Data Analytics Made Easy is an accessible beginner’s guide for anyone working with data. The book interweaves four key elements:
Data visualizations and storytelling – Tired of people not listening to you and ignoring your results? Don’t worry; chapters 7 and 8 show you how to enhance your presentations and engage with your managers and co-workers. Learn to create focused content with a well-structured story behind it to captivate your audience.
Automating your data workflows – Improve your productivity by automating your data analysis. This book introduces you to the open-source platform, KNIME Analytics Platform. You’ll see how to use this no-code and free-to-use software to create a KNIME workflow of your data processes just by clicking and dragging components.
Machine learning – Data Analytics Made Easy describes popular machine learning approaches in a simplified and visual way before implementing these machine learning models using KNIME. You’ll not only be able to understand data scientists’ machine learning models; you’ll be able to challenge them and build your own.
Creating interactive dashboards – Follow the book’s simple methodology to create professional-looking dashboards using Microsoft Power BI, giving users the capability to slice and dice data and drill down into the results.
Often, when we deal with real-world data analytics, we face a reality that is as annoying as ubiquitous: data can be dirty. The format of text and numbers, the order of rows and columns, the presence of undesired data points, and the lack of some expected values are all possible glitches that can slow down or even jeopardize the process of creating some value from data. Indeed, the lower the quality of the input data, the less useful the resulting output will be. This inconvenient truth is often summarized with the acronym GIGO: Garbage In, Garbage Out. As a consequence, one of the preliminary phases of a data analytics workflow is Data Cleaning, meaning the process of systematically identifying and correcting inaccurate or corrupt data points. Let's learn how to build a full set of data cleaning steps in KNIME through a realistic example.
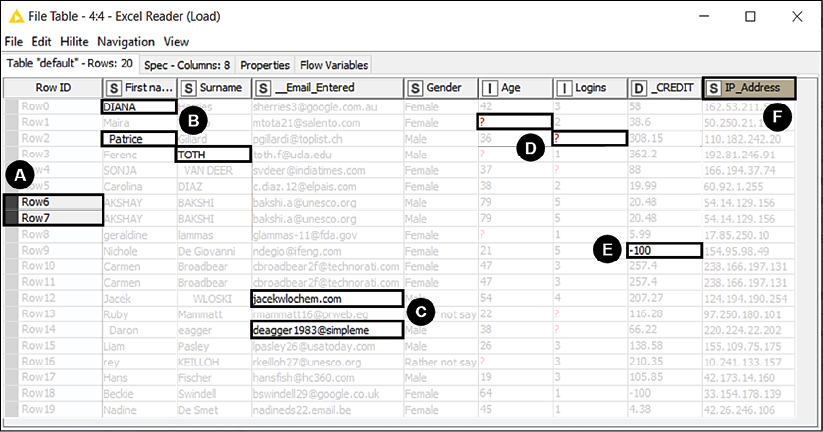
In this tutorial, we are going to clean a table that captures information on the users of an e-commerce website, such as name, age, email address, available credit, and so on. This table has been generated by pulling directly from the webserver all the available raw data. Our ultimate objective is to create a clean list of contactable users, which we can leverage as a mailing list for sending email newsletters. Since the list of users constantly changes (as some subscribe and unregister themselves every day), we want to build a KNIME workflow that systematically cleans the latest data for us every time we want to update our mailing list:
Figure 2.14: The raw data: we certainly have some cleaning chores ahead
As you can see from Figure 2.14, a first look at the raw table unveils a series of data quality flaws to be looked after. For instance:
Some rows appear to be duplicated.
Names and surnames have inconsistent capitalization and some unpleasant blank characters. Additionally, instead of having two separate fields for the name, we would prefer to have a single column (currently missing) with the full name of each person.
Some email addresses are wrongly formatted (as they miss the @ symbol or the full domain), making the respective users not contactable.
Various values are missing, leaving the cell empty.
In KNIME, missing values are indicated with a red question mark symbol, ?. For reference, in computer science, a missing value is referred to with the expression NULL.
Some credit values are negative. We know that according to company policy these users should be considered inactive and shall not be contacted, so we can remove them from the list.
Some columns are not needed. In this case, we can drop the column holding the IP address of the user since it cannot be used for sending a newsletter or to personalize its content.
