-
Book Overview & Buying

-
Table Of Contents

Mastering Machine Learning Algorithms - Second Edition
By :
Mastering Machine Learning Algorithms
By:
Overview of this book
Mastering Machine Learning Algorithms, Second Edition helps you harness the real power of machine learning algorithms in order to implement smarter ways of meeting today's overwhelming data needs. This newly updated and revised guide will help you master algorithms used widely in semi-supervised learning, reinforcement learning, supervised learning, and unsupervised learning domains.
You will use all the modern libraries from the Python ecosystem – including NumPy and Keras – to extract features from varied complexities of data. Ranging from Bayesian models to the Markov chain Monte Carlo algorithm to Hidden Markov models, this machine learning book teaches you how to extract features from your dataset, perform complex dimensionality reduction, and train supervised and semi-supervised models by making use of Python-based libraries such as scikit-learn. You will also discover practical applications for complex techniques such as maximum likelihood estimation, Hebbian learning, and ensemble learning, and how to use TensorFlow 2.x to train effective deep neural networks.
By the end of this book, you will be ready to implement and solve end-to-end machine learning problems and use case scenarios.
Table of Contents (28 chapters)
Preface

Machine Learning Model Fundamentals
 Free Chapter
Free Chapter
Loss Functions and Regularization
Introduction to Semi-Supervised Learning
Advanced Semi-Supervised Classification
Graph-Based Semi-Supervised Learning
Clustering and Unsupervised Models
Advanced Clustering and Unsupervised Models
Clustering and Unsupervised Models for Marketing
Generalized Linear Models and Regression
Introduction to Time-Series Analysis
Bayesian Networks and Hidden Markov Models
The EM Algorithm
Component Analysis and Dimensionality Reduction
Hebbian Learning
Fundamentals of Ensemble Learning
Advanced Boosting Algorithms
Modeling Neural Networks
Optimizing Neural Networks
Deep Convolutional Networks
Recurrent Neural Networks
Autoencoders
Introduction to Generative Adversarial Networks
Deep Belief Networks
Introduction to Reinforcement Learning
Advanced Policy Estimation Algorithms
Other Books You May Enjoy
Index

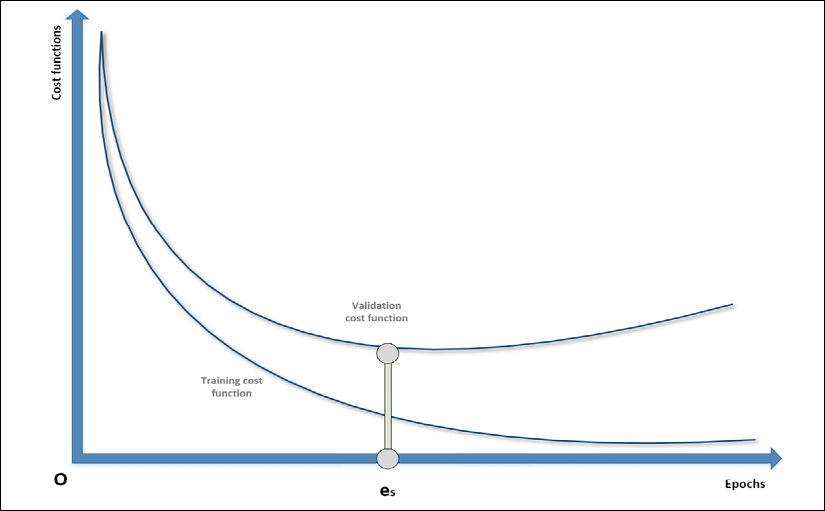
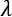 controls the strength of the regularization, which is expressed through the function
controls the strength of the regularization, which is expressed through the function 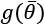 . A fundamental condition on
. A fundamental condition on 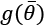 is that it must be differentiable so that the new composite cost function can still be optimized using SGD algorithms. In general, any regular function can be employed; however, we normally need a function that can contrast the indefinite growth of the parameters.
is that it must be differentiable so that the new composite cost function can still be optimized using SGD algorithms. In general, any regular function can be employed; however, we normally need a function that can contrast the indefinite growth of the parameters.
