

The opportunities and future directions for DBMSs
Let's review the opportunities, as well as future directions, that DBMSs are headed in. In the next few subsections, you will encounter topics ranging from database security to industry novelties such as DBaaS.
Database safety
Database safety has been one of the key focus areas for DBMSs. On the one hand, database vendors strive to deliver and iterate on existing solutions to solve database issues.
Cloud vendors are committed to protecting the data and applications that exist in the cloud infrastructure. The internet, software, load balancers, and all the components of the data transmission flow are seeing their safety measures being upgraded one by one.
Considering this ongoing improvement process, the natural question that arises is this: how can we achieve the seamless integration that's needed between the projects that are developed in different languages and various databases?
To answer this question and the necessary challenges that come with dealing with such important questions, we are seeing an increasingly significant number of resources being dedicated to both leading enterprises and promising new start-up ventures.
More than two-thirds of CIOs are concerned about the constraints that could emerge because of cloud providers. It is for these reasons that open source databases are becoming the go-to solution.
Data security has not only become paramount for enterprises but can be the determinant between survival or being forgotten forever as another firm that went out of business. If you think about ransomware and how it is increasingly widespread, you may be able to understand how open source technology empowers organizations to defend themselves against such risks. Open source allows organizations to be in total control of their security needs by giving them complete access to source code, as well as the flexibility that comes with being able to configure and extend the software as they see fit.
There is certainly a counter-argument to the criticism about the security of open source that was prevalent years ago. Rapid adoption by enterprises seems to be settling the argument in favor of open source. No company will remain untouched by the power of open source database progress.
SQL, NoSQL, and NewSQL
When SQL is brought up in a conversation, people immediately think about the good old relational database, which has been supporting higher-level services for the past couple of decades.
Unfortunately, the relational database has since started to show its age and is now considered by many as not adequate to meet the new requirements that businesses must nowadays respond to. This has caused industry giants in the database field to take aggressive actions to reshape their product offerings or deliver new solutions.
NoSQL is one such example. It was the initiator of the non-relational database, which provides a mechanism for storing and retrieving data modeled in a non-relational fashion, such as key-value pairs, graphs, documents, or wide columns. Nevertheless, many NoSQL products compromise consistency in favor of availability and partition tolerance. Without transaction and SQL's standard advantages, NoSQL databases gain the high availability and elastic scale-out that's necessary to respond to the vital concerns of the new era. The success of Couchbase, HBase, MongoDB, and others all stand as clear evidence in support of this thesis. NoSQL databases also sometimes emphasize that they are Not Only SQL and that they do recognize the value of the traditional SQL database. This type of appreciation has led to NoSQL databases gradually adopting some of the benefits of mainstream SQL products.
NewSQL can be defined as a type of relational database management system (RDBMS) looking to make NoSQL systems scalable for online transaction processing (OLTP) tasks, all while keeping the ACID qualities of a traditional database system.
The discussion is still ongoing both in academia and in the industry, with the definition being regarded as fluid and evolving. An excellent resource is the paper What's Really New with NewSQL? (https://dl.acm.org/doi/10.1145/3003665.3003674https://dl.acm.org/doi/10.1145/3003665.3003674), which set out to categorize the databases according to their architecture and functions.
All the databases shouting out they are one of the NewSQL products are seeking a nice balance between capability, availability, and partition tolerance (CAP theorem). But which products belong to NewSQL?
New architecture
Among the opportunities for DBMSs that are currently available and stated to bring significant changes to the industry in the short to medium term, new database architectures certainly merit consideration. This is where databases are effectively designed from an entirely new code base, thus leaving behind any of the architectural baggage of legacy systems – a clean slate of sorts that allows for near endless possibilities, as new databases are being conceptualized and built to meet the needs of the new era.
Embracing a transparent sharding middleware
A transparent sharding middleware splits a database into multiple shards that are stored across a cluster of a single-node DBMS instance, just as Apache ShardingSphere does. Sharding middleware exists to allow a user – or in this case, an organization – to split a database into multiple shards to be stored across multiple single-node DBMS instances, such as Apache ShardingSphere. This section will help you understand what data sharding is. Database administrators are constantly looking for ways to optimize their database management systems. When data input spikes, you must have strategies in place to handle it. One of the best techniques for this is to split the data into separate rows and columns, and such examples include data sharding or partitioning. The following sections will introduce you to, or refresh, these concepts and the difference between them.
