-
Book Overview & Buying

-
Table Of Contents

Build Your Own Programming Language - Second Edition
By :
Build Your Own Programming Language
By:
Overview of this book
There are many reasons to build a programming language: out of necessity, as a learning exercise, or just for fun. Whatever your reasons, this book gives you the tools to succeed.
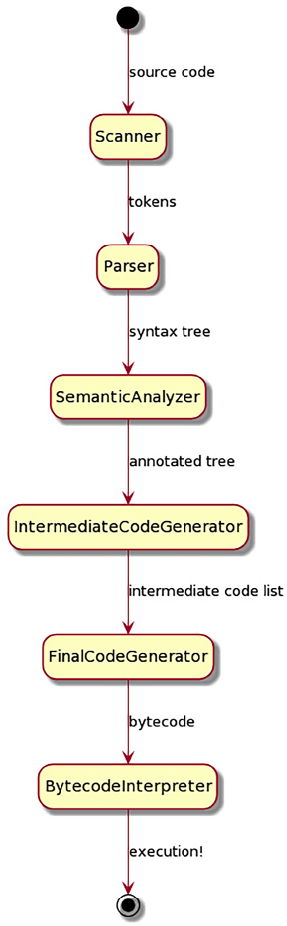
You’ll build the frontend of a compiler for your language and generate a lexical analyzer and parser using Lex and YACC tools. Then you’ll explore a series of syntax tree traversals before looking at code generation for a bytecode virtual machine or native code. In this edition, a new chapter has been added to assist you in comprehending the nuances and distinctions between preprocessors and transpilers. Code examples have been modernized, expanded, and rigorously tested, and all content has undergone thorough refreshing. You’ll learn to implement code generation techniques using practical examples, including the Unicon Preprocessor and transpiling Jzero code to Unicon. You'll move to domain-specific language features and learn to create them as built-in operators and functions. You’ll also cover garbage collection.
Dr. Jeffery’s experiences building the Unicon language are used to add context to the concepts, and relevant examples are provided in both Unicon and Java so that you can follow along in your language of choice.
By the end of this book, you'll be able to build and deploy your own domain-specific language.
Table of Contents (27 chapters)
Preface

Section I: Programming Language Frontends
 Free Chapter
Free Chapter
Why Build Another Programming Language?
Programming Language Design
Scanning Source Code
Parsing
Syntax Trees
Section II: Syntax Tree Traversals
Symbol Tables
Checking Base Types
Checking Types on Arrays, Method Calls, and Structure Accesses
Intermediate Code Generation
Syntax Coloring in an IDE
Section III: Code Generation and Runtime Systems
Preprocessors and Transpilers
Bytecode Interpreters
Generating Bytecode
Native Code Generation
Implementing Operators and Built-In Functions
Domain Control Structures
Garbage Collection
Final Thoughts
Section IV: Appendix
Answers
Other Books You May Enjoy
Index