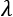 and to the kind of regularization used.
and to the kind of regularization used.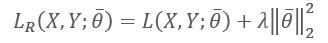
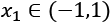 and
and 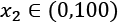 , the shrinkage will affect x1 much more than x2.
, the shrinkage will affect x1 much more than x2.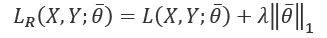
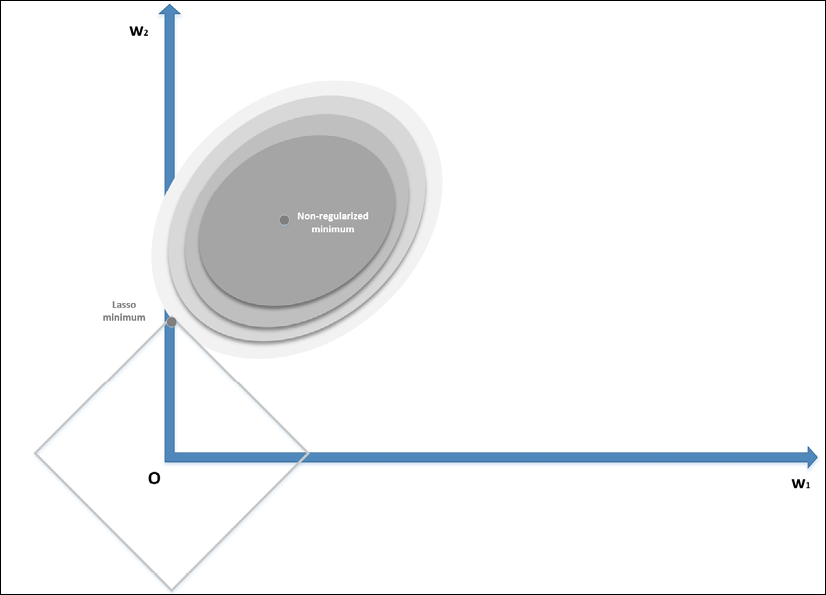
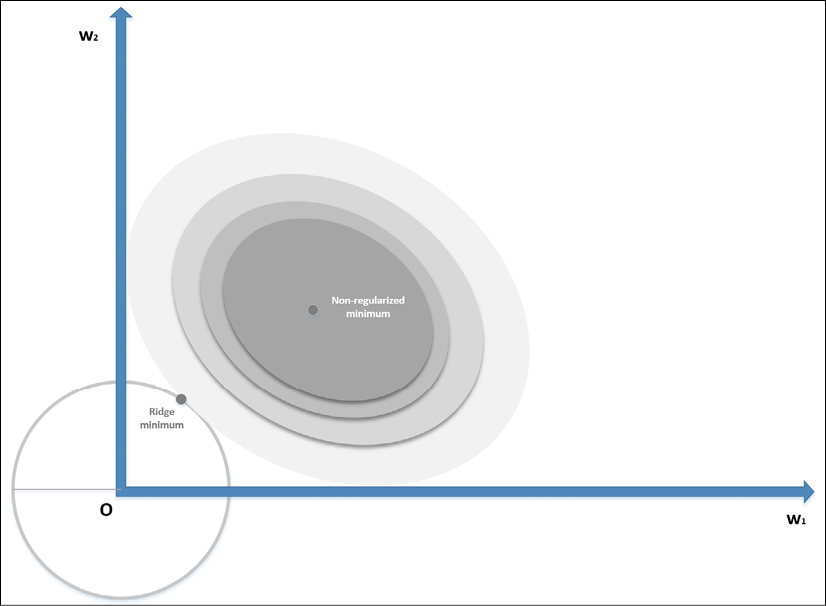
 ). If we consider a generic line, the probability of that line being tangential to the square is higher at the corners, where at least one parameter is null—exactly one parameter in a bidimensional scenario. In general, if we have a vectorial convex function f(x) (we provide a definition of convexity in Chapter 7, Advanced Clustering and Unsupervised Models), we can define:
). If we consider a generic line, the probability of that line being tangential to the square is higher at the corners, where at least one parameter is null—exactly one parameter in a bidimensional scenario. In general, if we have a vectorial convex function f(x) (we provide a definition of convexity in Chapter 7, Advanced Clustering and Unsupervised Models), we can define:
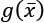 is also convex. The regularization term is always non-negative, and therefore the minimum corresponds to the norm of the null vector.
