

Understanding Apache ShardingSphere
A unified data service platform is the best solution to the bottleneck issues of a peer-to-peer data service model. Apache ShardingSphere is an independent database middleware platform with a supportive ecosystem, positioned as Database Plus, to build a criterion and ecosystem above multi-model databases. The three key elements of Apache ShardingSphere are connect, enhance, and pluggable. We will discuss these concepts in detail in the following sections.
Connect
The basic feature of Apache ShardingSphere is to make it incredibly easy to connect data and applications. Instead of creating a new API to build an entirely new database standard, it chooses to pursue compatibility with existing databases, making you feel as if nothing has changed in your interaction with and among the various original databases.
Its unified database access entry, known as database gateway, enables Apache ShardingSphere to simulate target databases and transparently access databases and their peripheral ecosystems, such as application SDKs, command-line tools, GUIs, monitoring systems, and more. ShardingSphere currently supports many types of database protocols, including MySQL and PostgreSQL protocols.
Connect refers to ShardingSphere's strong database compatibility – that is, building a database-independent connection between data and applications to greatly improve enhanced features.
Enhance
To only connect without including additional service features can already be considered an implementation plan – good or bad as it may be. The result would, in nature, be equivalent to directly connecting databases. Such a plan not only increases network costs but damages performance as well, not to mention the low value you'd get from it.
The primary feature of Apache ShardingSphere is to capture database access entry and provide additional features transparently, such as redirect (sharding, read/write splitting, and shadow databases), transform (data encrypting and masking), authentication (security, auditing, and authority), and governance (circuit breaker, access limitation and analysis, QoS, and observability).
The ongoing trend of database fragmentation makes it impossible to centralize the management of all database features. The additional features of Apache ShardingSphere neither target a single database, nor make up for the shortages of database features; instead, they get rid of the shackle of databases simply serving as storage and give unified services that answer DBMSs' concerns.
Pluggable
The progressive addition of new features has expanded Apache ShardingSphere throughout its development history. To avoid creating a steep learning curve that could discourage prospective new users and developers from integrating Apache ShardingSphere into their database environment, Apache ShardingSphere chose to pursue and ultimately adopt a fully pluggable architecture.
The core value of the ShardingSphere project is not the number of different database access and functions, but its developer-oriented and highly extensible pluggable architecture.