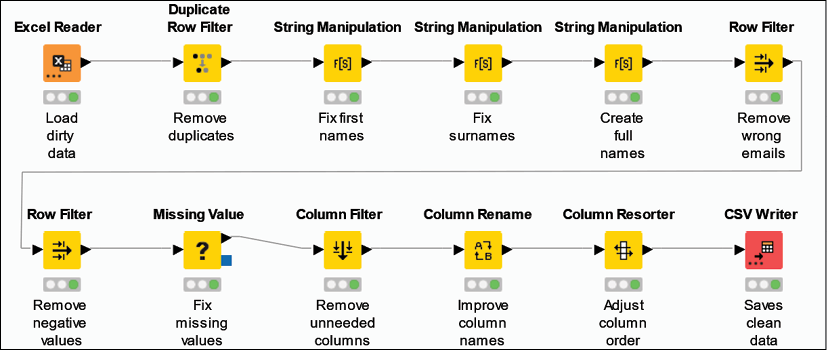
We have an Excel file (DirtyData.xlsx) with an excerpt of the raw data, showing samples of all those issues listed above. By using this file as a base, we can build a KNIME workflow that polishes the data and exports a good-looking and ready-to-use mailing list. Let's do this one step at a time:
First of all, we need to create a blank workflow (you can do this as seen in the previous example or—alternatively—you can go to File | New... and then select New KNIME Workflow): we can call it Cleaning data.
To load the data, we can either drag and drop the source file on the Workflow Editor or grab the Excel Reader node from the repository and place it in the blank editor space.
Excel Reader
This node (IO > Read) opens Excel files, reads the content of the specified worksheet, and makes it available as a table at its output port. In the main tab of the configuration dialog, after indicating which file or folder to open (click on Browse... to change), you can specify (Sheet selection) the worksheet to consider: by default, the node will read the first sheet available in the workbook but you can indicate the name of a specific sheet or its position. If your sheet includes the column headers, you can ask KNIME to use them as column names in the resulting table: in the section Column Header, you can select which row contains the column headers. You can also restrict the reading to a portion of the sheet, by specifying the range of columns and rows to read within the Sheet area section. You can check whether the node is configured correctly by looking at the bottom of the window, which gives you a preview of what KNIME is reading from the file:
Figure 2.15: Configuration of the Excel Reader node: select file, sheets, and areas to read
If you want to apply some transformations (like renaming columns, reordering them, and so on) as the data gets read, you can use the Transformation tab, which works the same as in the CSV Reader node we have already met.
Configuring this node will be pretty simple in our case: we should just select the file to open and leave all other parameters unchanged as the default selection looks good for us. We could use the Transformation tab to make some adjustments to the format but we will do it later using the appropriate nodes, so we can keep it easy for now.
To remove the duplicated rows we can use a new node that does exactly that: its name is Duplicate Row Filter.
Duplicate Row Filter
This node (Manipulation > Row > Filter) identifies rows having the same values in selected columns and manages them accordingly. In the first tab of the configuration window, you select which columns should be considered for the search of duplicates.
If more than one column is selected, the node will consider duplicates as only rows that have exactly the same values across all the selected columns. In the configuration of many KNIME nodes, we will be asked to select a subset of columns, so it makes sense to spend some time on becoming acquainted with the interface:
The panel on the right (having a green border) contains the columns included in your selection while the one on the left (red-bordered) displays the excluded columns.
By double-clicking on the names of the columns or by using the four arrow buttons in the middle, you can transfer the columns across panes.
If you have many columns, you can look them up by name using the Filter textboxes at the top of each pane.
If you want to select columns by patterns in their names (like the ones starting with an A) or by type (integers, decimal numbers, strings, and so on), you can select the other options available on the radio selector on top (Wildcard/Regex Selection or Type Selection).
The second tab in the configuration window (titled Advanced) lets you decide what to do with the duplicate rows once identified (by default, they get removed but you can also keep them and add an extra column specifying whether they are duplicates or not) and which rows should be kept among the duplicates (by default, the first row is kept and all others are removed, but other strategies are available):
Figure 2.16: Configuration of the Duplicate Row Filter: select which columns to use for detecting duplicate rows
Let's implement the Duplicate Row Filter node and connect it with the output port of the Excel Reader. The new node will now show an amber status light, signaling that it can run with its default behavior, although we want to do some configuration first.
Double-click on the node to enter its configuration window. Since we don't want to bombard the same user with multiple emails, we should keep one entry per email address, removing all rows having a duplicate address. Hence, from the configuration window, we move all columns to the left and we keep only __Email_Entered on the right. We click on OK and run the node (F7).