Data sharding
When a large database table is split into multiple small tables, shards are created. The newly created tables are called shards or partitions. These shards are stored across multiple nodes to work efficiently, improving scalability and performance. This type of scalability is known as horizontal scalability. Sharding eventually helps database administrators such as yourself utilize computing resources in the most efficient way possible and is collectively known as database optimization.
Optimizing computing resources is one key benefit. More critical is that the network can scan fewer rows and respond to queries on the user side much faster than going through one colossal database.
Data partitioning
When we talk about partitioning, it may sound confusing. The reason for your potential confusion is completely normal as data partitioning is often mistakenly thought about when it comes to data sharding.
Partitioning refers to a database that has been broken down into different subsets but is still stored within a single database. This single database is sometimes referred to as the database instance. So what is the difference between sharding and partitioning? Both sharding and partitioning include breaking large data sets into smaller ones. But a key difference is that sharding implies that the breakdown of data is spread across multiple computers, either as horizontal partitioning or vertical.
Database-as-a-Service
The DBaaS providers not only provide the remodeled cloud databases but are responsible for maintaining their physical configuration as well. Users do not need to care about where the database is located; the cloud allows the cloud database providers to take care of the physical databases' maintenance and related operations.
NoSQL and NewSQL are unavoidable opportunities, towards which most if not all database vendors are moving and represent the future of DBMSs. Many startups are moving into this space to fill this market gap and deliver services that directly complete with the ones provided by established industry giants.
AI database management platform
The technological developments of the last 10 years are allowing advances in nascent fields such as machine learning (ML) and artificial intelligence (AI). Such technologies will eventually impact all aspects of our lives, and enterprises and their databases are no different.
AI database operation and maintenance are poised to become the main growth drivers for the future of DBMSs. The relationship between AI and databases may not seem to be evident at first; while AI has become a sort of buzzword these days, database management has remained automatic, platform-based, and observed while requiring intensive human interaction.
When AI technology is eventually integrated into databases' operation and maintenance work, new avenues will be opened. The historical experience of the previous operations that were performed during database management tasks will be machine-learned, and databases empowered by AI will be able to provide suggestions and specific actions to manage, operate, maintain, and protect database clusters.
Furthermore, AI database management platforms will also be able to contact the monitoring and warning system, or even undertake some pressing operations to avoid significant production accidents. Productivity improvement and headcount optimization reduction are always central concerns of enterprises.
Database migration
When it comes to database migration, there is some good news and some bad news. In the spirit of optimism about the future, let's consider the good news first: we have new database candidates, such as all the NewSQL and NoSQL offerings that have hit the market recently.
When it comes to the bad news, it'll be necessary to be able to deliver data migration at the lowest price.
In this old-to-new process, data migration and database selection occupy an important part of peoples' minds. Many enterprises choose to stick with stale database architecture to avoid any negative effect on production and the instability that could be caused by new databases.
Additionally, legacy and complicated IT systems contribute significantly to discouraging risk-taking, and confidence in performing data migration. In such cases, many database vendors or database service companies will offer to develop new products for this bulky work and insert themselves into this market to get a piece of the billion dollars' worth pie that is the database industry.
To recap, some of the main opportunities for DBMSs in the future include database security, leveraging new database architectures, considering embracing data sharding or DBaaS, and fully mastering database migration.