As a developer, you are allowed to create custom features without having to modify the source code of Apache ShardingSphere.
The pluggable architecture of Apache ShardingSphere adopts a microkernel and a three-layer pluggable mode. Apache ShardingSphere's architecture is directed toward top-level APIs, so the kernel cannot be aware of the existence of specific functions. If you don't need a function, all you have to do is delete the dependency – it'll have zero impact on the system.
The following diagram shows how ShardingSphere is built:
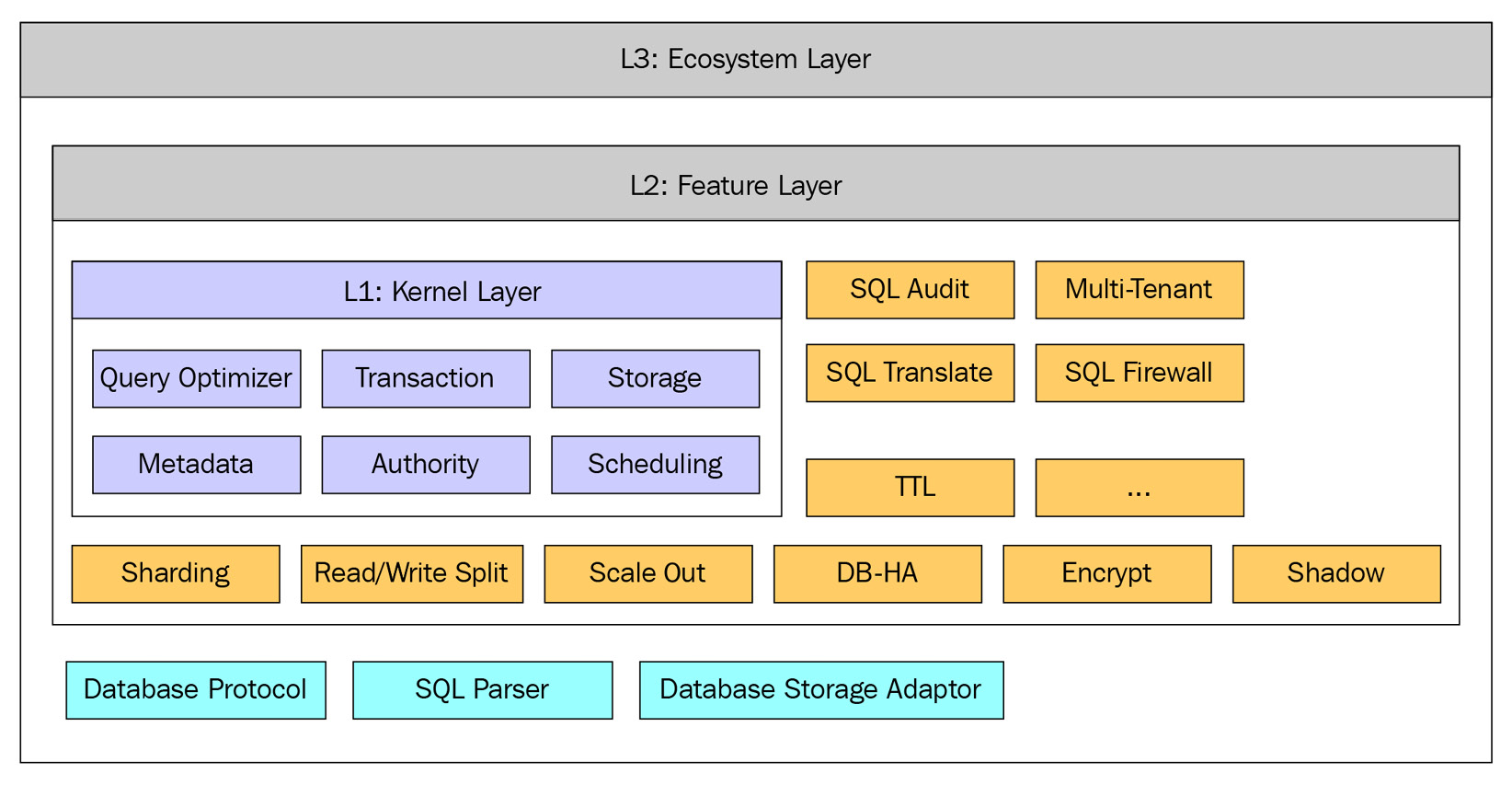
Figure 1.3 – The Apache ShardingSphere ecosystem
As you can see, the three layers are fully independent. Being focused on a plugin-oriented design means that the kernel and feature components fully support ShardingSphere's extensibility, allowing you to build a ShardingSphere instance without it affecting your overall experience if you were to drop (choose to not install) some feature modules, for example.
The architectural possibilities at your disposal
Database middleware requires two things: a driver to access the database and an independent proxy. Since no adaptor of an architecture model is flawless, Apache ShardingSphere chose to develop multiple adaptors.
ShardingSphere-JDBC and ShardingSphere-Proxy are two independent products, but you can choose what we interchangeably refer to as the hybrid model or mixed deployment, and deploy them together. They both provide dozens of enhanced features that see databases as storage nodes that apply to scenarios such as Java isomorphism, heterogeneous languages, cloud-native, and more.
ShardingSphere-JDBC
Being the predecessor and eventually the first client of the Apache ShardingSphere ecosystem, ShardingSphere-JDBC is a lightweight Java framework that provides extra services at the Java JDBC layer. ShardingSphere-JDBC's flexibility will be very helpful to you for the following reasons:
- It applies to any ORM framework based on JDBC, such as JPA, Hibernate, Mybatis, and Spring JDBC Template. It can also be used directly with JDBC.
- It supports any third-party database connection pool, such as DBCP, C3P0, BoneCP, and HikariCP.
- It supports any database that meets JDBC's standards. Currently, ShardingSphere JDBC supports MySQL, PostgreSQL, Oracle, SQLServer, and any other databases that support JDBC access.
You have probably recognized many of the databases and ORM frameworks mentioned in the previous list, but what about ShardingSphere-Proxy's support? The next section will quickly introduce you to the proxy.
ShardingSphere-Proxy
ShardingSphere-Proxy was the second client to join the Apache ShardingSphere ecosystem. A transparent database proxy, ShardingSphere-Proxy provides a database server that encapsulates the database binary protocol to support heterogeneous languages. The proxy is as follows:
- Transparent to applications; it can be used directly as MySQL/PostgreSQL.
- Applicable to any kind of client that is compatible with the MySQL/PostgreSQL protocol.