Our curiosity makes it impossible to refrain from checking whether this node has worked well. So, we have a look at the data appearing on its output port (right-click and the last icon with the magnifying lens or Shift + F6) and we notice that a couple of rows having duplicated email addresses were removed as expected.
We can now proceed to fix the formatting of names and surnames. To do so, we will start using a very versatile node for working on textual data called String Manipulation.
String Manipulation
This node (Manipulation > Column > Convert & Replace) applies transformations to strings, making it possible to reformat textual data as needed. The node includes a large set of pre-built functions for text manipulation, such as replacement, capitalization, and concatenation, among others:
Figure 2.17: String Manipulation: build your text transformation selecting functions and columns to use
The configuration window provides several panels:
The Expression box is used to specify the overall formula that implements the desired transformation. In most cases, you can build the expression by just using your mouse, clicking on the functions to use and on the columns upon which to apply them.
The Function list includes all available transformations. For instance, the function upperCase() will convert a string in all-capital letters. When you double-click on a function here, it will get added to your expression.
The Description box is a handy source of help, showing a description and some examples for each available function as soon as you select it from the list.
The Column List will show you all available columns in the table. By double-clicking on them, you add them to the expression: they will show with a dollar sign character ($) on either side to indicate a column.
At the bottom, you find a radio button to decide where to store your result. You can either Append it as a new column or Replace an existing one.
Table 2.1 summarizes the most useful functions available within this node.
Function
Description
Example
Result
strip(x)
Removes any whitespace from the beginning and the end of a string.
strip(" Hi! ")
"Hi!"
upperCase(x),
lowerCase(x)
Converts all characters to upper or lower case.
upperCase("Leonardo")
"LEONARDO"
capitalize(x)
Converts first letters of all words in a string to upper case.
capitalize("bill kiddo")
"Bill Kiddo"
compare(x,y)
Compares two strings and returns 0 if they are equal and -1 or 1 if they differ, depending on their alphabetical sorting.
compare("Budd","Budd")
0
replace(x,y,z)
Replaces all occurrences of substring y within x with z.
replace("cool goose","oo","u")
"cul guse"
removeChars(x,y)
Removes from string x all characters included in y.
removeChars("No vowels!","aeiou")
"N wwls!"
join(x,y,...)
Concatenates any number of strings in a single string.
join("Hi ","the","re")
"Hi there"
length(x)
Counts the number of characters in a string.
length("Analytics is for everyone!")
26
Table 2.1: Useful functions within String Manipulation
This node is perfect for our needs as we have a few strings to manipulate. We need to fix the capitalization of names and surnames, remove those bad-looking whitespaces, and create a new column with the full name:
Let's implement the String Manipulation node, dragging it from the repository and connecting the output of the previous node with the input of this new one. Double-click on the node and its configuration dialog appears. Let's start with the column First name. We want to see a nice upper-case character at the beginning of every word and we also require whitespaces to be stripped from both ends of the string. Let's build the expression by double-clicking first on capitalize() and strip() from the Function box and then on First name from the Column list. By clicking in this order, we should have obtained the expression capitalize(strip($First name$)), which is exactly what we wanted. In this case, we want to substitute the raw version of the first name with the result of this expression, so we need to select Replace column and then First name. We are all set so we can click on OK and close the window.
Now we want to repeat the same for the surname. We'll use another String Manipulation node for it. To make it faster we can also copy and paste the icon of the node from the Workflow Editor, with the usual Ctrl + C and Ctrl + V key combinations. We need to repeat the configuration described in the previous step: the only difference is that now we apply it to column Surname instead of First name. Just make sure that both the expression and the Replace column setting refer to Surname this time.
Both parts of the name look fine now as they show no extra spaces and boast good-looking capitalization. As required by our business case, we need to create a new column carrying the full name of each user, combining first name and surname. Once again, we can use the String Manipulation node for this: let's get one more node of these in the Workflow Editor, make the connection, and open the configuration page. This time, we need to concatenate two strings so we can leverage the join() function. Let's double-click first on join() from the Function box and then on First name from the Column list. Since we want names and surnames to be separated by a blank space, we need to add this character on the expression, by typing the sequence ," ", in the expression box just after $First name$. We complete the expression by double-clicking on the column Surname and we are done. The overall expression should be: join($First name$," ",$Surname$). Before closing, we need to decide where to store the result. This time we want to create a new column so we select Append and then type the name of the new column, which could be Full name. Click on OK and check the results.
