-
Book Overview & Buying

-
Table Of Contents

Deep Learning with TensorFlow 2 and Keras - Second Edition
By :
Deep Learning with TensorFlow 2 and Keras
By:
Overview of this book
Deep Learning with TensorFlow 2 and Keras, Second Edition teaches neural networks and deep learning techniques alongside TensorFlow (TF) and Keras. You’ll learn how to write deep learning applications in the most powerful, popular, and scalable machine learning stack available.
TensorFlow is the machine learning library of choice for professional applications, while Keras offers a simple and powerful Python API for accessing TensorFlow. TensorFlow 2 provides full Keras integration, making advanced machine learning easier and more convenient than ever before.
This book also introduces neural networks with TensorFlow, runs through the main applications (regression, ConvNets (CNNs), GANs, RNNs, NLP), covers two working example apps, and then dives into TF in production, TF mobile, and using TensorFlow with AutoML.
Table of Contents (19 chapters)
Preface

 Free Chapter
Free Chapter
Neural Network Foundations with TensorFlow 2.0
TensorFlow 1.x and 2.x
Regression
Convolutional Neural Networks
Advanced Convolutional Neural Networks
Generative Adversarial Networks
Word Embeddings
Recurrent Neural Networks
Autoencoders
Unsupervised Learning
Reinforcement Learning
TensorFlow and Cloud
TensorFlow for Mobile and IoT and TensorFlow.js
An introduction to AutoML
The Math Behind Deep Learning
Tensor Processing Unit
Other Books You May Enjoy
Index

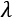
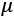 from it. Then, the result is divided by
from it. Then, the result is divided by 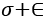 , the sum of batch variance
, the sum of batch variance 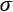 and a small number
and a small number