

Understanding data ingestion
Before learning how data ingestion works with ADX, let's revisit the different types of data:
- Structured data: When we think of structured data, we think of relational databases that are made up of tables consisting of rows and columns. Each column has a data type such as an integer or string, and it sometimes includes additional constraints such as fixed-length strings and strings with specific formats such as a postcode.
- Semi-structured: When we think of semi-structured data, we think of JSON and XML. They have a structure defined with tags, but the format is typically less rigid than relational databases.
- Unstructured data: Unstructured data is data that has no constraints, such as SMS messages, text files, and emails, and social media such as status posts, messages, and images.
As shown in Figure 4.1, ADX supports four categories of services that enable data ingestion:
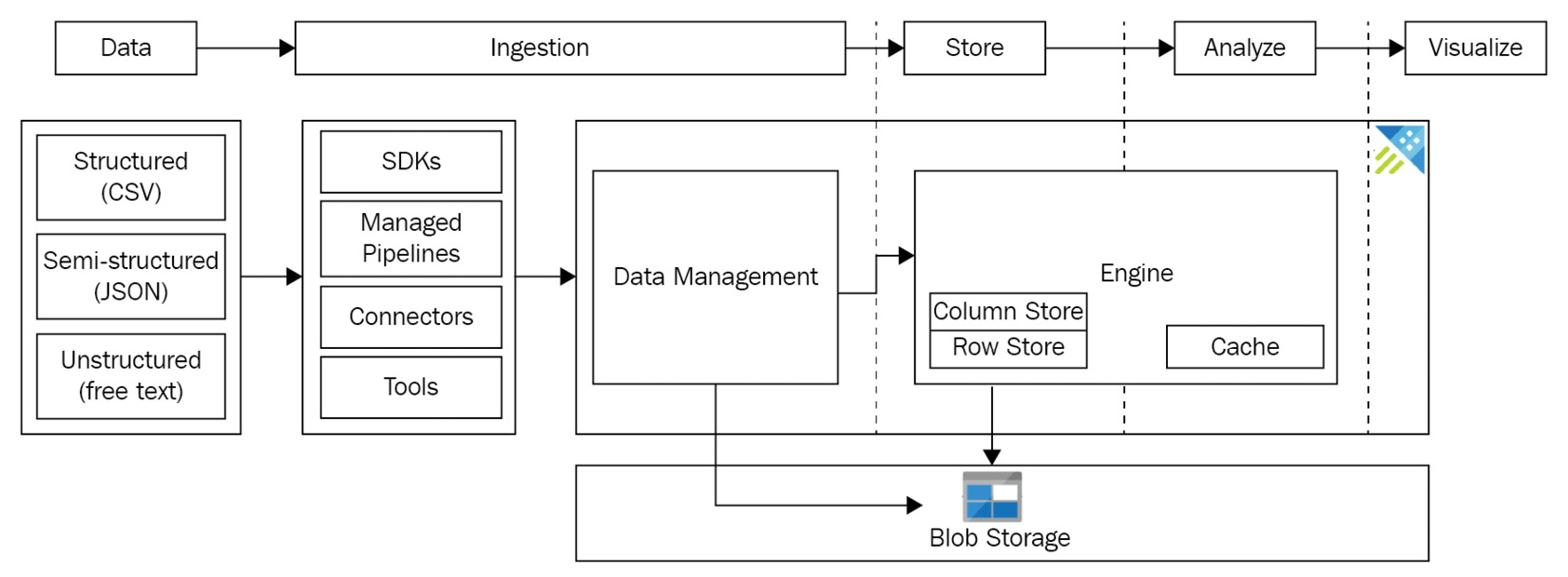
Figure 4.1 – Data...