Since in the end, we are going to keep only the Full name column, we could have combined the last three nodes in a single one. In fact, Full name can be created at once with the expression: join(capitalize(strip($First name$))," ",capitalize(strip($Surname$))).
We took the longer route to get some practice with the node. It's up to you to decide which version to keep in your workflow.
With all names fixed, we can move on to the next hurdle and remove the ill-formatted email addresses. It's time to introduce a new node that will be ubiquitous in our future KNIME workflows: Row Filter.
Row Filter
This node (Manipulation > Row > Filter) applies filters on rows according to the criteria you specify. Such criteria can either be based on values of a specific column to test (like all strings starting with A or all numbers greater than 5.2) or on the position of the row in the table (for instance only the top 20 rows). To configure the node, you need to first specify the type of criteria you would like to apply using the selector on the left. You also need to specify if those rows that match your criteria should be kept in your workflow (Include rows...) or should be dropped, keeping all others (Exclude rows...). You have multiple ways to specify the criteria behind your filtering:
Filter by attribute value: In this case, you will be presented on the right with the full list of columns available so that you can pick the one to consider for the filtering (Column to test). Once you pick the column, you need to describe the logic for the selection in the box below (Matching criteria). You have three options:
The first one (use pattern matching) will check if the value (considered as a string) adheres to the pattern you specify in the textbox. You can enter a specific value like maria: this will match rows like "MARIA" or "Maria," unless you check the case sensitive match option, which would consider the lower and upper cases as different. Another option is to use wild cards in your search pattern (remember to tick contains wild cards): in this case, the star character "*" will stand for any sequence of characters (so "M*" selects all names starting with "M" like "Mary" and "Mario") while the question mark "?" will match any single character ("H?" refers to any string of two characters starting with "H," so it will include "Hi" and exclude "Hello"). If you want to implement more complex searches, you could also use the powerful Regular Expressions (RegEx), which offer great flexibility in setting criteria.
The second one (use range checking) is great with numbers as it lets you set any kind of interval: you can specify a lower bound (including all numbers that are greater or equal than that) or an upper bound (lower or equal) or both (making it a closed interval).
Remember that bounds are always considered as included in the interval. If you want to exclude the endpoint of an interval, you need to reverse the logic of your filtering. For instance, if you want to include all non-zero, positive numbers you need to select the option Exclude rows by attribute value and set 0 as the upper bound.
The third option is to match only the rows that have a missing value in the column under test.
Filter by row number: This way you can specify which is the first and the last row to match, considering the current sorting order in the table. So if you put 1 in the First row number selector and then 1 in Last row number, you will match only the top 10 rows of the table. If you want to match only the rows after a certain position, like from the 100th onwards, you can set the threshold in the first selector (100) and tick the check box below (to the end of the table).
Filter by row ID: You could test row IDs against some regular expressions as well, although this route is rarely used:
Figure 2.18: Configuration dialog for Row Filter: specify which rows to keep or remove from your table
If your filtering criteria require several columns to be tested, you can use multiple instances of this node in a series, each time looking at a different column. An alternative is to use a different node called Rule-based Row Filter, which lets you define several rules for filtering at once. Other nodes, such as Row Filter (Labs) and Rule-based Row Filter (Dictionary), can do more sophisticated filtering if needed. Check them out if you need to.
Let's see our new node in action straight away as we filter out all the email addresses that do not look valid:
Implement the Row Filter node, connect it downstream, and open its configuration dialog by double-clicking on it. Since we want to keep only the rows matching certain column criteria, let's select the first option from the radio button on the left (Include rows by attribute value) and, on the right, pick the column with the email address __Email_Entered. One simple pattern we can use for checking the validity of an email address is the wild card expression *@*.*. This will check for all strings that have at least an @ symbol followed by a dot . with some text in between. This is not going to be the most thorough validity check for email addresses, but it will certainly spot the ones that are clearly irregular and is good enough for us at this stage. Remember to tick the contains wild cards checkbox and click OK to move on.
We have yet more filtering to be done. We want to remove all rows displaying a negative credit: those users are inactive and should not be added to our mailing list. Let's implement an additional Row Filter node and put it next to the previous one, creating the right connections across the ports. We will again use the Include rows by attribute value option but the matching criteria will be set as range checking (second radio button on the right). By setting 0 as Lower bound, we are good to go since all negative values will be filtered out. We can click OK and move on to the next challenge.