The following diagram illustrates ShardingSphere-Proxy's topography:
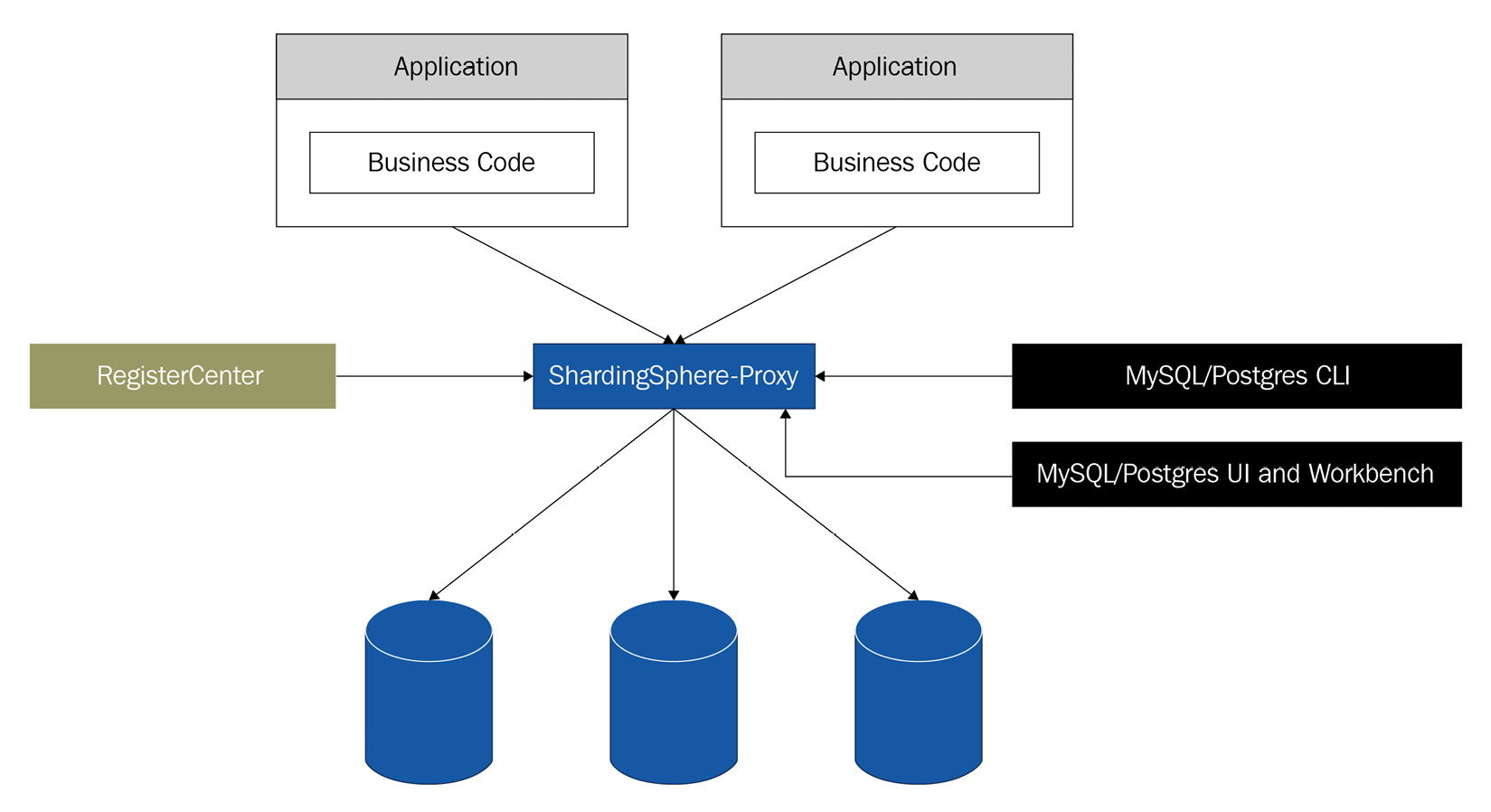
Figure 1.4 – ShardingSphere-Proxy's topography
As you can see, ShardingSphere-Proxy is not intrusive and easily fits into your system, offering you great flexibility.
You may be wondering what the differences between the two clients are and how they compare. The next section will offer you a quick comparison. For a more in-depth comparison, please refer to Chapter 5, Exploring ShardingSphere Adaptors.
Comparing ShardingSphere-JDBC and ShardingSphere-Proxy
If we consider the simple database middleware projects, different access ends mean different deployment structures. But Apache ShardingSphere is the exception: it supports tons of features. So, with the increasing demand for big data computing and resources, different deployment structures have different resource allocation plans.
ShardingSphere-Proxy has a distributed computing module and can be deployed independently. It applies to applications with multidimensional data calculation, which are less sensitive to delay but consume more computing resources. For more details on the comparison between ShardingSphere-JDBC and ShardingSphere-Proxy, please refer to Chapter 5, Exploring ShardingSphere Adaptors, or https://shardingsphere.apache.org/document/current/en/overview/.