is also convex. The regularization term is always non-negative, and therefore the minimum corresponds to the norm of the null vector. 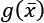 , we also need to consider the contribution of the gradient of the norm in the ball centered in the origin, where the partial derivatives don't exist. Increasing the value of p, the norm becomes smoothed around the origin, and the partial derivatives approach zero for
, we also need to consider the contribution of the gradient of the norm in the ball centered in the origin, where the partial derivatives don't exist. Increasing the value of p, the norm becomes smoothed around the origin, and the partial derivatives approach zero for 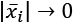 .
.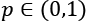 allows an even stronger sparsity, but is non-convex (even if L0 is currently employed in the quantum algorithm QBoost). With p = 1 the partial derivatives are always +1 or -1, according to the sign of
allows an even stronger sparsity, but is non-convex (even if L0 is currently employed in the quantum algorithm QBoost). With p = 1 the partial derivatives are always +1 or -1, according to the sign of 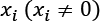 . Therefore, it's easier for the L1-norm to push the smallest components to zero, because the contribution to the minimization (for example, with gradient descent) is independent of xi, while an L2-norm decreases its speed when approaching the origin.
. Therefore, it's easier for the L1-norm to push the smallest components to zero, because the contribution to the minimization (for example, with gradient descent) is independent of xi, while an L2-norm decreases its speed when approaching the origin.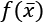 , which bounds the value of the global minimum; however, it may help the reader to develop an intuitive understanding of the concept. It's possible to find further, more mathematically rigorous details in Sra S., Nowozin S., Wright S. J. (edited by), Optimization for Machine Learning, The MIT Press, 2011.
, which bounds the value of the global minimum; however, it may help the reader to develop an intuitive understanding of the concept. It's possible to find further, more mathematically rigorous details in Sra S., Nowozin S., Wright S. J. (edited by), Optimization for Machine Learning, The MIT Press, 2011.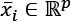 and the optimal accuracy is achieved with this sample size when all the features are informative when k < p features are irrelevant, we need approximately 1000 + O(log k) samples. This is a simplification of the original result; for example, if p = 5000 and 500 features are irrelevant, assuming the simplest case, we need about
and the optimal accuracy is achieved with this sample size when all the features are informative when k < p features are irrelevant, we need approximately 1000 + O(log k) samples. This is a simplification of the original result; for example, if p = 5000 and 500 features are irrelevant, assuming the simplest case, we need about 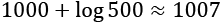 data points.
data points.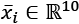 with only five informative features:
with only five informative features: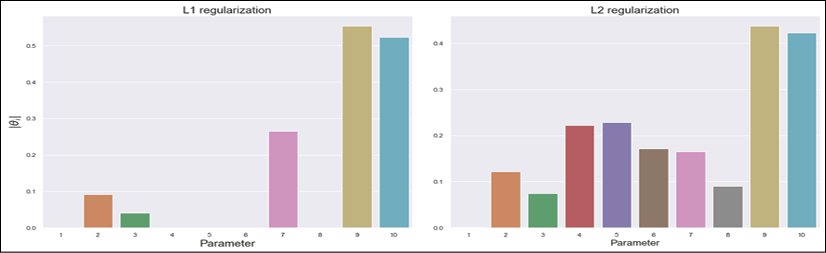
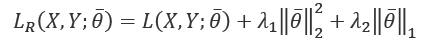
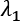 and
and 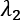 . ElasticNet can yield excellent results whenever it's necessary to mitigate overfitting effects, while encouraging sparsity. We're going to apply all these regularization techniques when we discuss deep learning architectures.
. ElasticNet can yield excellent results whenever it's necessary to mitigate overfitting effects, while encouraging sparsity. We're going to apply all these regularization techniques when we discuss deep learning architectures.