At this point, we want to manage the little red question marks appearing here and there in the table, signaling that some values are missing. Also, in this case, KNIME offers a powerful node to manage this situation quickly, with a couple of clicks.
Missing Value
The node (Manipulation > Column > Transform) handles missing values (NULLs) in a table, offering multiple methods for imputing the best available replacement. In the first tab of the configuration window (Default), you can define a default treatment option for all columns of a certain data type (strings, integer, and double) by selecting it in the dropdown menus. The second tab (Column settings) allows you to set a specific strategy for each individual column by double-clicking on the name of the column from the list on the left and setting the strategy through the menu that will appear.
Unless you have a large number of columns that you want to treat with the same missing value strategy, it's best to be explicit and use the second tab. That way you only impute missing values for the precise columns specified.
You have a vast list of possible methods to treat your missing values. The most useful ones are:
Remove Row: Gets rid of the row altogether if the value is missing.
Fix Value: Replaces the NULL with a specific value you have to enter in the box that will appear below. All rows with missing values will get the same fix replacement.
Minimum/Maximum/Mean/Median/Most Frequent Value: Calculates a summary statistic on the distribution over all existing values in the column and uses it as a fixed replacement value.
If you substitute missing values with the median of a numeric column, your imputed values are going to stick "in the middle" of the existing distribution, making your inference less disruptive and more robust. Of course, this will depend on your business cases and on the actual distribution of data, but it's worth giving this approach a try.
Previous/Next: Replaces the missing value with the previous or the next non-missing value in the column, using the current order of rows in the table.
Linear Interpolation: Substitutes missing values with the linear interpolation between the previous and the next non-missing values in the column. If your column represents values changing over time (we call them time series), this handler might offer a smooth way to fill the gaps.
Moving Average: Substitutes the missing values with a moving average calculated over a certain number of non-missing values appearing in the table just before the missing value (lookbehind window) or after it (lookahead window). For instance, if you have for a column a sequence of values such as [2, 3, 4, NULL] and you apply a lookbehind window of size 2, the NULL value will be substituted for 3.5, which is the average of 3 and 4. For this and the previous handlers, you want to make sure your table is properly sorted (like, in a time series, by increasing time).
Figure 2.19: Configuration of Missing Value: decide how to manage the empty spots of your table
Going back to our case, we noticed that we have two columns displaying some question marks. Let's manage them appropriately by leveraging the Missing Value node:
Drag the Missing Value node on your workflow and connect it properly. Let's jump straight to the second tab of its configuration window (Column settings), as we want to keep control of which handling strategy we shall adopt for each column in need. For column Age (double-click on it from the list on the left), we can select Median: by doing so, we will assign an age to those users missing one that is not "far off" the age that most users tend to have in our table. When it comes to the number of times users have logged in (Logins column) we assume that the lack of a value means that they haven't logged in yet. So the best strategy to select will be Fix Value, keeping 0 as a default value for all. We can click on OK and close this dialog.
Let's check how our chain of transformations is looking at the minute. If we click on the last node, execute it (F7), and check its output port view (Shift + F6), we can breathe a sigh of relief: no missing values, no negative credits, and both names and email addresses look reasonably formatted.
The only steps left ahead of us are of an aesthetic nature: we want to drop the columns we don't need, sort the ones remaining, and give them a more intuitive name, before finally saving the output file. We are going to need a few more nodes to complete this last bit.
Column Filter
This node (Manipulation > Column > Filter) drops unneeded columns in a table. The only required step for its configuration is to select which columns to keep at the output port (the green box on the right) and which ones to filter out (the red box on the left):
Figure 2.20: Configuration of Column Filter: which columns would you like to keep?
Add the Column Filter node to the workflow and exclude the columns we no longer need (First Name, Surname, and IP_Address) by moving them onto the left panel.
Column Rename
The node lets you change the names and the data types of columns. To configure it, double-click on the columns you would like to edit (you'll find a list on the left) and tick the Change box: you will then be able to enter the new names in the box beside. To change the data type of a column and convert all its values, you can use the drop-down menu on the right. The menu will be prepopulated with a list of possible data types each column can be safely converted into:
Figure 2.21: Configuration of Column Rename: pick the best names for your columns
We can now use the Column Rename node to change the headers in our table. The only ones that need some makeup are __Email_Entered, which can become simply Email, and _Credit, which can be renamed to Credit.