Hybrid deployment
Adopting a decentralized architecture, ShardingSphere-JDBC applies to Java-based high-performing and lightweight OLTP applications. On the other hand, ShardingSphere-Proxy provides static entry and comprehensive language support and is suitable for OLAP applications, as well as managing and operating sharding databases.
This results in a ShardingSphere ecosystem that consists of multiple endpoints. Thanks to a unified sharding strategy and the hybrid integration of ShardingSphere-JDBC and ShardingSphere-Proxy, a multi-scenario-compatible application system can be built with ShardingSphere. The following diagram introduces an example topography of a hybrid deployment including both ShardingSphere-JDBC and ShardingSphere-Proxy:
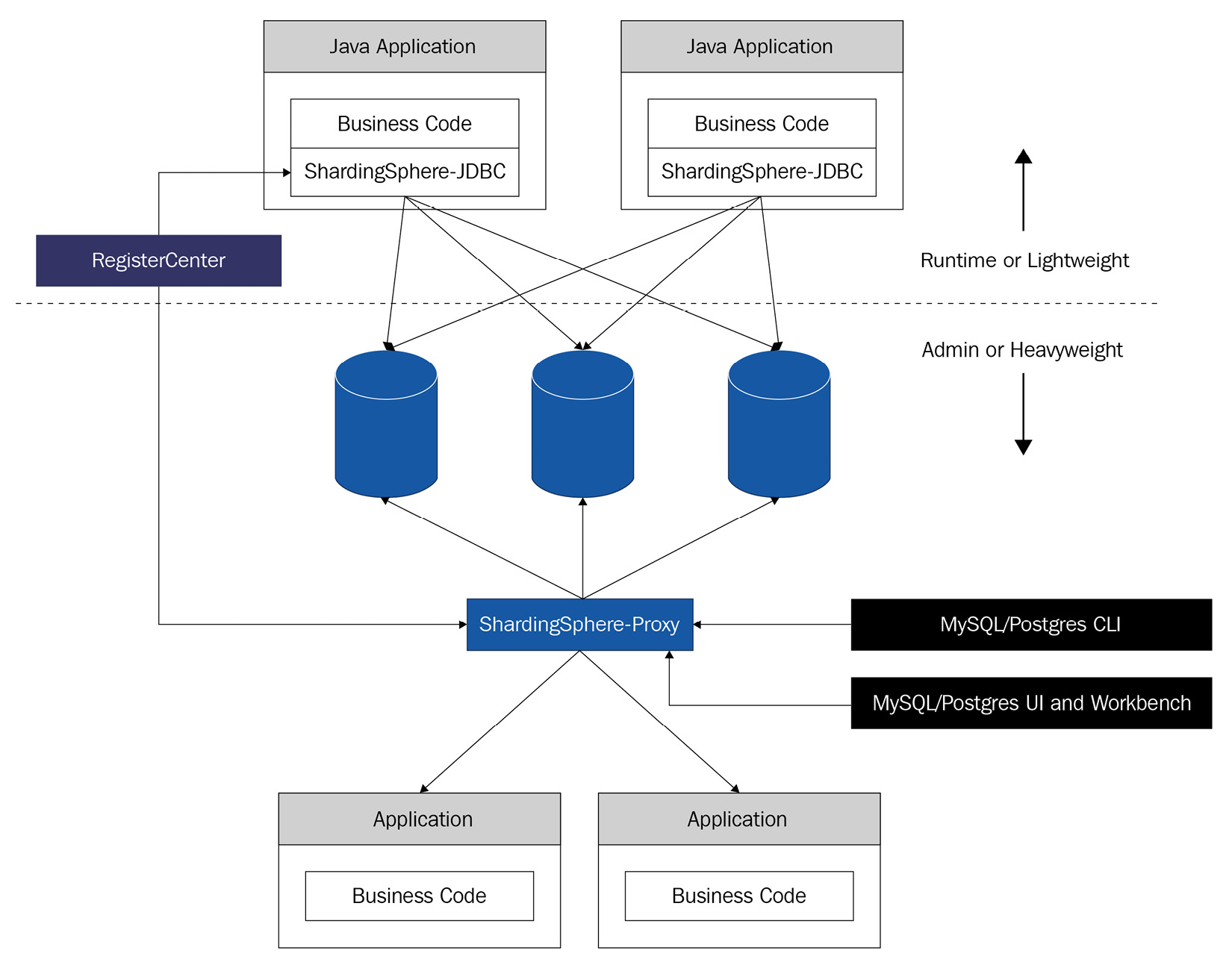
Figure 1.5 – ShardingSphere hybrid deployment topography
When you deploy ShardingSphere-JDBC and ShardingSphere-Proxy together, as shown in the preceding diagram, a hybrid computing capability will be obtained. This allows you to adjust the system architecture to optimally suit your needs.