

Just imagine that we are entering a hypermarket to purchase a few grocery items, which we have already noted on a piece of paper. It's a multistorey store. Being a hypermarket, it has almost all the products, such as grocery items, home appliances, electronics, footwear, and lifestyle items. Since our intention is to purchase grocery items, we start with olive oil, and we find it located on the first floor, but the cookware is not available on the same floor; it's available on the top floor (let's say the tenth floor). After dragging ourselves from the bottom floor to the top floor, we find that we were especially looking to buy a microwave oven, but guess what? It is available on the fifth floor. So we are thinking of getting the elevator and going to the fifth floor. In spite of the badly-arranged items (not only with grocery items), almost all the people are using the elevator, because of which we couldn't purchase the microwave oven (along with some other items). So it's a loss of money for the store as well as a waste of time for the customers.
We are entering another hypermarket, that has all the grocery items placed on the first floor. Along with the items noted on the paper, we are purchasing a few more items that we missed out while writing. In this way both the customer and the store will benefit. Which store will you choose to shop in the next time? If you say that I love the first store and I will always choose to purchase items only from that store, then please read Chapter 4, Working with Secondary Indexes, which covers the usage of secondary index.
So you can call a store or hypermarket perfectly managed only if it helps the customer complete his/her purchase easily. This can be done by organizing the items properly. Similarly you can call a database properly managed only if the elements or items are organized in such a way that it allows easy and fast retrieval of items in the table (in NoSQL, we don't care much about insertion speed, since the data is read multiple times when it is written or updated).
Indexes make retrieval much faster and minimize your billing in many ways. We are going to discuss a few secondary index basics here, and a much more detailed discussion will continue in Chapter 4, Working with Secondary Indexes.
Do you know that whenever you create a DynamoDB table, an index is also created? That index is called as primary index. This primary index will include the primary key attributes (both hash and range keys). The index created over a hash key is an unordered hash index. What it means is that the items with the same hash key will be grouped together and placed adjacent to each other, which helps in faster retrieval of items with the same hash key attributes (using the scan operation), but there will not be any ordering in the item on the hash key attribute.
Just for illustration purposes, let's go back to the Tbl_Book table:

Here, you can see that the items with the same BookTitle attribute (which is the hash key attribute) are placed adjacent to each other, because as soon as the table is created, this index will be created, and whenever an insertion takes place it will hash this attribute using some hash logic and place it in the correct location. If you look at the ASCII code or the English alphabetical order, L as in Let us C comes before S as in SCJP. Since the index created on the hash key is unordered, the items will not be sorted on this attribute.
Another noticeable concept is the index created on the Author#Edition attribute (which is the range key attribute); it works deeper on the tree created by the hash key index. This index will order the items that have the same hash key (but of course with different range key values) either in descending or ascending order. To put it in RDBMS terms, the hash key index will perform GROUP BY and the range key index will perform the ORDER BY action.
Primary indexes are created by DynamoDB by default. Along with those indexes, the user can create up to five secondary indexes for a table. There are two kinds of secondary indexes:
In both of these secondary index types, the range key can be a field, which the user needs to create the index for.
In the case of the local secondary index, the grouping will always take place on the hash key attribute, whereas the ordering takes place on the nonprimary key attribute. A quick question: in DynamoDB, except for primary key attributes, all other attributes are optional for an item. So where do these index attributes fall, in optional attributes or mandatory attributes? The answer is that local secondary index attributes are also optional attributes. If an item does not include this attribute, then that item will not be indexed, it's as simple as that.
We will take a look at an example in the following table:
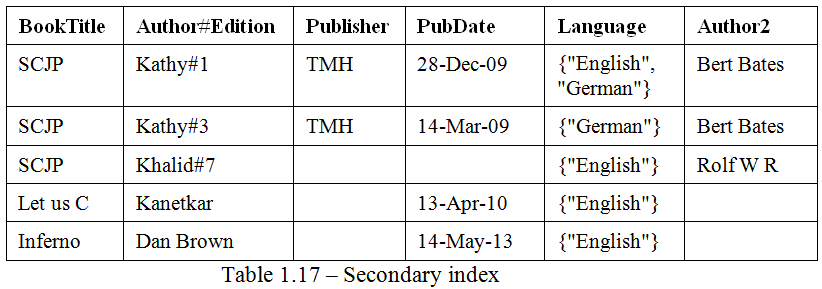
Let's say that we are creating a local secondary index on the PubDate attribute. Let's name this index Idx_PubDate. The index will look as shown in the next table. This is the smallest local secondary index we can create (we are not going to discuss projections yet. We will discuss them in Chapter 4, Working with Secondary Indexes). Take a look at the following table:

You will quickly notice that the third item did not have the secondary index attribute, so that item is not available in the index. One more change is that the index is sorted on the PubDate attribute, so the first item became the second item.
In the case of the local secondary index, there is a restriction that the hash key of the table must be the hash key of the index too. In order to overcome this, we can also specify the user-defined (non-primary key attribute) attribute as the hash key attribute of the secondary index. Then this index will be called the global secondary index.
Let's take a scenario in which we need to count the number of unique languages a publisher has published the book in. In this case, the publisher name will become the GROUP BY column (index hash key) and the Language column will become the ORDER BY column (index range key). Take a look at the following tables:

In this case, the item will be put into the index only if both the attributes of the index are available in the item. That is the reason why two items are not available in the global secondary index.