Column Resorter
This node (available in Manipulation > Column > Transform) changes the order of columns in a table. In the configuration window, you will find, on the left, all columns available at the input port, and on the right, a series of buttons to move them around. Select the column you wish to move across and then click on the different buttons to move columns up or down, place columns first or last in the table, or sort them in alphabetical order. If different columns appear at the input port (imagine the case where your source file is coming in with some new columns), they will be placed where the <any unknown new column> placeholder lies:
Figure 2.22: Configuration of Column Resorter: shuffle your columns to the desired order
The last transformation required is to slightly change the order of columns in the table. In fact, the Full name column was added earlier in the process and ended up appearing as the last column while we would like it to be the first. Just select the column and click on Move First to fix it as needed.
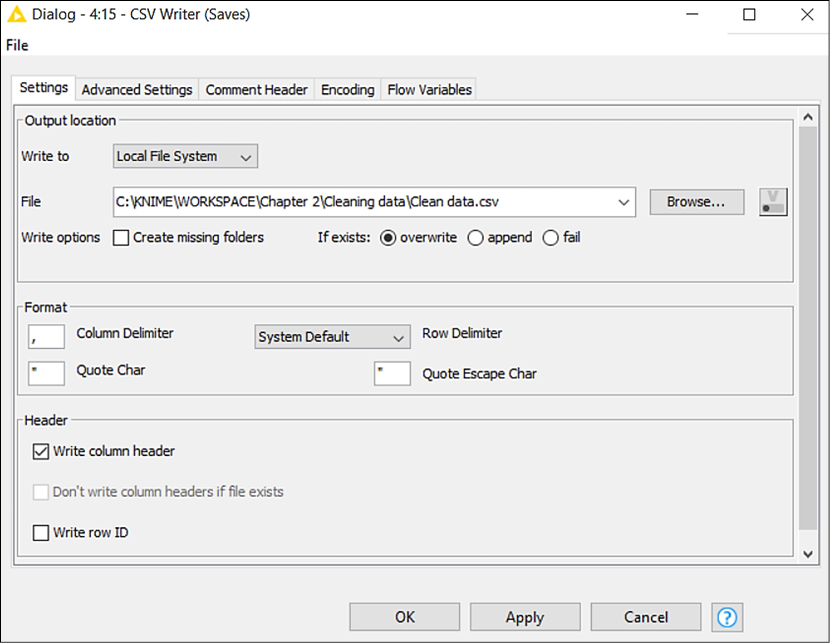
CSV Writer
This node (IO > Write) saves the input data table into a CSV file on the local disk or to a remote location. The only required configuration step is to specify the full path of the file to create: you can click on the Browse... button to select the desired folder. The other configuration steps (not required) let you: change the format of the resulting CSV file like column delimiters (Format section), keep or remove headers as the first row (Write column header), and compress the newly generated file in .gzip format to save space on disk (go to the Advanced Settings tab for this):
Figure 2.23: Configuration of CSV Writer: save your table as a text file
The very last step of our process is to save our good-looking table as a CSV file. We implement the CSV Writer node, connect it, and do the only piece of required configuration, which is to specify where to save the new file and how to name it. Click OK to close the window and execute the node to finally write the file on your disk.
Well done for completing your second data workflow! The routine required for building a clean mailing list out of a messy raw dataset required a dozen nodes and some of our time, but the effort was certainly worth it. Now we can clean up any number of records whenever we like by just re-running the same workflow, making sure that the name of the input file and its path stay the same. To do so, you will just need to: reset the workflow (right-click on the name of the workflow in the Explorer on the left and then click on Reset or just reset the first node pressing F8 after having selected it), and execute it again (the simplest way is to just press Shift + F7 on your keyboard or execute the last node with a right-click and select Execute):
Figure 2.24: The full data cleaning workflow: twelve nodes to make our user data spotless
Read this chapter and the full book FREE of cost - No Credit card required!
Plus access over 9,000 other expert tech books and videos just by signing up - No commitment!
CONTINUE READING
83
Tech Concepts
36
Programming languages
73
Tech Tools
Unlimited access to the largest independent learning library in tech of over 8,000 expert-authored tech books and videos.
Innovative learning tools, including AI book assistants, code context explainers, and text-to-speech.
50+ new titles added per month and exclusive early access to books as they are being written.






