window and from the Context menu, select Create | C# Script. Name the script Bandit and replace the code with the following:
public class Bandit : MonoBehaviour
{
public Material Gold;
public Material Silver;
public Material Bronze;
private MeshRenderer mesh;
private Material reset;
// Use this for initialization
void Start () {
mesh = GetComponent<MeshRenderer>();
reset = mesh.material;
}
public int PullArm(int arm)
{
var reward = 0;
switch (arm)
{
case 1:
mesh.material = Gold;
reward = 3;
break;
case 2:
mesh.material = Bronze;
reward = 1;
break;
case 3:
mesh.material = Bronze;
reward = 1;
break;
case 4:
mesh.material = Silver;
reward = 2;
break;
}
return reward;
}
public void Reset()
{
mesh.material = reset;
}
}
- This code just simply implements our four armed bandit. The first part declares the class as Bandit extended from MonoBehaviour. All GameObjects in Unity are extended from MonoBehaviour. Next, we define some public properties that define the material we will use to display the reward value back to us. Then, we have a couple of private fields that are placeholders for the MeshRenderer called mesh and the original Material we call reset.
We will implement the Start method next, which is a default Unity method that runs when the object starts up. This is where we will set our two private fields based on the object's MeshRenderer. Next comes the PullArm method which is just a simple switch statement that sets the appropriate material and reward. Finally, we will finish up with the Reset method where we just reset the original property. - When you are done entering the code, be sure to save the file and return to Unity.
- Drag and drop the Bandit script from the Assets/Simple/Scripts folder in the Project window and drop it on the Bandit object in the Hierarchy window. This will add the Bandit component to the object.
- Select the Bandit object in the Hierarchy window and then in the Inspector window click the Target icon and select each of the material slots (Gold, Silver, Bronze), as shown in the following screenshot:
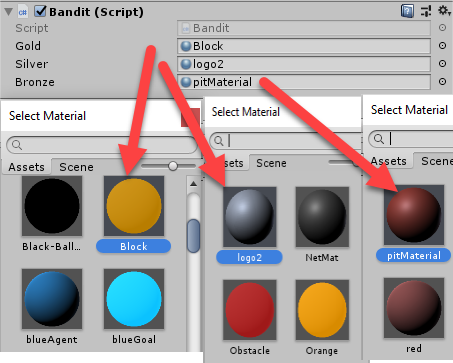
This will set up our Bandit object as a visual placeholder. You could, of course, add the arms and make it look more visually like a multi-armed slot machine, but for our purposes, the current object will work fine. Remember that our Bandit has 4 arms, each with a different reward.



