Stages of the programmable pipeline
All Direct3D operations take place via one of the two pipelines, known as pipelines for the fact that information flows in one direction from one stage to the next. For all drawing operations, the graphics pipeline is used (also known as drawing pipeline or rendering pipeline). To run compute shaders, the dispatch pipeline is used (aka DirectCompute pipeline or compute shader pipeline).
Although these two pipelines are conceptually separate. They cannot be active at the same time. Context switching between the two pipelines also incurs additional overhead so each pipeline should be used in blocks—for example, run any compute shaders to prepare data, perform all rendering, and finally post processing.
Methods related to stages of the pipeline are found on the device context. For the managed API, each stage is grouped into a property named after the pipeline stage. For example, for the vertex shader stage, deviceContext.VertexShader.SetShaderResources, whereas the unmanaged API groups the methods by a stage acronym directly on the device context, for example, deviceContext->VSSetShaderResources, where VS represents the vertex shader stage.
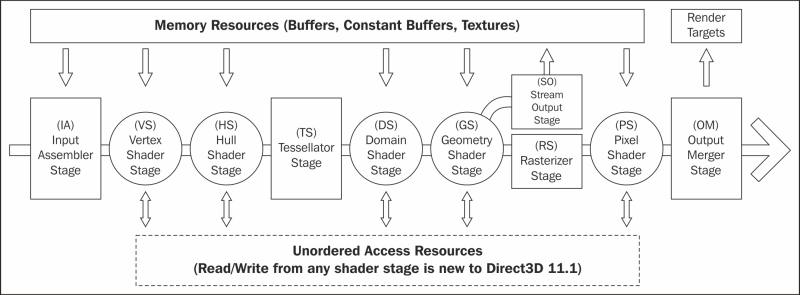
The graphics pipeline is comprised of nine distinct stages that are generally used to create 2D raster representations of 3D scenes, that is, take our 3D model and turn it into what we see on the display. Four of these stages are fixed function and the remaining five programmable stages are called shaders (the following diagram shows the programmable stages as a circle). The output of each stage is taken as input into the next along with bound resources or in the case of the last stage, Output Merger (OM), the output is sent to one or more render targets. Not all of the stages are mandatory and keeping the number of stages involved to a minimum will generally result in faster rendering.
Optional tessellation support is provided by the three tessellation stages (two programmable and one fixed function): the hull shader, tessellator, and domain shader. The tessellation stages require a Direct3D feature level of 11.0 or later.
As of Direct3D 11.1, each programmable stage is able to read/write to an Unordered Access View (UAV). A UAV is a view of a buffer or texture resource that has been created with the BindFlags.UnorderedAccess flag (D3D11_BIND_UNORDERED_ACCESS from the D3D11_BIND_FLAG enumeration).
Input Assembler (IA) stage
The IA stage reads primitive data (points, lines, and/or triangles) from buffers and assembles them into primitives for use in subsequent stages.
Usually one or more vertex buffers, and optionally an index buffer, are provided as input. An input layout tells the input assembler what structure to expect the vertex buffer in.
The vertex buffer itself is also optional, where a vertex shader only has a vertex ID as input (using the SV_VertexID shader system value input semantic) and then can either generate the vertex data procedurally or retrieve it from a resource using the vertex ID as an index. In this instance, the input assembler is not provided with an input layout or vertex buffer, and simply receives the number of vertices that will be drawn. For more information, see http://msdn.microsoft.com/en-us/library/windows/desktop/bb232912(v=vs.85).aspx.
Device context commands that act upon the input assembler directly are found on the DeviceContext.InputAssembler property, for example, DeviceContext.InputAssembler.SetVertexBuffers, or for unmanaged begin with IA, for example, ID3D11DeviceContext::IASetVertexBuffers.
The vertex shader allows per-vertex operations to be performed upon the vertices provided by the input assembler. Operations include manipulating per-vertex properties such as position, color, texture coordinate, and a vertex's normal.
A vertex can be comprised of up to sixteen 32-bit vectors (up to four components each). A minimal vertex usually consists of position, color, and the normal vector. In order to support larger sets of data or as an alternative to using a vertex buffer, the vertex shader can also retrieve data from a texture or UAV.
A vertex shader is required; even if no transform is needed, a shader must be provided that simply returns vertices without modifications.
Device context commands that are used to control the vertex shader stage are grouped within the DeviceContext.VertexShader property or for unmanaged begin with VS, for example, DeviceContext.VertexShader.SetShaderResources and ID3D11DeviceContext::VSSetShaderResources, respectively.
The hull shader is the first stage of the three optional stages that together support hardware accelerated tessellation. The hull shader outputs control points and patches constant data that controls the fixed function tessellator stage. The shader also performs culling by excluding patches that do not require tessellation (by applying a tessellation factor of zero).
Unlike other shaders, the hull shader consists of two HLSL functions: the patch constant function, and hull shader function.
This shader stage requires that the IA stage has one of the patch list topologies set as its active primitive topology (for example, SharpDX.Direct3D.PrimitiveTopology.PatchListWith3ControlPoints for managed and D3D11_PRIMITIVE_TOPOLOGY_3_CONTROL_POINT_PATCHLIST for unmanaged).
Device context commands that control the hull shader stage are grouped within the DeviceContext.HullShader property or for unmanaged device begin with HS.
The tessellator stage is the second stage of the optional tessellation stages. This fixed function stage subdivides a quad, triangle, or line into smaller objects. The tessellation factor and type of division is controlled by the output of the hull shader stage.