 Free Chapter
Free Chapter
 Excel Reader
Excel Reader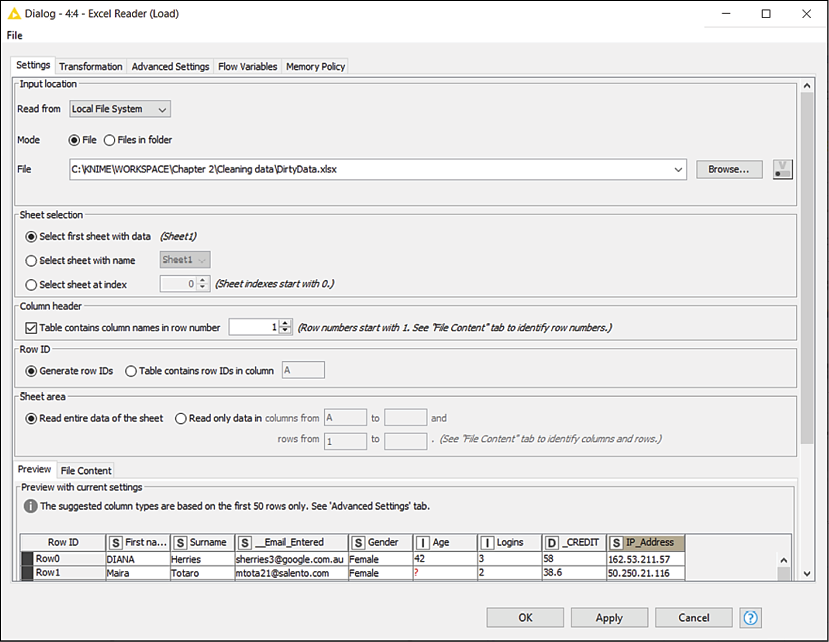
 Duplicate Row Filter
Duplicate Row Filter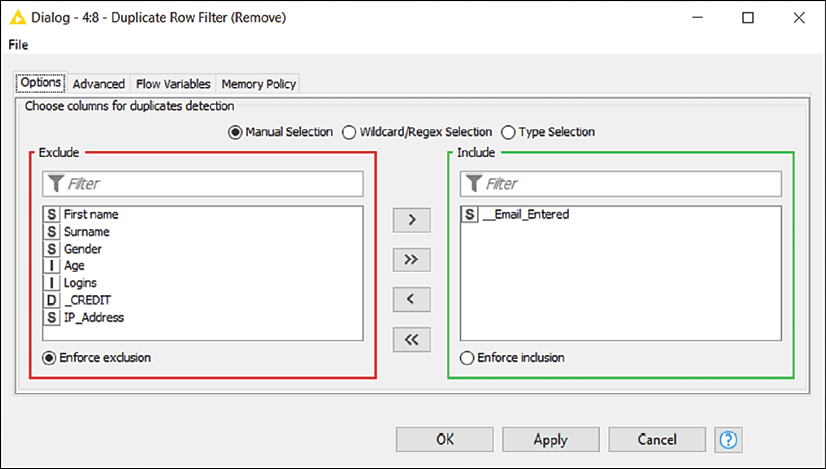
 String Manipulation
String Manipulation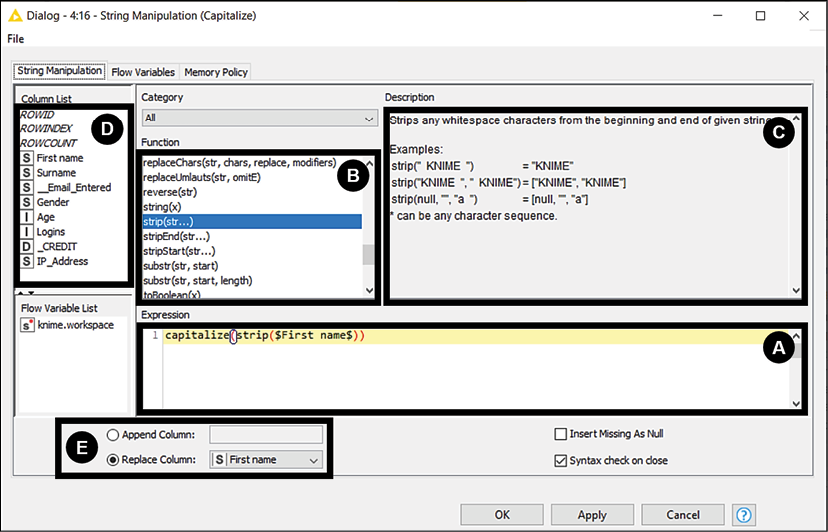
 Row Filter