Before moving on to the next section, there is one last thing you have probably already thought of at some point in your career. There are still concerns during this old-to-new-database transition period, such as the following:
- On-premises versus the cloud
- The lowest cost to migrate data to new databases
- Increased program refactoring work costs caused by using multiple databases
The following diagram illustrates an example of the costs that may be incurred while transitioning from an old to a new database:
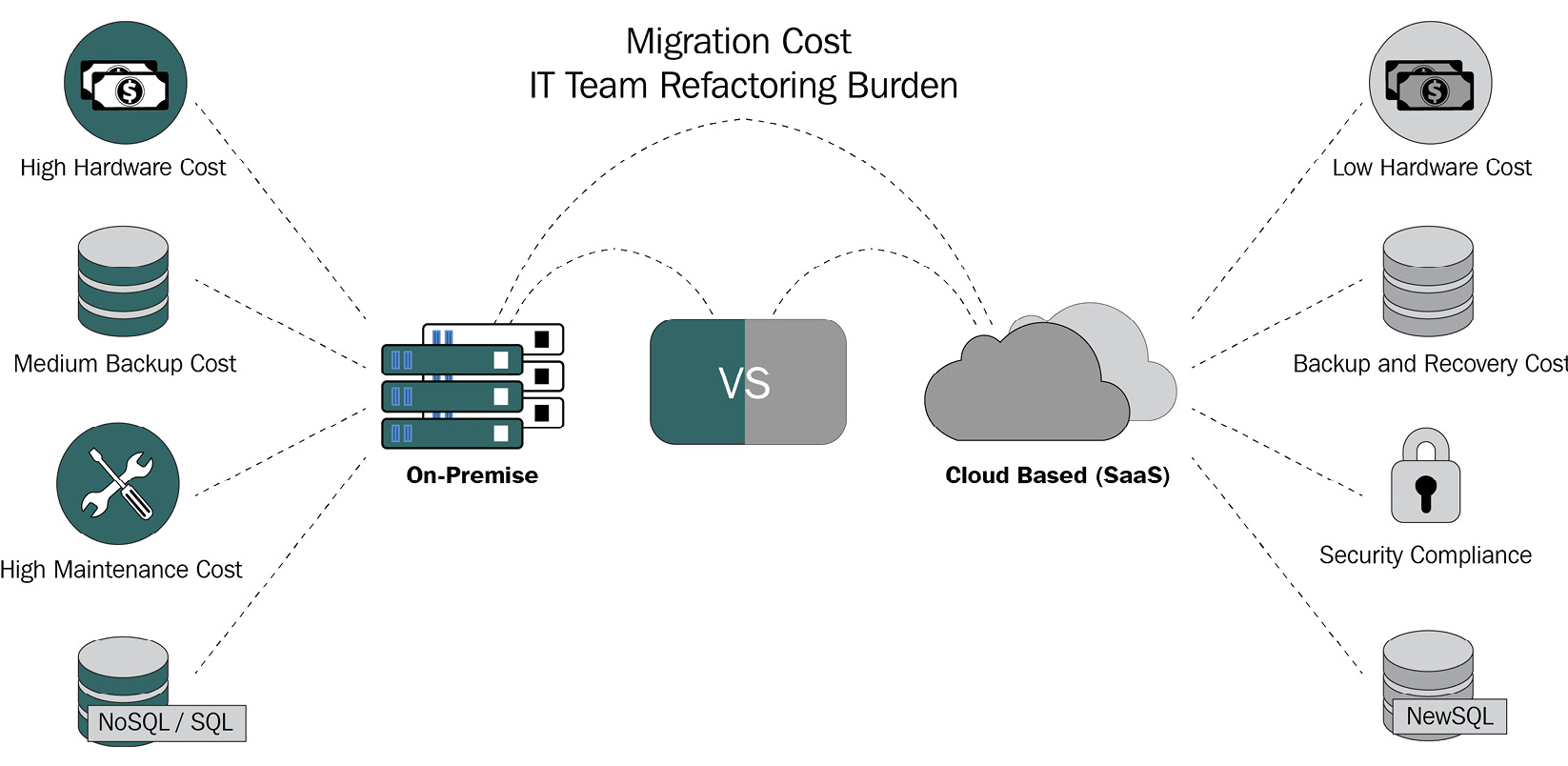
Figure 1.2 – Old-to-new database transition cost
Solving these challenges is not a small feat by any means. There is a multitude of tools and ways that you or an enterprise could employ. The truth is that for most of these solutions, you'd be expected to spend considerable amounts of time and financial resources to succeed as they'd require completely switching database type or vendor, reconfiguring your whole system, or worse, developing custom patches for the databases. Let's not forget that all of these involve risks, such as losing all of your data in the process.
It is for these reasons that we have thought of Apache ShardingSphere. It has been built to be as flexible and unintrusive as possible to make your life easier. You could set it up quickly without having to disturb anything in your system, answer all of the previously mentioned challenges, and set yourself up to be ready for the future developments mentioned in this chapter as well. The next section will give you an introductory overview of what Apache ShardingSphere is and its main concept.