Unlike all other fixed function stages the tessellator stage does not include any direct method of controlling its state. All required information is provided within the output of the hull shader stage and implied through the choice of primitive topology and configuration of the hull and domain shaders.
The domain shader is the third and final stage of the optional tessellation stages. This programmable stage calculates the final vertex position of a subdivided point generated during tessellation.
The types of operations that take place within this shader stage are often fairly similar to a vertex shader when not using the tessellation stages.
Device context commands that control the domain shader stage are grouped by the DeviceContext.DomainShader property, or for unmanaged begin with DS.
Geometry Shader (GS) stage
The optional geometry shader stage runs shader code that takes an entire primitive or primitive with adjacency as input. The shader is able to generate new vertices on output (triangle strip, line strip, or point list).
Note
The geometry shader stage is unique in that its output can go to the rasterizer stage and/or be sent to a vertex buffer via the stream output stage (SO).
It is critical for performance that the amount of data sent into and out of the geometry shader is kept to a minimum. The geometry shader stage has the potential to slow down the rendering performance quite significantly.
Uses of the geometry shader might include rendering multiple faces of environment maps in a single pass (refer to Chapter 9, Rendering on Multiple Threads and Deferred Contexts), and point sprites/billboarding (commonly used in particle systems). Prior to Direct3D 11, the geometry shader could be used to implement tessellation.
Device context commands that control the geometry shader stages are grouped in the GeometryShader property, or for unmanaged begin with GS.
The stream output stage is an optional fixed function stage that is used to output geometry from the geometry shader into vertex buffers for re-use or further processing in another pass through the pipeline.
There are only two commands on the device context that control the stream output stage found on the StreamOutput property of the device content: GetTargets and SetTargets (unmanaged SOGetTargets and SOSetTargets).
The rasterizer stage is a fixed function stage that converts the vector graphics (points, lines, and triangles) into raster graphics (pixels). This stage performs view frustum clipping, back-face culling, early depth/stencil tests, perspective divide (to convert our vertices from clip-space coordinates to normalized device coordinates), and maps vertices to the viewport. If a pixel shader is specified, this will be called by the rasterizer for each pixel, with the result of interpolating per-vertex values across each primitive passed as the pixel shader input.
There are additional interpolation modifiers that can be applied to the pixel shader input structure that tell the rasterizer stage the method of interpolation that should be used for each property (for more information see Interpolation Modifiers introduced in Shader Model 4 on MSDN at http://msdn.microsoft.com/en-us/library/windows/desktop/bb509668(v=vs.85).aspx#Remarks).
When using multisampling, the rasterizer stage can provide an additional coverage mask to the pixel shader that indicates which samples are covered by the pixel. This is provided within the SV_Coverage system-value input semantic. If the pixel shader specifies the SV_SampleIndex input semantic, instead of being called once per pixel by the rasterizer, it will be called once per sample per pixel (that is, a 4xMSAA render target would result in four calls to the pixel shader for each pixel).
Device context commands that control the rasterizer stage state are grouped in the Rasterizer property of the device context or for unmanaged begin with RS.
The final programmable stage is the pixel shader. This stage executes a shader program that performs per-pixel operations to determine the final color of each pixel. Operations that take place here include per-pixel lighting and post processing.
Device context commands that control the pixel shader stage are grouped by the PixelShader property or begin with PS for the unmanaged API.
The final stage of the graphics pipeline is the output merger stage. This fixed function stage generates the final rendered pixel color. You can bind a depth-stencil state to control z-buffering, and bind a blend state to control blending of pixel shader output with the render target.
Device context commands that control the state of the output merger stage are grouped by the OutputMerger property or for unmanaged begin with OM.
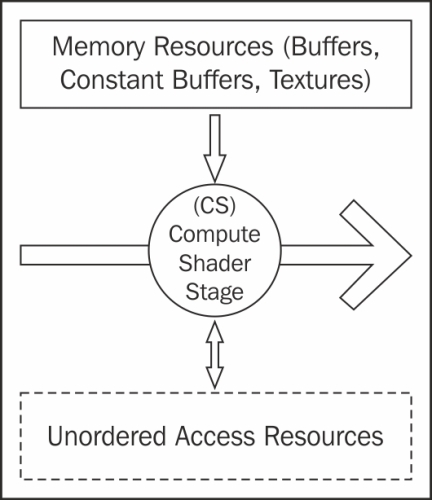
The dispatch pipeline is where compute shaders are executed. There is only one stage in this pipeline, the compute shader stage. The dispatch pipeline and graphics pipeline cannot run at the same time and there is an additional context change cost when switching between the two, therefore calls to the dispatch pipeline should be grouped together where possible.
Compute Shader (CS) stage
The compute shader (also known as DirectCompute) is an optional programmable stage that executes a shader program upon multiple threads, optionally passing in a dispatch thread identifier (SV_DispatchThreadID) and up to three thread group identifier values as input (SV_GroupIndex, SV_GroupID, and SV_GroupThreadID). This shader supports a whole range of uses including post processing, physics simulation, AI, and GPGPU tasks.
Compute shader support is mandatory for hardware devices from feature level 11_0 onwards, and optionally available on hardware for feature levels 10_0 and 10_1.
The thread identifier is generally used as an index into a resource to perform an operation. The same shader program is run upon many thousands of threads at the same time, usually with each reading and/or writing to an element of a UAV resource.
Device context commands that control the compute shader stage are grouped in the ComputeShader property or begin with CS in the unmanaged API.
After the compute shader is prepared, it is executed by calling the Dispatch command on the device context, passing in the number of thread groups to use.






 Free Chapter
Free Chapter