Row Filter
 Missing Value
Missing Value
 Column Filter
Column Filter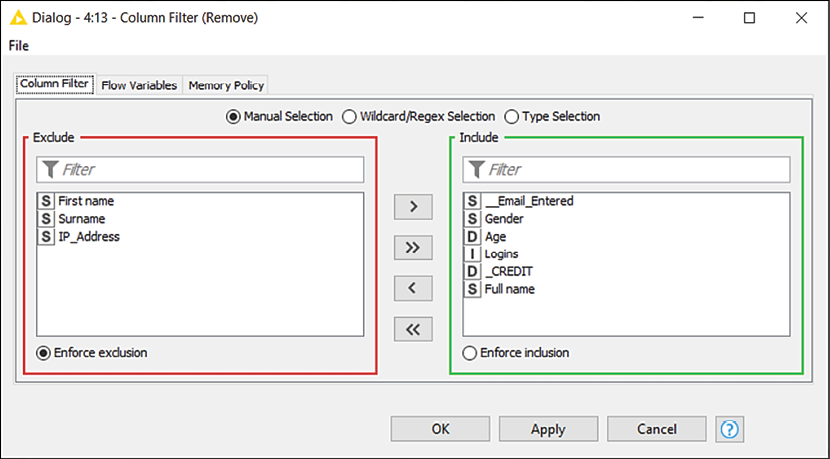
 Column Rename
Column Rename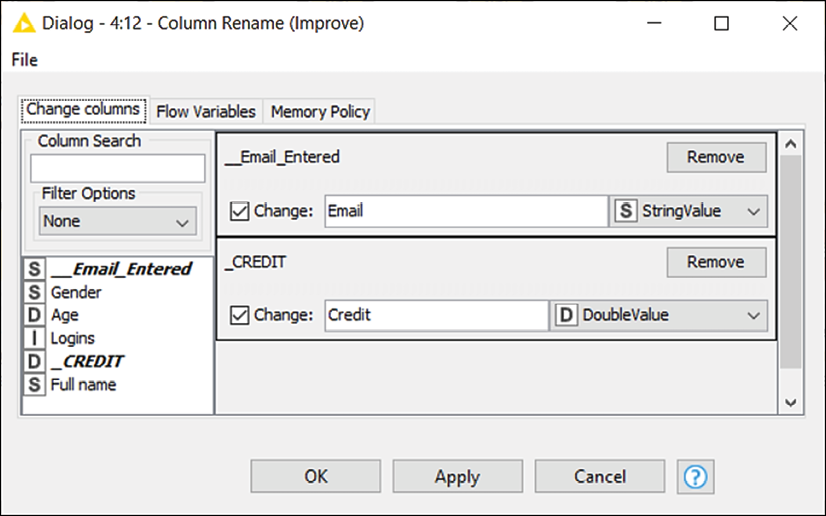
 Column Resorter
Column Resorter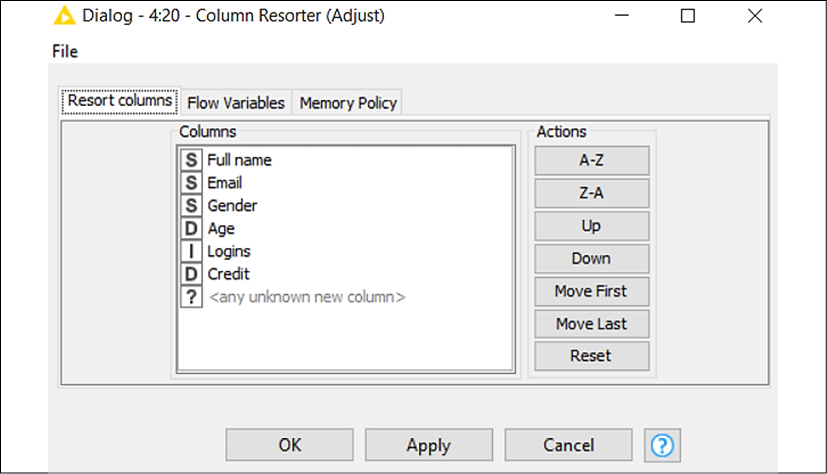
 CSV Writer
CSV Writer